Часто клиенты просят сделать автоматическую отправку счетов или отчетов на электронную почту, ниже приведены примеры кода для разных версий 1С:
С версиями 8.2 сложнее, так как все почтовые сервисы перешли на SSL, а медоты:
появились только в 8.3.1 , остается использовать stunnel или CDO:
Через stunnel в 1С код, менять не нужно, только установить программу и изменить настройки подключения к почтовому ящику
Скачиваем stunnel c официального сайта (stunnel.org) и запускаем инсталятор, жмем yes при установке спросит страну и ваши данные, это нужно для создания сертификата на вашем компьютере.
После запуска в трее появится его иконка, правой клавишей и редактировать edit configuration
В блокноте откроется файл настроек, там будет пример для gmail дополняем или заменяем его следующим:
Сохраняем файл и делаем Reload configuration
В настройка 1С меняем порты для работы
gmail
pop3 10110
imap 10143
smtp 10025
yandex
pop3 20110
imap 20143
smtp 20025
mail
pop3 30110
imap 30143
smtp 30025
Если в коде прописано, то:
Все, можно отправлять и проверять работу через консоль Show log window в меню
P.S. Почтовый ящик в примерах не рабочий, как пример
Для формирования и выполнения запросов к таблицам базы данных в платформе 1С используется специальный объект языка программирования Запрос. Создается этот объект вызовом конструкции Новый Запрос. Запрос удобно использовать, когда требуется получить сложную выборку данных, сгруппированную и отсортированную необходимым образом. Классический пример применения запроса - получение сводки по состоянию регистра накопления на определенный момент времени. Так же, механизм запросов позволяет легко получать информацию в различных временных разрезах.
Текст запроса – это инструкция, в соответствии с которой должен быть выполнен запрос. В тексте запроса описывается:
таблицы информационной базы, используемые в качестве источников данных запроса;
поля таблиц, которые требуется обрабатывать в запросе;
правила группировки;
сортировки результатов;
и т. д.
Инструкция составляется на специальном языке – языке запросов и состоит из отдельных частей – секций, предложений, ключевых слов, функций, арифметических и логических операторов, комментариев, констант и параметров.
Язык запросов платформы 1С очень похож на синтаксис других SQL-языков, но имеются отличия. Основными преимуществами встроенного языка запросов являются: разыменование полей, наличие виртуальных таблиц, удобная работа с итогами, нетипизированные поля в запросах.
Рекомендации по написанию запросов к базе данных на языке запросов платформы 1С:
1) Текст запроса может содержать предопределенные данные конфигурации, такие как:
значения перечислений;
предопределенные данные:
справочников;
планов видов характеристик;
планов счетов;
планов видов расчетов;
пустые ссылки;
значения точек маршрута бизнес-процессов.
Также текст запроса может содержать значения системных перечислений, которые могут быть присвоены полям в таблицах базы данных: ВидДвиженияНакопления, ВидСчета и ВидДвиженияБухгалтерии. Обращение в запросах к предопределенным данным конфигурации и значениям системных перечислений осуществляется с помощью литерала функционального типа ЗНАЧЕНИЕ. Данный литерал позволяет повысить удобочитаемость запроса и уменьшить количество параметров запроса.
Пример использования литерала ЗНАЧЕНИЕ:
ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.Москва)
ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.ПустаяСсылка)
ГДЕ ТипТовара = ЗНАЧЕНИЕ(Перечисление.ВидыТоваров.Услуга)
ГДЕ ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
ГДЕ ТочкаМаршрута = ЗНАЧЕНИЕ(БизнесПроцесс.БизнесПроцесс1.ТочкаМаршрута.Действие1
2) Использование инструкции АВТОУПОРЯДОЧИВАНИЕ в запросе может сильно время выполнения запроса, поэтому, если сортировка не требуется, то лучше вообще ее не использовать. Во большинстве случаях лучше всего применять сортировку с помощью инструкции УПОРЯДОЧИТЬ ПО.
Автоупорядочивание работает по следующим принципам:
Если в запросе было указано предложение УПОРЯДОЧИТЬ ПО, то каждая ссылка на таблицу, находящаяся в этом предложении, будет заменена полями, по которым по умолчанию сортируется таблица (для справочников это код или наименование, для документов – дата документа). Если поле для упорядочивания ссылается на иерархический справочник, то будет применена иерархическая сортировка по этому справочнику.
Если в запросе отсутствует предложение УПОРЯДОЧИТЬ ПО, но есть предложение ИТОГИ, тогда результат запроса будет упорядочен по полям, присутствующим в предложении ИТОГИ после ключевого слова ПО, в той же последовательности и, в случае если итоги рассчитывались по полям – ссылкам, то по полям сортировки по умолчанию таблиц, на которые были ссылки.
Если в запросе отсутствуют предложения УПОРЯДОЧИТЬ ПО и ИТОГИ, но есть предложение СГРУППИРОВАТЬ ПО, тогда результат запроса будет упорядочен по полям, присутствующим в предложении, в той же последовательности и, в случае если группировка велась по полям – ссылкам, то по полям сортировки по умолчанию таблиц, на которые были ссылки.
В случае же, если в запросе отсутствуют предложения и УПОРЯДОЧИТЬ ПО, ИТОГИ и СГРУППИРОВАТЬ ПО, результат будет упорядочен по полям сортировки по умолчанию для таблиц, из которых выбираются данные, в порядке их появления в запросе.
В случае, если запрос содержит предложение ИТОГИ, каждый уровень итогов упорядочивается отдельно.
3) Что бы избежать повторного запроса к базе данных при выводе результата запроса пользователю (например, построение запроса или отображение результата запроса с помощью табличного документа) полезно использовать инструкцию ПРЕДСТАВЛЕНИЕССЫЛКИ, которая позволяет получать представление ссылочного значения. Пример:
Так же возможно использование инструкции ПРЕДСТАВЛЕНИЕ - предназначена для получения строкового представления значения произвольного типа. Отличие этих инструкций в том, что в первом случае, если инструкции передать ссылку, результатом будет строка, В остальных случаях результатом будет значение переданного параметра. Во втором случае, результатом инструкции всегда будет строка!
4) Если в запросе имеется поле с составным типом, то для таких полей возникает необходимость привести значения поля к какому-либо определенному типу с помощью инструкции ВЫРАЗИТЬ, что позволит убрать лишние таблицы из левого соединения с полем составного типа данных и ускорить выполнение запроса. Пример:
Имеется регистра накопления ОстаткиТоваров, у которого поле Регистратор имеет составной тип. В запросе выбираются Дата и Номер документов ПоступлениеТоваров, при этом при обращении к реквизитам документа через поле Регистратор не происходит множество левых соединений таблицы регистра накопления с таблицами документов-регистраторов.
Если приведение типа считается не осуществимым, то результатом приведения типа будет значение NULL.
5) Не стоит забывать про инструкцию РАЗРЕШЕННЫЕ, которая означает, что запрос выберет только те записи, на которые у текущего пользователя есть права. Если данное слово не указать, то в случае, когда запрос выберет записи, на которые у пользователя нет прав, запрос отработает с ошибкой.
6) В случае, если в запросе используется объединение, и в некоторых частях объединения присутствуют вложенные таблицы (документ с табличной частью), а в некоторых нет, возникает необходимость дополнения списка выборки полями – пустыми вложенными таблицами. Делается это при помощи ключевого слова ПУСТАЯТАБЛИЦА, после которого в скобках указываются псевдонимы полей, из которых будет состоять вложенная таблица. Пример:
7) Что бы в результат запроса не попали повторяющиеся строки, следует использовать инструкцию РАЗЛИЧНЫЕ, потому что так нагляднее и понятнее, а инструкция СГРУППИРОВАТЬ ПО применяется для группировки с помощью агрегатных функций. Ксати, при использовании агрегатных функций предложение СГРУППИРОВАТЬ ПО может быть и не указано совсем, при этом все результаты запроса будут сгруппированы в одну единственную строку. Пример:
8) Инструкция СГРУППИРОВАТЬ ПО позволяет обращаться к полям верхнего уровня, без группировки результатов по этим полям, если агрегатные функции применены к полям вложенной таблицы. Хотя в справке 1С написано, при группировке результатов запроса в списке полей выборки обязательно должны быть указаны агрегатные функции, а помимо агрегатных функций в списке полей выборки допускается указывать только поля, по которым осуществляется группировка. Пример:
9) Инструкция ЕСТЬNULL предназначена для замены значения NULL на другое значение, но не забываем, что второй параметр будет преобразован к типу первого в случае, если тип первого параметра является строкой или числом.
10) При обращении к главной таблице можно в условии обратиться к данным подчиненной таблицы. Такая возможность называется разыменование полей подчиненной таблицы.
Пример (поиск документов, содержащих в табличной части определенный товар):
Преимущество этого запроса перед запросом к подчиненной таблице Приходная.Товары в том, что если есть дубли в документах, результат запроса вернет только уникальные документы без использования ключевого слова РАЗЛИЧНЫЕ.
11) Интересный вариант оператора В - это проверка вхождения упорядоченного набора в множество таких наборов (Поле1, Поле2, ... , ПолеN) В (Поле1, Поле2, ... , ПолеN).
Пример:
12) При любой возможности используйте виртуальные таблицы запросов. При создании запроса система предоставляет в качестве источников данных некоторое количество виртуальных таблиц - это таблицы, которые так же являются результатом запроса, который система формирует в момент выполнения соответствующего участка кода.
Разработчик может самостоятельно получить те же самые данные, которые система предоставляет ему в качестве виртуальных таблиц, однако алгоритм получения этих данных не будет оптимизирован, так как:
Все виртуальные таблицы параметризованы, т. е. разработчику предоставляется возможность задать некоторые параметры, которые система будет использовать при формировании запроса создания виртуальной таблицы. В зависимости от того, какие параметры виртуальной таблицы указаны разработчиком, система может формировать РАЗЛИЧНЫЕ запросы для получения одной и той же виртуальной таблицы, причем они будут оптимизированы с точки зрения переданных параметров.
Не всегда разработчик имеет возможность получить доступ к тем данным, к которым имеет доступ система.
