Есть много примеров кода 1с для определения строки состоящей только из цифр. Как правило, это цикл с перебором значений строки. Предлагаю еще один без циклов, с использованием регулярных выражений
Если в строке только цифры, результат = 1, если нет - 0
Для формирования и выполнения запросов к таблицам базы данных в платформе 1С используется специальный объект языка программирования Запрос. Создается этот объект вызовом конструкции Новый Запрос. Запрос удобно использовать, когда требуется получить сложную выборку данных, сгруппированную и отсортированную необходимым образом. Классический пример применения запроса - получение сводки по состоянию регистра накопления на определенный момент времени. Так же, механизм запросов позволяет легко получать информацию в различных временных разрезах.
Текст запроса – это инструкция, в соответствии с которой должен быть выполнен запрос. В тексте запроса описывается:
таблицы информационной базы, используемые в качестве источников данных запроса;
поля таблиц, которые требуется обрабатывать в запросе;
правила группировки;
сортировки результатов;
и т. д.
Инструкция составляется на специальном языке – языке запросов и состоит из отдельных частей – секций, предложений, ключевых слов, функций, арифметических и логических операторов, комментариев, констант и параметров.
Язык запросов платформы 1С очень похож на синтаксис других SQL-языков, но имеются отличия. Основными преимуществами встроенного языка запросов являются: разыменование полей, наличие виртуальных таблиц, удобная работа с итогами, нетипизированные поля в запросах.
Рекомендации по написанию запросов к базе данных на языке запросов платформы 1С:
1) Текст запроса может содержать предопределенные данные конфигурации, такие как:
значения перечислений;
предопределенные данные:
справочников;
планов видов характеристик;
планов счетов;
планов видов расчетов;
пустые ссылки;
значения точек маршрута бизнес-процессов.
Также текст запроса может содержать значения системных перечислений, которые могут быть присвоены полям в таблицах базы данных: ВидДвиженияНакопления, ВидСчета и ВидДвиженияБухгалтерии. Обращение в запросах к предопределенным данным конфигурации и значениям системных перечислений осуществляется с помощью литерала функционального типа ЗНАЧЕНИЕ. Данный литерал позволяет повысить удобочитаемость запроса и уменьшить количество параметров запроса.
Пример использования литерала ЗНАЧЕНИЕ:
ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.Москва)
ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.ПустаяСсылка)
ГДЕ ТипТовара = ЗНАЧЕНИЕ(Перечисление.ВидыТоваров.Услуга)
ГДЕ ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
ГДЕ ТочкаМаршрута = ЗНАЧЕНИЕ(БизнесПроцесс.БизнесПроцесс1.ТочкаМаршрута.Действие1
2) Использование инструкции АВТОУПОРЯДОЧИВАНИЕ в запросе может сильно время выполнения запроса, поэтому, если сортировка не требуется, то лучше вообще ее не использовать. Во большинстве случаях лучше всего применять сортировку с помощью инструкции УПОРЯДОЧИТЬ ПО.
Автоупорядочивание работает по следующим принципам:
Если в запросе было указано предложение УПОРЯДОЧИТЬ ПО, то каждая ссылка на таблицу, находящаяся в этом предложении, будет заменена полями, по которым по умолчанию сортируется таблица (для справочников это код или наименование, для документов – дата документа). Если поле для упорядочивания ссылается на иерархический справочник, то будет применена иерархическая сортировка по этому справочнику.
Если в запросе отсутствует