13) В клиент-серверном варианте работы функция ПОДСТРОКА() реализуется при помощи функции SUBSTRING() соответствующего оператора SQL, передаваемого серверу баз данных SQL Server, который вычисляет тип результата функции SUBSTRING() по сложным правилам в зависимости от типа и значений ее параметров, а так же в зависимости от контекста, в котором она используется. В большинстве случаев эти правила не оказывают влияния на выполнение запроса, но бывают случаи, когда для выполнения запроса существенна максимальная длина строки результата, вычисленная SQL Server. Важно иметь в виду, что в некоторых контекстах использования функции ПОДСТРОКА() максимальная длина ее результата может оказаться равной максимальной длине строки ограниченной длины, которая в SQL Server равна 4000 символам. Это может привести к неожиданному аварийному завершению выполнения запроса:
Microsoft OLE DB Provider for SQL Server: Warning: The query processor could not produce a query plan from the optimizer because the total length of all the columns in the GROUP BY or ORDER BY clause exceeds 8000 bytes.
HRESULT=80040E14, SQLSTATE=42000, native=8618
Чтобы избежать такой ошибки, не рекомендуют использовать функцию ПОДСТРОКА() с целью приведения строк неограниченной длины к строкам ограниченной длины. Вместо нее лучше использовать операцию приведения типа ВЫРАЗИТЬ().
14) С осторожностью используйте ИЛИ в конструкции ГДЕ, так как использование условия с ИЛИ может значительно "утяжелить" запрос. Решить проблему можно конструкцией ОБЪЕДИНИТЬ ВСЕ. Пример:
15) Условие НЕ В в конструкции ГДЕ увеличивает время исполнения запроса, так как это своего рода НЕ (ИЛИ1 ИЛИ2 ... ИЛИn), поэтому для больших таблиц старайтесь использовать ЛЕВОЕ СОЕДИНЕНИЕ с условием ЕСТЬ NULL. Пример:
16) При использовании Временных таблиц нужно индексировать поля условий и соединений в этих таблицах, НО, при использовании индексов запрос может выполняться еще медленнее. Поэтому необходимо анализировать каждый запрос с применением индекса и без, замерять скорость выполнения запроса и принимать окончательное решение.
Если вы помещаете во временную таблицу данные, которые изначально индексированы по некоторым полям, то во временной таблице индекса по этим полям уже не будет.
17) Если вы не используете Менеджер временных таблиц, то явно удалять временную таблицу не требуется, она будет удалена после завершения выполнения пакетного запроса, иначе следует удалить временную таблицу одним из способов: командой УНИЧТОЖИТЬ в запросе, вызвать метод МенеджерВременныхТаблиц.Закрыть().
Итак, устанавливаем минимальный CentOS, настраиваем имена хостов, DNSы и сетевые подключения и приступаем собственно к установке серверных компонентов.
1. Установка Postgre SQL server
Обновление от 03-ноя-2016: в последних версиях CentOS (у меня сегодня был 7.2.1511) отсутствует поддержка libtermcap (и как-то "иначе" реализована libreadline), из-за чего сборки с сайта 1С не устанавливаются - решил поставить сборку от Postgres Professionals https://postgrespro.ru/products/1c_build - вроде работает, но о стабильности и производительности пока судить рано. Так что у кого проблемы с libtermcap.so.2() и/ли libreadline.so.5() при установке PostgreSQL с патчами 1С, можете попробовать этот альтернативный вариант.
Для установки использовался рекомендованный (адаптированный) 1С дистрибутив, для чего потребуется скачать его из раздела поддержки пользователей сайта 1С. В моём случае это был "Дистрибутив СУБД PostgreSQL для Linux x86 (64-bit) одним архивом (RPM)", который я сохранил в /root/temp. Распаковываем архив:
[root@vm-sql01 temp]# tar -vxf postgresql-9.2.1-1.1C_x86_64_rpm.tar.gz
Все недостающие зависимости (пакеты) будут установлены в процессе установки этих rpm, хотя на сайте 1С рекомендуют предварительно установить пакеты readline, libtermcap, krb5-libs и openssl, но в моём случае они либо уже были установлены, либо не были обнаружены в репозиториях.
2. Первый запуск Postgre SQL server
В отличии от сценариев установки большинства знакомых мне sql-серверов, postgres требует предварительной инициализации перед запуском, для чего существует два пути - первый, правильный:
[root@vm-sql01 pgsql]# su postgres -c '/usr/pgsql-9.2/bin/initdb -D /var/lib/pgsql/9.2/data --locale=ru_RU.UTF-8'
Файлы, относящиеся к этой СУБД, будут принадлежать пользователю "postgres".
От его имени также будет запускаться процесс сервера.
Кластер баз данных будет инициализирован с локалью "ru_RU.UTF-8".
Кодировка БД по умолчанию, выбранная в соответствии с настройками: "UTF8".
Выбрана конфигурация текстового поиска по умолчанию "russian".
исправление прав для существующего каталога /var/lib/pgsql/9.2/data... ок
создание подкаталогов... ок
выбирается значение max_connections... 100
выбирается значение shared_buffers... 32MB
создание конфигурационных файлов... ок
создание базы template1 в /var/lib/pgsql/9.2/data/base/1... ок
инициализация pg_authid... ок
инициализация зависимостей... ок
создание системных представлений... ок
загрузка описаний системных объектов... ок
создание правил сортировки... ок
создание преобразований... ок
создание словарей... ок
установка прав для встроенных объектов... ок
создание информационной схемы... ок
загрузка серверного языка PL/pgSQL... ок
очистка базы данных template1... ок
копирование template1 в template0... ок
копирование template1 в postgres... ок
ВНИМАНИЕ: используется проверка подлинности "trust" для локальных подключений.
Другой метод можно выбрать, отредактировав pg_hba.conf или используя ключи -A,
--auth-local или --auth-host при следующем выполнении initdb.
Готово. Теперь вы можете запустить сервер баз данных:
Или второй, более простой, но не всегда дающий необходимый результат (зависит от региональных настроек сервера, но у меня иногда приводивший к установке базы данных без поддержки необходимого collation ru_RU.UTF-8):
[root@vm-sql01 pgsql]# service postgresql-9.2 initdb
Инициализируется база данных: [ OK ]
[root@vm-sql01 pgsql]#
В результате была создана структура базы данных (с настройками) в /var/lib/pgsql/9.2/data. Хочу обратить особое внимание на конструкцию --locale=ru_RU.UTF-8, которую необходимо указать при инициализации, иначе сервер может быть инициализирован с неверным набором языковых параметров, что в конечном итоге приведёт к сообщениям
Ошибка установки или изменения национальных настроек информационной базы
Порядок сортировки не поддерживается базой данных
по причине:
Порядок сортировки не поддерживается базой данных
при установке информационной базы. Теперь можно настраивать автоматический запуск sql-сервера и, собственно, запускать его:
[root@vm-sql01 temp]# chkconfig postgresql-9.2 on
[root@vm-sql01 temp]# service postgresql-9.2 start
Запускается служба postgresql-9.2: [ OK ]
[root@vm-sql01 temp]#
Всё. Для локальных подключений сервер настроен. В моём случае сервер 1С и сервер SQL находятся на разных машинах, поэтому потребуется настроить и удалённые подключения с авторизацией.
В случае каких-то проблем, читаем содержимое файлов:
/var/lib/pgsql/9.2/pgstartup.log
/var/lib/pgsql/9.2/data/postgresql-*.log
Для повышения быстродействия документация PostgreSQL рекомендует как минимум унести журнал /var/lib/pgsql/9.2/data/pg_xlog на отдельный физический том и создать симлинк на него в исходном месте; из личных наблюдений - надо ещё и значительно увеличить размер используемой памяти... но необъятное не охватить, поэтому за статьями по оптимизации работы PostgreSQL для 1С предлагаю обращаться в поисковые системы, а оттуда - на профильные форумы.
3. Настройка пользователей (ролей) Postgre SQL server
Для управления PostgreSQL на начальном этапе потребуется сменить текущего пользователя на postgres и создать нового пользователя из командной строки:
[root@vm-sql01 temp]# su - postgres
-bash-4.1$ cd /usr/pgsql-9.2/bin
-bash-4.1$ createuser --interactive -P
Введите имя новой роли:server1c
Введите пароль для новой роли:
Повторите его:
Должна ли новая роль иметь полномочия суперпользователя? (y - да/n - нет) n
Новая роль должна иметь право создавать базы данных? (y - да/n - нет) y
Новая роль должна иметь право создавать другие роли? (y - да/n - нет) n
-bash-4.1$ exit
logout
[root@vm-sql01 temp]#
В принципе, для обслуживания полезно иметь пользователя с правами суперпользователя - создавать его можно тем же путём.
Теперь осталось разрешить удалённое подключение с авторизацией - для этого в файле /var/lib/pgsql/9.2/data/pg_hba.conf потребуется заменить значение ident на md5 в строке "host all all 0.0.0.0/0 md5" и перезапустить сервис.
Не следует забывать и про настройки iptables - для работы Postgre SQL необходимо открыть как минимум порт tcp 5432, хотя привычнее (да и проще) объявить сетевой интерфейс "внутренним" (разрешить все подключения на интерфейсе).
Для управления сервером потребуется pgAdmin, который можно установить из репозиториев используемого для административных целей линукса, либо скачать с сайта проекта.
4. Установка компонентов сервера 1С
Внимание!!! Для избежания проблем с зависимостями, желательно, чтобы разрядность сервера 1С совпадала с разрядностью используемого дистрибутива Linux! Иначе (если ставим 32-битный 1С на 64-битный Linux), при входе в базу, можно получить сообщение типа "Ошибка загрузки библиотеки libWand.so по причине:Библиотека не обнаружена. Часть функций будет недоступна." и клиенты не будут запускаться (хотя конфигуратор - будет). В принципе, я с этой проблемой справился на CentOS 7 (которой не выпускают больше в 32-битном исполнении) - просто поставил не только 'ImageMagick', но и 'ImageMagick.i686' (yum install ImageMagick.i686) - всё заработало (хоть и притянуло за собой гору зависимостей).
Первый шаг установки сервера 1С мало отличается от аналогичного этапа с SQL-сервером - распаковать скачанный дистрибутив сервера командой tar -vxf rpm64.tar.gz. В итоге получим файлы:
1C_Enterprise83-common-8.3.3-715.x86_64.rpm - основные файлы 1С (включая русский и английский интерфейсы)
1C_Enterprise83-common-nls-8.3.3-715.x86_64.rpm - дополнительные языковые модули
Настраиваем автоматический запуск демона и стартуем его:
[root@vh-1c83 temp]# chkconfig srv1cv83 on
[root@vh-1c83 temp]# service srv1cv83 start
Starting 1C:Enterprise 8.3 server: Error: service failed to start!
FAILED
[root@vh-1c83 temp]# service srv1cv83 start
Starting 1C:Enterprise 8.3 server: OK
[root@vh-1c83 temp]#
Хочу обратить внимание - если сразу после установки сервис (как в приведённом примере) не стартовал, а при второй попытке старта он запустился, скорее всего не настроен DNS - об этом чуть ниже. Если верить информации с многочисленных форумов, то наш сервер уже готов обслуживать до 12 клиентов. Для работы большего числа пользователей, необходимо установить лицензию сервера - либо в виде USB HASP и драйвера, либо в виде электронной лицензии. Про установку аппаратных ключей я уже писал, а установка программных лицензий достаточно проста: запускаем конфигуратор (с клиентской машины; кластер уже должен быть настроен и должна быть информационная база), вызываем "Сервис" - "Получение лицензии", вводим номер комплекта (с коробки или "Регистрационный номер" с карточки из конверта "Пинкоды программной лицензии") и пин-код (с той самой карточки из конверта), ставим галочку "Установка на сервер", вводим имя сервера в соответствующем поле, нажимаем "Далее", говорим, что это - "Первый запуск", заполняем форму "Владелец лицензии" (к стати, я не понял что писать в полях "Фамилия", "Имя", "Отчество" - то ли ответственного за эксплуатацию, то ли генерального директора - оставил поля пустыми, и оно получило лицензию, не ругнувшись), "Далее", "Автоматически" - профит! в /var/1C/licenses на сервере появился файлик XXXXXXXXXXXXXX.lic и серверу "стало хорошо" (если это была многопользовательская лицензия, то клиентам тоже "станет хорошо", т.к. они будут получать лицензии на сервере).
Для работы с графическими объектами и экспорта в xls, могут потребоваться дополнительные пакеты: ImageMagick, freetype (входит в зависимости ImageMagick), libgsf (входит в зависимости ImageMagick), corefonts (отсутствует в репозитариях CentOS - см. раздел 6); для "ТАКСИ" и "Управляемого приложения" они необходимы, для классического толстого клиента вроде бы не особо нужны, но 1С всё равно ругается на их отсутствие, хоть и работает.
По умолчанию сервер 1С слушает порт tcp 1541(1540) и для соединений использует диапазон портов 1560-1691.
5. Настройка экземпляра (кластера) сервера 1С
Информации о наличии оснастки управления сервером 1С для Linux мне не попадалось, так что для управления сервером будем использовать традиционную оснастку mmc для Windows "Администрирование серверов 1С:Предприятия", которую следует поставить из дистрибутива технологической платформы для Windows.
В этом месте на тестовом сервере возникли трудности - кластер по умолчанию отсутствовал, а при попытке создания нового кластера, ragent аварийно завершал работу с сообщением Sep 3 21:29:04 vh-1c83 kernel: ragent[1879]: segfault at 8 ip 00007f56473c9fd4 sp 00007f563b7b14a0 error 4 in rserver.so[7f56472db000+70e000]... странно, но если верить форумам, на CentOS у многих сервер 1С 8.3 ставится некорректно - не создаётся начальная конфигурация, включающая "Кластер по умолчанию". Краткий анализ ситуации выявил, что настройки кластера по умолчанию не были сгенерированы полностью и не попали в /home/usr1cv8/.1cv8/1C/1cv8/.
При попытке подложить файлы с рабочего сервера на неудачный, сервис 1С не запускается абсолютно без каких-либо диагностических сообщений - подобное поведение я видел при проблемах (неверных контекстах) SELinux, но в данном случае никаких отказов в audit.log не обнаружилось.
В результате детального изучения проблемы с применением strace удалось выяснить, что агент сервера при запуске ищет настройки по пути ~/.1cv8/1C/1cv8/ (в домашнем каталоге запустившего пользователя) и если не находит, пытается создать настройки кластера по умолчанию, для чего ему нужно имя хоста (выяснено экспериментально), и если верить "Руководству администратора", нужен корректно работающий DNS; экспериментально же был установлен факт, что сначала ragent читает файл /etc/hosts, затем обращается к DNS-серверу, а затем вызывает uname и снова лезет в hosts и к DNS и если не находит сопоставления, аварийно завершается. Итак, для нормального запуска потребуется полноценная и правильно настроенная сетевая инфраструктура, ну а в отсутствии работающего DNS достаточно дописать строчку в /etc/hosts и привести его примерно к такому виду:
За дальнейшими инструкциями пока отсылаю к своей статье про 8.2 - принципиальных отличий пока нет. Единственное замечание - при создании новой информационной базы, если указывать пользователя подключения к базе данных не с правами суперпользователя (а с набором прав из пункта 3), информационная база не создавалась, а в /var/lib/pgsql/9.2/data/pg_log/postgresql-Xxx.log наблюдались сообщения:
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: нет доступа к языку c
ОПЕРАТОР: CREATE OR REPLACE FUNCTION plpgsql_call_handler() RETURNS language_handler AS '$libdir/plpgsql' LANGUAGE C
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: ошибка синтаксиса (примерное положение: "application") в символе 24
ОПЕРАТОР: lock table pg_class in application share mode
ПРЕДУПРЕЖДЕНИЕ: нет незавершённой транзакции
ОШИБКА: тип "mvarchar" не существует в символе 31
ОПЕРАТОР: create table Config (FileName mvarchar(128) not null, Creation timestamp not null, Modified timestamp not null, Attributes int not null, DataSize int8 not null, BinaryData bytea not null, PartNo int not null, PRIMARY KEY (FileName, PartNo))
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: нет доступа к языку c
ОПЕРАТОР: CREATE OR REPLACE FUNCTION plpgsql_call_handler() RETURNS language_handler AS '$libdir/plpgsql' LANGUAGE C
После подключения с учётными данными суперпользователя БД, сообщения изменились на англоязычные и проблемы исчезли. Судя по всему, если на сервере установлен язык по умолчанию en_US, данного казуса не случится, но это - не проверенная информация, а лишь предположение, сделанное по прочтении чужой статьи про 8.1 и праздных раздумий =)
Ещё одна странность - если создать пустую SQL базу не из шаблона1 (см. официальную документацию по 1С), и попытаться ей указать на этапе создания ИБ, то всё равно получим сообщение "ОШИБКА: тип "mvarchar" не существует (символ 31)"/"ERROR: type "mvarchar" does not exist at character 31", но мне так и не удалось создать из требуемого шаблона БД - валились разные ошибки, но если пользователя sql, от которого создаётся ИБ временно повысить до суперпользователя с правом создания БД, и указать создание базы данных в случае её отсутствия, то всё получается в лучшем виде, так что на этапе первичной настройки, видимо, придётся повышать пользователя до супер...
Что порадовало - теперь в 1С можно работать непосредственно из Linux, что актуально для компаний, использующих его как основную ОС в корпоративной сети (я сейчас работаю как раз в такой компании); из неожиданностей - что при установке клиента 1С, он заявляет о зависимости от сервера и требует его установки, но потом ставится, прописывает значки запуска в "Офис" - "Финансы" и работает довольно сносно (по ощущениям - чуть менее комфортно, чем 8.2 под Windows, но заметно приятнее, чем тот же 8.2 через WINE от Ethersoft).
6. Установка недостающих зависимостей
При запуске клиента к настроенному по данной инструкции серверу, появится сообщение "На сервере отсутствуют шрифты из состава Microsoft Core Fonts. Внешний вид приложения может отличаться от ожидаемого. Процедура установки описана в справочной системе..." - данное сообщение появляется достаточно редко (периодичность не выявил, но появляется точно не единожды, но и не при каждом запуске), и на работе особо не сказывается, но "для красоты" я решил пройтись по всей цепочке и поставить рекомендуемые пакеты. Всё, кроме "corefonts" поставилось из репозиториев (хотя в той самой "справочной системе" безбожно перепутаны регистры в названиях пакетов, из-за чего их идентификация оказалась весьма развлекательна), ну а шрифты я решил пересобрать (в соответствии с рекомендациями из "справочной системы") и результат прикрепляю к статье - msttcorefonts-2.5-1.noarch.rpm, заодно и сами шрифты (уже переименованные в нижний регистр, как происходит при сборке rpm рекомендованным скриптом) - msttcorefonts.tar.gz - содержимое этого архива рекомендуют распаковать в /home/usr1cv8/.fonts (не забыв сменить владельца как на папку, так и на файлы!), если нет возможности установить предложенный .rpm
Кроме "ImageMagick" и шрифтов, для возможности сохранения в табличные файлы (кроме xls - его я пока не заставил формироваться, хотя xlsx формируется), на клиенте должны быть установлены пакеты "libMagickWand5", "libgomp1", "liblcms2-2" и "libbz2-1" - на ряде машин они отсутствовали. При чём той же разрядности, что и сервер 1С (см. п. 4).
7. Настройка аппаратного hasp для виртуализированного сервера 1С (работающего на виртуальной машине KVM)
Не планировал описывать эту процедуру, но раз уж столкнулся с такой ситуацией, опишу... Итак, на этот раз я использовал драйвер от "Alladin Knowledge Systems USB HASP", предоставляемый компанией Sentinel - мне попались две версии:
2878061 сен 11 2012 aksusbd-2.0-1.i386.rpm - с сайта aladdin-rd.ru
3009880 авг 6 16:35 aksusbd-2.2-1.i386.rpm - с сайта safenet-inc.com
Можно воспользоваться драйвером эзерсофт - окончательный выбор следует делать из опыта практической эксплуатации.
Наиболее правильная (на мой взгляд) последовательность действий:
а) убедиться, что на хост-машине драйвер HASP не установлен;
б) установить выбранный драйвер USB HASP4 на виртуальном сервере;
в) выяснить список подключенных USB-устройств к хост-машине
[root@vh01 files]# ls -R /dev/bus/usb
/dev/bus/usb:
001
002
003
004
/dev/bus/usb/001:
001
002
/dev/bus/usb/002:
001
/dev/bus/usb/003:
001
/dev/bus/usb/004:
001
[root@vh01 files]#
г) подключить USB-HASP к хост-машине и выяснить адрес ключа:
[root@vh01 files]# ls -R /dev/bus/usb
/dev/bus/usb:
001
002
003
004
/dev/bus/usb/001:
001
002
/dev/bus/usb/002:
001
/dev/bus/usb/003:
001
/dev/bus/usb/004:
001
002 <==== это наш ключ - раньше его не было
[root@vh01 files]#
д) используя любой из способов (я использовал Virtual Manager на удалённой машине) добавить "USB Host Device" с найденным адресом (в моём примере - 004:002) к виртуальной машине 1С - может потребоваться выключение и включение машины (я добавлял устройство на выключенную машину).
Собственно, всё - на CentOS 6.4 x64/i686 всё работает (были багрепорты про CentOS 6.0/6.1, но вроде всё починили). Если при запуске виртуалки выдаётся сообщение о занятости устройства, скорее всего подцепился драйвер на хост-машине (так писали на паре форумов, хотя мне эту ситуацию воспроизвести не получилось - даже с установленным драйвером на сервере устройство мапилось корректно). Естественно, если переставить ключ в другой порт USB, придётся перенацеливать и виртуальную машину!
/home/usr1cv8/.1cv8/1C/1cv8/1cv8wsrv.lst - файл, в котором хранятся основные свойства сервера - например, учётные данные администратора сервера, зарегистрированые кластеры и т.п.
/home/usr1cv8/.1cv8/1C/1cv8/reg_1541/1CV8Clst.lst - файл, в котором хранятся свойства кластера по умолчанию
/opt/1C/v8.3/x86_64/ - (вместо "x86_64" может быть "i386" - в зависимости от архитектуры системы) исполняемые файлы и сопутствующие ресурсы сервера (и клиента) 1С
/var/1C/licenses - здесь лежат файлы электронных ключей лицензий
8. Настройка локального репозитория 1С для удобства обновления платформы
В процессе эксплуатации 1С нередко приходится обновлять платформу. Если всё установлено по приведённой выше инструкции, это вызывает определённые неудобства - надо останавливать сервис, удалять старые пакеты, ставить новые... не знаю - мне это ещё в винде надоело смертельно. Linux предлагает очень удобный механизм пакетного обновления из локального репозитория - всё, что нужно - это выбрать место, где будут лежать обновки: для одиночного сервера, к которому все ходят только через web-интерфейс, это может быть /root/repo (всё равно обновление под рутом идёт), ну а в общем случае - хоть /var/www/1c-repo - главное, чтобы все, кому он нужен, его видели. Далее надо установить пакет 'createrepo' (yum install createrepo) - за собой он притащит немало зависимостей, но не смертельно. Теперь командой 'createrepo /root/repo' (где "/root/repo" - выбранный путь хранения репозитория) создаём его "описание" и можно пользоваться.
Затем создаём файл описания нашего репозитория и помещаем его в каталог описаний репозиториев (для CentOS это /etc/yum.repos.d). Пример конфига локального файлового репозитария:
[root@1c yum.repos.d]# cat local-1c.repo
[local-1c]
name=1C Enterprise
#baseurl=http://inhost.firm.lan/repo
baseurl=file:///root/repo
gpgcheck=0
enabled=1
По-моему, разъяснять что за что отвечает, особого смысла нет. Единственное, что важно - сразу yum его может не увидеть - в этой ситуации поможет очистка его кэшей (yum clean all).
Всё. Теперь если надо обновиться, то помещаем новые файлы дистрибутива 1С рядом со старыми, повторяем 'createrepo /root/repo' вызываем 'yum update' - и всё - платформа пошла обновляться! Естественно, за сохранностью и защищённостью своего репозитория надо следить, так как GPG у нас выключен, и это всё же дыра в безопасности, хоть и не особо толстая...
Обратился ко мне клиент с задачей: Нужно запретить изменение всех видов платежных документов (ПП, РКО, ПКО) спустя 8 часов с момента проведения соответствующего документа
Для реализации этого я использовал Подписку на событие: ПередЗаписьюДокументаДатаЗапретаРедактирования
В конце процедуры обработчика добавил вызов своей процедуры
Вот ее код:
Пока документ не проведен, его можно менять сколько угодно, но после первого проведения и истечения указанного количества часов, документ заблокируется, и при проведении будет выведено сообщение:
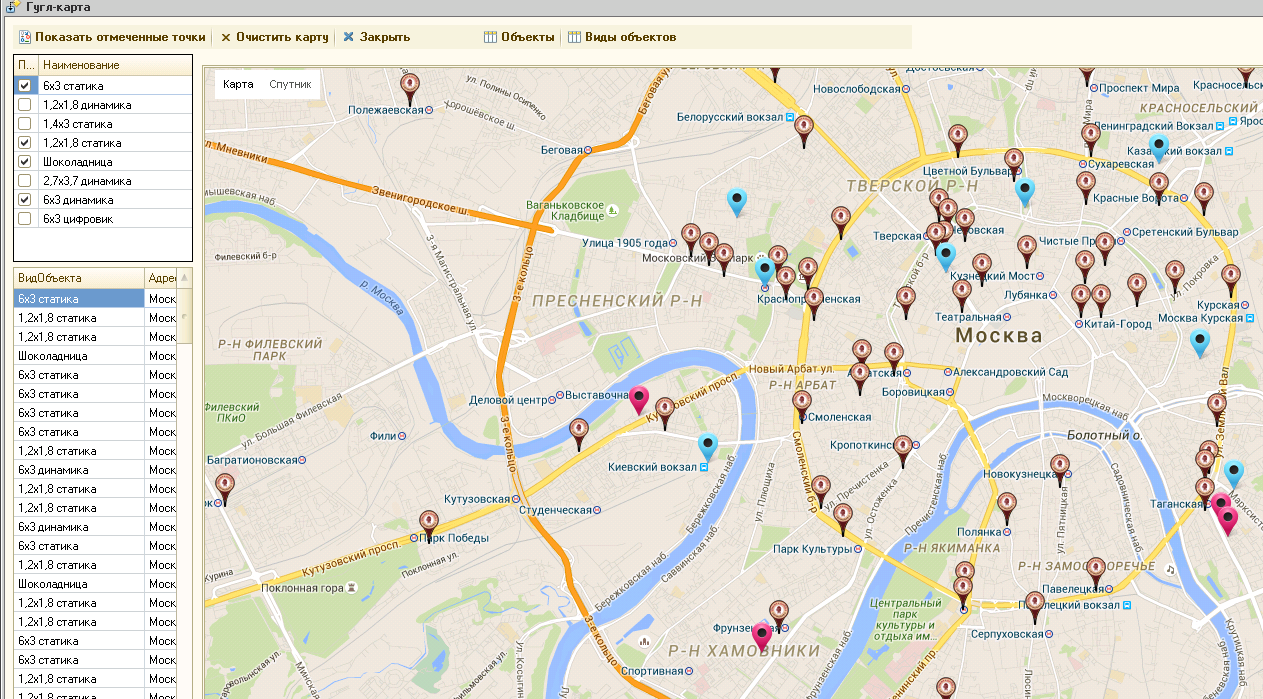
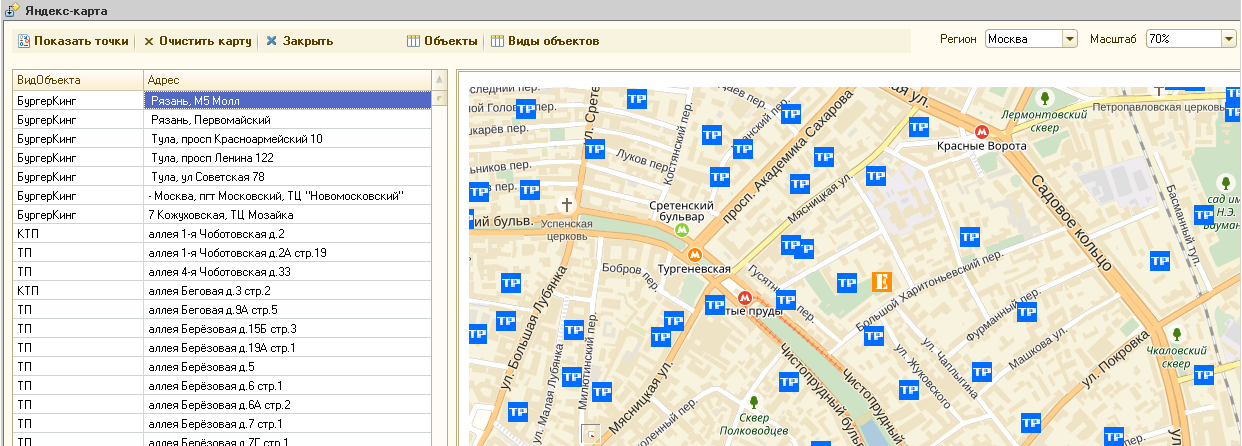
В отличие от яндекс карт в GMaps можно использовать панорамы - за что им большой плюс! Надеюсь в яндексе прочитают этот пост и тоже когда-нибудь это сделают!
Для клиента нужно было сделать вывод объектов на карту
Обратился ко мне старый клиент и говорит - беда с нумерацией счетов!
Менеджеры, кто как хотел - так и изменял номера документов. с префиксом, без, писали даже б/н. Но тут пришел новый бухгалтер и сказал - нужно с 1 октября запустить авто нумерацию с номера 00010000, но старые счета не трогать!
Попросили - сделали:
т.к. Старые трогать нельзя - простое восстановление нумерации отпадает
Первое решение, которое пришло в голову, сделать выборку по моментувремени создания счета - обратная сортировка - получить первый - и к полученному номеру документа +1
Но оказалось, что бывает такое: менеджеры создают счета сегодня, но ставят дату вчера - и получается только что созданный документ уже не последний пришлось переделать алгоритм.
Только алгоритм решили немного переделать - не получаем дату создания документа, а сортируем по части ГУИДа, которая является началом периода создания документа.
За 2015 год специалистами 1С доработаны сложные моменты, разработаны новые возможности, да и функционал постоянно развивается. Например, разработано 2 сценария перехода и переноса данных, дописан механизм учета оценочных обязательств, разработано множество новых документов. Бывали случаи, когда решения, сделанные по запросу, с выходом очередного релиза включались в типовую конфигурацию.
Тем не менее, на подводные камни можно наткнуться до сих пор.
Один из таких «камней» - галочки «по умолчанию». Например, флажок «Использовать эти же данные при расчете отпусков командировок и др.» в форме «ввод данных для расчета среднего», в документах «Больничный лист», «Отпуск», «Командировка». Этот флажок установлен «по умолчанию». Поэтому после открытия для просмотра формы «ввод данных» и последующего нажатия кнопки «ок», корректно перенесенные данные для расчета среднего заработка отпуска без предупреждений заменятся на данные для расчета больничного листа. Пока за этой галочкой нужно следить.
Настройка интерфейса
В программе реализован спектр возможностей, она предназначена для ведения учета на предприятиях различного масштаба. Часть ее функционала необходима всем предприятиям практически без исключения, часть предусмотренных в ней возможностей требуется только определенным компаниям. Поэтому в начале работы с программой можно явно указать, какой именно функционал нужен для ведения учета на данном конкретном предприятии. Изменить сделанный выбор можно и позже, даже если учет в программе уже ведется. Можно добавить или, напротив, удалить функционал. При добавлении нового функционала в интерфейсе программы появляются новые соответствующие команды, кнопки и т. п., становятся доступны новые объекты и действия (документы, справочники, начисления и т. п.). Если же некий функционал не выбран, то программа не загромождается ничем лишним, не востребованным в данный момент.
Внешний вид и поведение программы могут различаться от предприятия к предприятию в зависимости от выбранных возможностей, а также – от пользователя к пользователю, в зависимости от того, какие права доступа даны.
Возможна и «тонкая донастройка» интерфейса: управлять им можно непосредственно, включая или выключая видимость разделов, элементов, форм и т. п., а также меняя их расположение. Таким образом, теперь для того, чтобы настроить меню и внешний вид рабочего стола, не нужно приглашать программиста.
Справочник «сотрудники»
Расширена возможность создания документов из карточки сотрудника. Карточка сотрудника дополнена ссылками на документы по сотруднику.
Единые документы для кадровика и расчетчика
Единый документ выглядит для расчетчика и для кадровика по-разному. Права доступа ограничены в зависимости от роли. Если же в компании роль кадровика и расчетчика выполняет один человек, можно перенастроить программу для работы одного человека с единым документом.
Пример: Документ «Отпуск» (Кадры)
Количество кадровых документов в редакции 3.0 значительно увеличилось.
Оформление отпуска по уходу за ребенком-инвалидом по разрозненным датам можно формировать одним документом, а не создавать разные приказы на каждый период отпуска.
Некоторые доработки в расчетных документах.
Документ Расчет заработной платы:
Все начисления и удержания удобно собраны в одном документе.
Разберем, как изменялся (скорее дополнялся) синтаксис текстов запросов на простом примере: Проводится документ Расходная содержащая в табличной части Товары список продаваемых товаров и количество. При проведении такого документа необходимо обеспечить контроль отрицательных остатков хранящихся в регистре накопления остатков ОстаткиТоваров.
Структура конфигурации представлена на рисунке справа:
Сформируем запрос к табличной части документа и виртуальной таблице Остатки регистра накопления. Учтем возможные дубли строк в документе, для этого произведем группирование записей.
Естественно приведенный запрос абсолютно не оптимален. С помощью вложенных запросов оптимизируем его: Произведем группирование табличной части документа до соединения с таблицей остатков, в параметры виртуальной таблицы передадим список товаров как значение условия для расчета остатков. В итоге наш запрос примет следующий вид:
Если бы в запросе необходимо было бы получить данные из остатков разных регистров то значение фильтра, а следовательно и наш второй вложенный запрос, повторялся бы во всех параметрах виртуальных таблиц, естественно что система при каждом вложенном запросе заново обращается к базе данных для получения данных.
Временные таблицы
Не помню уже с какого релиза в запросах стало можно использовать временные таблицы. Для этого используется объект «Менеджер временных таблиц». Фактически менеджер временных таблиц описывает пространство имен временных таблиц и отвечает за их создание и уничтожение в базе данных.
Сами временные таблицы действительно физически создаются в базе, соответственно следует относиться к ним осторожно, так как дисковая подсистема на сегодняшний момент самая медленная часть техники, а скорость создания и уничтожения таблиц напрямую от нее зависит.
Перепишем запрос для использования временных таблиц. Во временные таблицы поместим сгруппированную табличную часть документа и список товаров для фильтра виртуальных таблиц:
При использовании временных таблиц в тексте запроса применяют инструкцию Поместить для создания новой временной таблицы, в этом случае в результат запроса система передает не содержимое этой таблицы (см прим 1 и прим 2 в тексте выше), а количество записей помещенных во временную таблицу, по желанию можно не принимать это значение.
Также допускается использование инструкции Уничтожить в этом случае временная таблица уничтожается, в противном случае временные таблицы уничтожаются вместе с объектом менеджер временных таблиц.
В основном нашем запросе я использовал названия временных таблиц как указание на источник получения данных (им обязательно надо назначать синоним, что мы и видим в тексте). Использовать временные таблицы как источник можно не единожды, что при умелом их применении позволит и сократить текст запроса (улучшиться читабельность сложных запросов) и увеличить скорость (при использовании данных временной таблицы в нескольких местах запроса).
Пакетные запросы
Пакетные запросы логично дополняют функционал временных таблиц и дают больше возможностей при работе с запросами.
В пакетном запросе фактически можно описать несколько запросов, как связанных между собой использованием временных таблиц, так и не связанных (можно, но не понятно зачем?). В итоге можно выполнить последовательно все запросы и принять в результате либо массив с результатами исполнения каждого запроса, либо результат последнего. Для получения массива с результатами запроса применяют метод ВыполнитьПакет() объекта запрос, а для получения результата последнего запроса ВыполнитьЗапрос().
В тексте запроса, запросы пакета разделяются символом «;» (точка с запятой). Область имен виртуальных таблиц у одного пакетного запроса одна. Использование менеджера временных таблиц не требуется, но возможно если вы хотите передать временные таблицы из одного пакетного запроса в другой.
Перепишем процедуру для использования пакетных запросов:
Фактически я убрал определение объекта запрос и использование менеджера временных таблиц, объединил тексты запросов (обратите внимание на разделитель «;» между текстами). В результате текст запроса стал читабельнее (а при использовании конструктора запросов намного увеличивается удобство чтения запроса).
После выполнения запроса в переменную МассивРезультатов у нас попадет 3 элемента. Первые два будут содержать число характеризующее количество записей помещенных во временные таблицы ДокТЧ и СписокТоваров, а третий будет содержать выборку с полями Номенклатура, Док_Количество и Рег_Количество.
В переменную РезультатЗапроса попадет только выборка.
Ну вот и все что касается пакетных запросов. Очень удобный механизм и с точки зрения написания запросов и с точки зрения чтения сложных запросов.
Клиент попросил настроить автоматическую архивацию баз 1С раз в три дня и выгрузку архивов на Dropbox и на FTP Сервер. Кроме 1С нужно архивировать папку с рабочими документами. Хочет - так хочет, делаем:
Первым делом настроим автоматическую архивацию данных. Конечно, можно использовать планировщик Windows и VBS скрипт, но это дедовский способ, т.к. уже полно универсальных, платных и бесплатных инструментов для архивации данных.
Из платных могу посоветовать handy backup, версия expert умеет работать с 1С, но цена ~ 5 300 немного останавливает - поэтому мы используем бесплатный Cobian Backup - респект разработчику!
Установка Cobian Backup
Скачиваем с оф. сайта
и запускаем установщик:
Устанавливаем службу, используя учетку от 1С
Далее идет установка, ОК по завершении.
Настройка автоархивирования 1С
У нас в арсенале 3 базы 1С:
1 - файловая
2 - серверных
Для создания архивов 1С мы будем использовать типовой механиз, для этого создана папка Backup1C и в ней bat файлы выполняющие архивацию баз:
Для файловых баз код bat файла следующий (zup.bat):
Для серверных (crm.bat):
Отроем Cobian Backup, для создания заданий
Настроим архивацию файловой базы:
Добавляем создание, снимаем галки внизу, т.к. у нас не будет прямого копирования:
на закладке Файлы устанавливаем копирование каталога на FTP:
Расписание:
далее можно задать цикличность - приоритет, сжатие архивов, шифрование - но это я буду использовать при архивировании документов, а для 1С мы это не используем.
Доп. действия:
Выполнить и ждать закрытия bat файл и добавим паузу в 180 секунд (этого времени хватает чтобы выполнить выгрузку базы ЗУП)
На закладке Дополнительно, я поставил только одну галку - Синхронизация
Итог настройки:
Запускаем задание для проверки работоспособности, и через ~ 3 минуты:
Архив успешно создан, FTP сервер я пока не настроил, поэтому он вызвал ошибку - Но главное мы получили дамп базы 1С для дальнейшего копирования на сервера ftp, при верных настройках ftp, все отлично копируется - проверено уже не раз
Настраиваем архивацию серверной базы
Тут все тоже как и в файловой, только добавим перезапуск агента сервера 1С(для перезапуска процессов 1С и отключения пользователей)
и базы на SQL большие - поэтому после выполнения bat файла добавим паузу 3000 секунд
Результат тестового выполнения:
Архив сделался за 8 минут, т.е. паузы 600 секунд вполне хватит.
Выгрузка на Dropbox
Для выгрузки на DropBox использовал резервное копирование от Антивируса Касперского. Он быстро подключился к хранилищу, правда пришлось на нем оплатить место до 1 ТБ)
В итоге:
все работает как часики: архивы создаются 2 раза в неделю и заливаются на облачные сервера
Поступил ко мне запрос: Можно ли сделать, чтобы автоматически считало Компенсацию питания в зависимости от количества отработанных дней по табелю?
Компенсация питания
Стоимость питания, полученного работником от работодателя или оплаченного работодателем за работника, является доходом сотрудника и облагается НДФЛ (Письмо Минфина России от 31.03.2011 N 03-03-06/4/26).
В соответствии с п. 2 ст. 211 Налогового кодекса РФ, стоимость полученного питания признается доходом работника в натуральной форме. Налогом на доходы физических лиц будут облагаться следующие выплаты:
стоимость продуктов питания, которые работодатель передал работнику, в том случае если работодатель самостоятельно закупает такие продукты и передает их своим работникам.
стоимость услуг специализированных организаций, если работодатель заключил договор на оказание услуг общественного питания своим работникам. Стоимость данных услуг по предоставлению питания должна включать НДС, в соответствии с п. 1 ст. 211 Налогового Кодекса РФ.
Создадим новое основное начисление.
Откроем меню «Расчет зарплаты по организациям» далее выбираем «Настройка расчета зарплаты» документ «Основные начисления организаций».
Нажмем на кнопку «Добавить» и заполним поля документа:
поле «Последовательность расчета» - выбираем «Первичное начисление».
поле «Способ расчета» - необходимо указать каким образом будет производиться данное начисление в программе, для этого настроим формулу расчета и выберем значение «Произвольная формула расчета», далее нажимаем «Редактировать формулу расчета».
Оплату питания сотрудников организации будем производить пропорционально отработанным дням, поэтому в формуле расчета необходимо указать «Стоимость обеда * время в днях».
Необходимо добавить новый показатель «Стоимость обеда» он будет имеет следующие значения:
вид показателя – денежный.
назначение показателя – для всей компании (организации) или для подразделения
порядок ввода показателя – периодически.
Перейдем на закладку «Время».
Установим флажок в поле «Дополнительное начисление за уже оплаченное время».
В реквизите «Вид времени по классификатору использования рабочего времени» установим значение из классификатора – «Явка».
Перейдем на закладку «Использование».
Все значения в данной закладке оставляем по умолчанию и ничего не меняем.
Перейдем на закладку «Бухучет и ЕНВД».
Галку - является натуральным доходом
В данной закладке необходимо указать способ отражения начисления в регламентированном учете.
В том случае, если оплата стоимости питания предусмотрена системой оплаты труда организации, то необходимо выставить значение – «По данным о сотруднике и его плановых начислениях».
В том случае, если оплата питания не предусмотрена трудовым или коллективным договором, то расходы по начислению не могут быть приняты для целей налогового учета. Данные расходы необходимо учитывать по статье затрат с установленным видом расходов НУ «Не учитываемые в целях налогообложения».
Перейдем на закладку «Налоги».
В первом реквизите «НДФЛ» установим значение «Облагается, код дохода» выберем из всплывающего списка код дохода «4800».
Далее переходим к реквизиту «Налог на прибыль, вид расхода по ст.255 НК РФ» в данном поле необходимо установить флажок из двух вариантов:
ставим флажок в поле «Учитывать в расходах на оплату труда по:» - в том случае, если оплата стоимости питания предусмотрена системой оплаты труда организации, из списка выставляем «пп.25, ст.255 НК РФ».
в том случае, если оплата питания не предусмотрена трудовым или коллективным договором, то расходы по начислению не могут быть приняты для целей налогового учета устанавливаем флажок в первом поле «Не включается в расходы на оплату труда».
Перейдем на закладку «Взносы».
Перейдем к реквизиту «Страховые взносы в ПФР, ФСС и ФОМС» выставим в поле «Вид дохода» выбираем из всплывающего списка «Доходы, целиком облагаемые страховыми взносами».
Далее в поле «ФСС, страхование от несчастных случаев (до 2011 года)» устанавливаем флажок в поле «Облагается».
Следующее поле в данной закладке «ЕСН (до 2010г.)» выбираем вид дохода «Облагается ЕСН, взносами в ПФР целиком».
Перейдем на закладку «Прочее».
В данной закладке необходимо указать все вытесняющие виды расчета, в период действия которых оплата стоимости питания не будет начисляться.
Установка сумму показателей
Далее перейдем в меню «Расчет зарплаты по организациям» выберем подменю «Показатели расчета заработной платы».
Перейдем на закладку «Постоянные».
Пример установки значения для определенного подразделения:
Если нужно в целом по компании, то Выберем «Данные по организации» для все организации в целом и в правой колонке таблицы введем дату и сумму размера оплаты питания сотрудников.
Вводим плановое начисление
Если оплату стоимости питания необходимо начислять сотрудникам ежемесячно в течение определенного периода времени, т.е. в плановом порядке, то в программу необходимо ввести новый документ «Ввод постоянного начисления или удержания организаций».
Для создания документа необходимо перейти в меню на панели инструментов «Расчет зарплаты по организациям» далее выбираем «Плановые начисления» документ «Ввод постоянного начисления или удержания организаций».
Нажмем «Добавить».
поле «Номер» выставляем дату формирования операции в программе.
поле «Действие» выставим значение «Внести или изменить начисление».
поле «Вид расчета» выставим из справочника «Основные начисления организации» новое начисление, добавленное в шаге №1 – «Компенсация питания».
поле «Период» выставляем период с которого применяется данное начисление.
Заполняем табличную часть «Сотрудники и показатели для расчета».
В данном поле выставляем сотрудников которым производится оплата питания, из справочника «Сотрудники».
Записываем документ и проводим в программе.
Теперь данное начисление будет автоматически рассчитываться при Начислении ЗП
Не редко возникает необходимость загрузить в справочники или документы 1С данные из текстового файла. Приведенный пример внешней обработки позволит преобразовать текстовый файл с известным разделителем данных в поле табличного документа для последующей обработки уже внутри 1С:Предприятия. Обработка содержит функцию разбора строки на массив данных, настраиваемый разделитель строки текста на "столбцы", процедуру чтения данных из текстового файла.
Разбор строки в массив с использованием функций из конфигурации 1С
Для разложения строки в массив в конфигурация 1С:Бухгалтерия, 1С:Торговля и 1С:УПП имеется замечательная функция - Функция РазложитьСтрокуВМассивПодстрок(Знач Стр, Разделитель = ",") Экспорт. Функция "расщепляет" строку на подстроки, используя заданный разделитель. Разделитель может иметь любую длину. Если в качестве разделителя задан пробел, рядом стоящие пробелы считаются одним разделителем, а ведущие и хвостовые пробелы параметра "Стр" игнорируются. Подробнее можно прочесть внутри конфигурации - "Общие модули" -> "Общего назначения". Функция возвращает массив значений, элементы которого - подстроки.
Чтение текстового файла (txt) в 1С
Операцию импорта - экспорта текстовых файлов (формат тхт или csv, а также htm, html) очень удобно реализовать при помощи конструкции следующего вида:
1. Функция ПолучитьПотокЧтенияСтрок(Файл) - Назначение: Проверить наличие файла (функция Файл()), Создать текстовый документ (Новый ТекстовыйДокумент()), вызвать метод "Прочитать" для открытия потока чтения файла. Возвращает поток, готовый для чтения.
2. Процедура ЧтениеТХТФайла(Элемент) - Назначение: В цикле произвести последовательное чтение строк файла текстового документа, разбирая на массив колонок данных и добавляя значения массива в табличное поле;
Исходный код 1С функции создания текстового потока чтения файла ТХТ:
В данном примере была произведена загрузка из текстового файла в следующем формате:
В статье приведены полезные приемы при работе с запросами 1С v.8.2, а также сведения, которые не так хорошо известны о языке запросов. Я не стремлюсь дать полное описание языка запросов, а хочу остановиться лишь на некоторых моментах, которые для кого-то могут быть полезны.
Итак, начнем. Запрос - это специальный объект в 1С 8.2, который используется для формирования и выполнения запросов к таблицам базы данных в системе. Для выполнения запроса необходимо составить текст запроса, в котором описывается какие таблицы будут использоваться в качестве источников данных запроса, какие нужно выбрать поля, какие применить сортировки и группировки и т.д. Подробнее о запросах можно прочитать в книге "1С 8.2 Руководстве разработчика". Язык запросов 1С 8.2 очень похож синтаксисом на другие SQL языки запросов баз данных, но есть и отличия. Из основных преимуществ встроенного языка запросов стоит отметить разыменование полей, наличие виртуальных таблиц, удобная работа с итогами и нетипизированные поля в запросах. Из недостатков – в качестве выходного поля нельзя использовать запрос, нельзя использовать хранимые процедуры, нельзя преобразовать строку в число.
Приведу сведения и рекомендации по языку запросов по пунктам:
1.Для повышения читабельности запроса и уменьшения количества параметров запроса можно в запросе применять обращение к предопределенным данным конфигурации с помощью литерала ЗНАЧЕНИЕ (ПРЕДСТАВЛЕНИЕЗНАЧЕНИЯ). В качестве представления значений могут использоваться значение перечислений, предопределенные данные справочников, планов видов расчета, планов видов характеристик, планов счетов, пустые ссылки, значения точек маршрута, значения системных перечислений (например, ВидДвиженияНакопления, ВидСчета).
Примеры: ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.Москва) ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.ПустаяСсылка) ГДЕ ТипТовара = ЗНАЧЕНИЕ(Перечисление.ВидыТоваров.Услуга) ГДЕ ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход) ГДЕ ТочкаМаршрута = ЗНАЧЕНИЕ(БизнесПроцесс.Согласование.ТочкаМаршрута.Согласие)
Выражение в скобках всегда начинается со слова в единственном числе (Справочник, Перечисление и т.д.), которое соответствует типу предопределенного значения.
2.Автоупорядочивание в запросе может сильно тормозить процесс. Если сортировка не нужна, лучше вообще ее не использовать. Во многих случаях эффективнее записать сортировку через ключевое слово УПОРЯДОЧИТЬ ПО.
3.Нужно следить, чтобы при использовании псевдонимов не появилось неоднозначное поле. Иначе система не поймет к какому объекту надо обращаться.
Пример запроса с неоднозначным полем: ВЫБРАТЬ Номенклатура.Ссылка, ОстаткиТоваровОстатки.КоличествоОстаток ИЗ Справочник.Номенклатура КАК Номенклатура ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.ОстаткиТоваров.Остатки КАК ОстаткиТоваровОстатки ПО ОстаткиТоваровОстатки.Номенклатура = Номенклатура.Ссылка
Нужно исправить псевдоним таблицы, например, так: «Справочник.Номенклатура КАК Номенклатура1», а «Номенклатура.Ссылка» соответственно исправить на «Номенклатура1.Ссылка».
4.Иногда полезно получать представление ссылочных полей с помощью ключевого слова ПРЕДСТАВЛЕНИЕ наряду со ссылкой для того, чтобы не было повторного обращения к базе данных. Это бывает полезно при выводе результата запроса в таблицу.
Пример: ВЫБРАТЬ ПРЕДСТАВЛЕНИЕ(Документ.Контрагент) КАК Получатель, ПРЕДСТАВЛЕНИЕ(Документ.Основание) ИЗ Документ.РасходнаяНакладная КАК Документ
5.Использование в запросе ВЫРАЗИТЬ(Поле КАК Тип) позволяет убрать лишние таблицы из соединения с полем составного типа данных. Тем самым ускорить выполнение запроса.
Пример (регистратор - поле с составным типом для физической таблицы регистранакопления ОстаткиТоваров, в запросе выбираются Дата и Номер документов ПоступлениеТоваров, при этом при обращении к реквизитам документа Дата и Номер через Регистратор не происходит множественного соединения таблицы регистра с таблицами документов, являющихся регистраторами для регистра ОстаткиТоваров): ВЫБРАТЬ РАЗЛИЧНЫЕ [b] ВЫРАЗИТЬ(ОстаткиТоваров.Регистратор КАК Документ.ПоступлениеТоваров).Номер КАК НОМЕРПОСТУПЛЕНИЯ,[/b] [b]ВЫРАЗИТЬ(ОстаткиТоваров.Регистратор КАК Документ.ПоступлениеТоваров).Дата КАК ДАТАПОСТУПЛЕНИЯ[/b] [b]ИЗ РегистрНакопления.ОстаткиТоваров КАК ОстаткиТоваровГДЕ (ВЫРАЗИТЬ(ОстаткиТоваров.Регистратор КАК Документ.ПоступлениеТоваров) ЕСТЬ НЕ NULL)[/b]
6.Когда в конфигурации 1С есть пользователи, у которых права ограничены на определенные объекты конфигурации, в запросе к таким объектам необходимо использовать ключевое слово РАЗРЕШЕННЫЕ, чтобы запрос выполнился без ошибки (Выбрать Разрешенные ...)
7.При объединении таблиц, содержащих вложенные таблицы (например, Документ с табличной частью) бывает полезно ключевое слово ПУСТАЯТАБЛИЦА, когда, например, в одном из документов нет табличной части.
Пример: ВЫБРАТЬ Ссылка.Номер, ПУСТАЯТАБЛИЦА.(Ном, Тов, Кол) КАК Состав ИЗ Документ.РасходнаяНакладная ОБЪЕДИНИТЬ ВСЕ ВЫБРАТЬ Ссылка.Номер, Состав.(НомерСтроки, Номенклатура, Количество) ИЗ Документ.РасходнаяНакладная
8.При работе с соединениями таблиц, содержащих по одной строке, бывает нужно склеить строки таблиц (при этом в обеих таблицах нет такого поля, по которому их можно было соединить). Этого можно добиться, применив конструкцию «ПОЛНОЕ СОЕДИНЕНИЕ Таблица По ИСТИНА». Если в таблицах больше, чем одна строка, то в результате будет количество строк, равное произведению количества строк обеих таблиц. Если в одной таблице О строк, то в результирующей таблице количество строк будет равно количеству строк второй таблицы. Также для соединения таких таблиц можно применять декартово произведение таблиц , при котором в результирующей таблице будут встречаться все комбинации строк из обеих таблиц. Надо помнить, что если в одной из таблиц 0 строк, тогда и декартово произведение будет 0, поэтому полное соединение будет лучше. Вообще вместо полного соединения ПО ИСТИНА можно использовать и любой другой тип соединения, но в таком случае тоже возможна ситуация, когда в результирующей таблице будет 0 строк, даже если в одной из таблиц будет ненулевое количество строк. В случае полного соединения такая ситуация будет только в одном случае, если количество строк в обеих таблицах равно 0. Если знать, что в таблице есть точно хотя бы одна строка, тогда можно использовать и ЛЕВОЕ СОЕДИНЕНИЕ с другой таблицей с условием ПО ИСТИНА.
Пример (правда надуманный, для Полного соединения): ВЫБРАТЬ Первые 1 Пол.Ссылка, К.Контрагент ИЗ Перечисление.Пол КАК Пол ПОЛНОЕ СОЕДИНЕНИЕ (Выбрать Первые 1 Д.Контрагент ИЗ Документ.РеализацияТоваров КАК Д Упорядочить По Д.МоментВремени ) КАК К ПО (ИСТИНА)
9. Для того чтобы получить уникальные записи по какому-то полю, правильней вместо группировки пользоваться ключевым словом РАЗЛИЧНЫЕ в запросе, потому что такая конструкция намного наглядней и ключевое слово СГРУППИРОВАТЬ ПО имеет более широкое применение и часто используется, если дополнительно надо рассчитать агрегатные функции по группировкам. В некоторых случаях необходимо вывести ограниченное количество строк. Для этого в описании запроса в описании запроса следует указать ключевое слово ПЕРВЫЕ и после него – требуемое количество строк.
Пример для ПЕРВЫЕ: Выбрать Первые 5 Справочник.Номенклатура.Наименование, Справочник.Номенклатура.ЗакупочнаяЦена Упорядочить По Справочник.Номенклатура.ЗакупочнаяЦена Убыв
Пример для РАЗЛИЧНЫЕ: Выбрать Различные Документ.Расходная.Контрагент
10.Агрегатные функции в запросе можно использовать без ключевого слова СГРУППИРОВАТЬ. В таком случае все результаты будут сгруппированы в одну строку.
Пример: Выбрать Сумма(Накладная.Сумма) Как Сумма Из Документ.РасходнаяНакладная.Состав Как Накладная
11.В запросах в полях выборки можно свободно обращаться к реквизитам полей выборки. Эта возможность называется разыменованием полей выборки. Если источник данных - вложенная таблица (табличная часть документа), то в полях выборки можно обращаться также к полям основной таблицы (например, через поле Ссылка обратиться к полю основной таблицы Контрагент)
Пример: ВЫБРАТЬ [b] ПоступлениеТоваровИУслугТовары.Номенклатура, ПоступлениеТоваровИУслугТовары.Номенклатура.Код, ПоступлениеТоваровИУслугТовары.Количество КАК Количество, ПоступлениеТоваровИУслугТовары.Ссылка.КонтрагентИЗ Документ.ПоступлениеТоваровИУслуг.Товары КАК ПоступлениеТоваровИУслугТоварыГДЕ ПоступлениеТоваровИУслугТовары.Ссылка = &Ссылка[/b]
Есть одна особенность использования разыменования полей, если в запросе есть группировки. В любых запросах с группировками в списках полей запроса можно свободно обращаться к реквизитам группировочных полей.
Пример: ВЫБРАТЬ ПоступлениеТоваровИУслугТовары.Номенклатура, ПоступлениеТоваровИУслугТовары.Номенклатура.Код, СУММА(ПоступлениеТоваровИУслугТовары.Количество) КАК Количество, ПоступлениеТоваровИУслугТовары.Ссылка.Контрагент, ПоступлениеТоваровИУслугТовары.Ссылка.Дата ИЗ Документ.ПоступлениеТоваровИУслуг.Товары КАК ПоступлениеТоваровИУслугТовары ГДЕ ПоступлениеТоваровИУслугТовары.Ссылка = &Ссылка СГРУППИРОВАТЬ ПО ПоступлениеТоваровИУслугТовары.Номенклатура, ПоступлениеТоваровИУслугТовары.Ссылка
В справке 1С написано, что при наличии группировки, в полях выборки запроса могут участвовать только группировочные поля и агрегатные функции по полям выборки. Есть один исключительный случай, когда агрегатные функции применены к полям вложенной таблицы. В этом случае в списке полей выборки возможны обращения к полям таблицы верхнего уровня, без группировки результатов по этим полям.
Пример: ВЫБРАТЬ ПоступлениеТоваровИУслуг.Товары.(СУММА(Количество),Номенклатура), ПоступлениеТоваровИУслуг.Ссылка, ПоступлениеТоваровИУслуг.Контрагент ИЗ Документ.ПоступлениеТоваровИУслуг КАК ПоступлениеТоваровИУслуг СГРУППИРОВАТЬ ПО ПоступлениеТоваровИУслуг.Товары.(Номенклатура)
12. Иногда вместо указания какого-либо поля в группировке полезно в поля выборки запроса включить параметр: ВЫБРАТЬ ДокТовары.Номенклатура, &Контрагент, &Период, СУММА(ДокТовары.Количество * ДокТовары.К) КАК Количество, СУММА(ДокТовары.Сумма) КАК СуммаИЗ Документ.Приходная.Товары КАК ДокТоварыГДЕ ДокТовары.Ссылка = &Ссылка СГРУППИРОВАТЬ ПО ДокТовары.Номенклатура
А затем установить параметр в тексте запроса: Запрос.УстановитьПараметр(«&Контрагент», ВыбКонтрагент); Запрос.УстановитьПараметр(«&Период», Дата);
13. В универсальных запросах параметры можно использовать в описании источников данных запроса, в условиях ГДЕ, в условиях соединения таблиц и параметрах виртуальных таблиц. Существует два приема для создания универсальных запросов:
А) с помощью механизма конкатенации строк, добавляя в текст запроса переменные;
Пример1: ТипУпорядочивания = ?(НЕКАЯПЕРЕМЕННАЯ,"","УБЫВ"); Запрос.Текст= "Выбрать ... Упорядочить ПО Поле1 " + ТипУпорядочивания + "...";
Пример2: Запрос.Текст = "Выбрать Поле1..."; Если НЕКАЯПЕРЕМЕННАЯ = 1 Тогда Запрос.Текст = Запрос.Текст + ",Поле2 ..."; КонецЕсли;
Б)использовать параметры в различных частях запроса (например, в секции источников данных запроса), а затем метод встроенного языка - СТРЗАМЕНИТЬ(). При проектировании универсальных запросов полезно обращение к свойству объектов МЕТАДАННЫЕ(), с помощью которого можно определить название таблицы для какой-то ссылки (например, для документа будет примерно так - Ссылка.МЕТАДАННЫЕ().ИМЯ), переданной через параметр в некую универсальную процедуру.
Пример: Выбрать ДокТЧ.Номенклатура, ... ИЗ &НекийДокТЧ КАК ДокТЧ
А затем установить параметр в тексте запроса Запрос.Текст = СтрЗаменить(Запрос.Текст, "&НекийДокТЧ", "Документ."+Ссылка.Метаданные().Имя+".Товары");
Параметры можно использовать в условиях запроса, чтобы включить опциональное условие &Параметр ИЛИ НЕ КакоеТоСвойство: Запрос.УстановитьПараметр(“&Параметр”, “Контрагент.Наименование=””Иванов”””);
С помощью литерала ИСТИНА можно убирать определенные фильтры в запросе Запрос.УстановитьПараметр(«&Параметр»,Истина);
14.Очень полезными в конструкторе запросов является команда контекстного меню таблицы - "Переименовать таблицу...", с помощью которого можно придумать некоторое обобщенное имя для источника данных. Для создания запросов к однотипным таблицам, похожим по структуре, бывает полезным для второй таблицы скопировать текст запроса первой таблицы, зайти в окно конструктора запросов и в контекстном меню таблицы выбрать пункт - Заменить таблицу... и выбрать вторую талицу.
15.При работе с созданием вложенных запросов в секциях условий или параметров виртуальных таблиц конструктора запросов используется прием выделения пробела в скобках, тогда появляется в контекстном меню пункт «Конструктор запроса», а при редактировании вложенного запроса в условии выделяют весь запрос в скобках .
Пример вложенного запроса: Товар В ( Выбрать Номенклатура ...)
16. При проектировании отчетов СКД в запросах к регистрам остатков - в качестве параметра Период удобнее и правильнее использовать выражение ДобавитьКДате(КонецПериода(Период,ДЕНЬ),СЕКУДА,1), так как остатки в виртуальных получаются на начало периода, не включая последнюю секунду. Прием +1 секунда не может быть применен с документами: по новой методике проведения документов остатки по регистру надо получать на Период, заданный объектом Граница с моментом времени документа включая (а не на дату документа +1 секунда!), а по старой методике проведения - на момент времени документа (а не на дату документа !). При анализе оборотов или данных за период удобно добавлять параметр с типом СтандартныйПериод (в этом случае не надо приводить последнюю дату интервала на конец дня). У стандартного поля «НачалоПериода» в поле «Выражение» надо прописать «&Период.ДатаНачала». А у стандартного поля «КонецПериода» в поле «Выражение» прописать «&Период.ДатаОкончания». Очень много полезной информации по языку запросов можно найти не в синтакс-помощнике, а в полной справке конфигуратора 1С 8.2 (кнопка F1)
17.Функция запроса ЕстьNull (удобнее писать англоязычный вариант IsNull) обычно используется для избавления от значений типа Null для числовых полей запроса. В ряде случаев, например полного соединения двух таблиц функция IsNull (Параметр1,Параметр2) может с успехом заменить конструкцию ВЫБОР КОГДА ... ТОГДА ..ИНАЧЕ ….КОНЕЦ, когда для какого-либо поля значения NULL могут быть как в первой таблице, так и во второй (такая конструкция позволяет получать не Null значение для поля). Но надо помнить, что в отличие от условного оператора ВЫБОР функция ЕстьNull приводит тип второго аргумента к типу первого аргумента, что нужно учитывать, если типы аргументов отличаются!
Пример: IsNull(Рег.Остаток,0) IsNull(Док.Товар,Док1.Номенклатура)
18. У условной конструкции ВЫБОР есть альтернативный синтаксис для простого случая проверки равенства определенному значению, но, правда, он недокументированный: Выбор Выражение Когда 1 Тогда «Высший» Когда 2 Тогда «Средний» Иначе «Низший» Конец
19.Оператор проверки значения на NULL Eсть Null (Можно рекомендовать использовать англоязычный вариант Is Null). Такая конструкция появилась потому, что любая операция сравнения двух величин, хотя бы одно из которых Null, всегда ложь. Написать Где Наименование = Null неправильно. Интересна также форма отрицания данного оператора Не Есть Null - неправильно, а правильно Есть Не Null или форма Не (Поле1 Есть Null) - это существенное отличие от всех операторов, использующихся совместно с оператором Не.
20. Иногда полезна форма оператора В для проверки совпадения с одним из перечисленных значений.
Пример: ...Где Товар.Наименование В ("Бытовая техника","Компьютеры")
Для справочников может быть полезна форма оператора В проверки принадлежности по иерархии.
Пример: ...Где Номенклатура В ИЕРАРХИИ (&Группа)
Оператор В часто используется для проверки вхождения значения в результат вложенного запроса.
Пример: ...Где Номенклатура.Ссылка В (Выбрать Номенклатура.Ссылка ...).
Во вложенном запросе можно обращаться к полям внешнего запроса в условии.
Пример: // Выбрать названия товаров, которые присутствовали // в расходных накладных ВЫБРАТЬ Товары.Наименование ИЗ Справочник.Номенклатура КАК Товары ГДЕ Товары.Ссылка В (ВЫБРАТЬ РасходнаяНакладнаяСостав.Номенклатура ИЗ Документ.РасходнаяНакладная.Состав КАК РасходнаяНакладнаяСостав ГДЕ РасходнаяНакладнаяСостав.Номенклатура = Товары.Ссылка)
Операция В может использоваться с массивами, списками значений, таблицами значений, вложенными запросами. При этом возможно сокращение условий
Синтаксис для вложенного запроса (выражение1, выражение2,...,выражениеN) В (Выбрать выражение1, выражение2,...,выражениеN ...)
Синтаксис для таблицы значений (выражение1, выражение2,...,выражениеN) В (&ТЗ), где в таблице значений ТЗ используются N первых колонок
20. В интернете есть шутка по поводу того, как конструктор запроса постоянно делает ЛЕВОЕ соединение таблиц (и меняет их местами), как бы мы не указывали ПРАВОЕ: 1С:Предприятие любит «налево».
21. Сложные запросы удобно отлаживать в консоли запросов. Существует их в интернете много. После отладки запроса его можно скопировать и в конструкторе запроса есть замечательная кнопка «Запрос», куда можно вставить его в том же виде и сохранить (раньше была только возможность скопировать в конфигураторе и сделать форматирование запроса посредством символа переноса строки). В окне, которое открывается при нажатии кнопки «Запрос», можно редактировать запрос и смотреть результат выполнения, что довольно удобно.
22.При проектировании отчетов СКД нужно помнить, что если нужно обеспечить фильтрацию по некоторому полю, необязательно добавлять параметр в текст запроса. У конструктора запросов есть вкладка «Компоновка данных», где можно добавлять параметры в условия. Кроме того, на уровне отчета СКД есть закладка условия, где можно добавлять произвольные условия и сохранять в быстрых настройках. В таком случае условия будут универсальными (равенство, неравенство, принадлежность, вхождение в список и т.д.).
23. При работе с документами бывает нужно добавить сортировку по виртуальному полю таблицы МОМЕНТВРЕМЕНИ, но вот незадача - во вложенных запросах сортировка по этому полю правильно не работает. Помогают танцы с бубнами: сортировка по виртуальному полю МОМЕНТВРЕМЕНИ заменяется на две сортировки: по дате и по ссылке. Также решить проблему можно через временную таблицу переносом вложенного запроса в отдельный запрос. На протяжении уже многих релизов данная фича или баг не исправлена.
Пример неправильно работающего запроса, получающего последний проведенный документ по указанному контрагенту (вернее, табличную часть документа): ВЫБРАТЬ РасходнаяТовары.Ссылка, РасходнаяТовары.НомерСтроки, РасходнаяТовары.Товар, РасходнаяТовары.Количество, РасходнаяТовары.Цена, РасходнаяТовары.Сумма ИЗ Документ.Расходная.Товары КАК РасходнаяТовары ГДЕ РасходнаяТовары.Ссылка В (ВЫБРАТЬ ПЕРВЫЕ 1 Д.Ссылка ИЗ Документ.Расходная КАК Д ГДЕ Д.Ссылка.Проведен И Д.Контрагент = &Контрагент УПОРЯДОЧИТЬ ПО Д.Ссылка.МоментВремени УБЫВ)
Возможные решения:
A) Заменить на УПОРЯДОЧИТЬ ПО на УПОРЯДОЧИТЬ ПО Д.Дата УБЫВ УПОРЯДОЧИТЬ ПО Д.Ссылка УБЫВ
Б) Можно перенести вложенный запрос во временную таблицу: ВЫБРАТЬ ПЕРВЫЕ 1 Д.Ссылка ПОМЕСТИТЬ ТЗСсылка ИЗ Документ.Расходная КАК Д ГДЕ Д.Ссылка.Проведен И Д.Контрагент = &Контрагент УПОРЯДОЧИТЬ ПО Д.Ссылка.МоментВремени УБЫВ ; //////////////////////////////////////////////////////////////////////////////// ВЫБРАТЬ РасходнаяТовары.Ссылка, РасходнаяТовары.НомерСтроки, РасходнаяТовары.Товар, РасходнаяТовары.Количество, РасходнаяТовары.Цена, РасходнаяТовары.Сумма ИЗ Документ.Расходная.Товары КАК РасходнаяТовары ГДЕ РасходнаяТовары.Ссылка В (ВЫБРАТЬ Т.Ссылка ИЗ ТЗСсылка КАК Т)
В) Можно обратиться к основной таблице документа, а уже затем к табличной части ВЫБРАТЬ ПЕРВЫЕ 1 Расходная.Ссылка, Расходная.Товары.( Ссылка, НомерСтроки, Товар, Количество, Цена, Сумма ) ИЗ Документ.Расходная КАК Расходная ГДЕ Расходная.Контрагент = &Контрагент И Расходная.Проведен УПОРЯДОЧИТЬ ПО Расходная.МоментВремени УБЫВ
24. При обращении к главной таблице документа(справочника) можно в условии обратиться к данным подчиненной таблицы (табличной части). Такая возможность называется разыменование полей табличной части. В качестве примера задачи можно привести задачу поиска документов, содержащих в табличной части определенный товар.
Пример: Выбрать Приходная.Ссылка ИЗ Документ.Приходная Где Приходная.Товары.Номенклатура = &Номенклатура.
Преимущество этого запроса перед запросом ко вложенной таблице Приходная.Товары в том, что если есть дубли в документах , результат запроса вернет только уникальные документы без использования ключевого слова РАЗЛИЧНЫЕ.
Сравните: Выбрать Различные Товары.Ссылка ИЗ Документ.Приходная.Товары как Товары Где Товары.Номенклатура = &Номенклатура.
На этом месте, пожалуй, всё. Понятно, что в языке запросов ещё много неосвещенных мной вопросов. Для написания статьи была использована информация, полученная мной после прохождения базового курса 1С 8.2 spec8.ru, а также из книги «1С 8.2 Руководство разработчика» и просторов интернета.
Всем спасибо!
Автор: fpat
 Отправка почты через Mail.ru с использованием технологии шифрования SSL
Отправка почты через Mail.ru с использованием технологии шифрования SSL  , остается использовать stunnel или CDO:
, остается использовать stunnel или CDO:
.gif)







 Менеджеры, кто как хотел - так и изменял номера документов. с префиксом, без, писали даже б/н. Но тут пришел новый бухгалтер и сказал - нужно с 1 октября запустить авто нумерацию с номера 00010000, но старые счета не трогать!
Менеджеры, кто как хотел - так и изменял номера документов. с префиксом, без, писали даже б/н. Но тут пришел новый бухгалтер и сказал - нужно с 1 октября запустить авто нумерацию с номера 00010000, но старые счета не трогать!






 Структура конфигурации представлена на рисунке справа:
Структура конфигурации представлена на рисунке справа: 





















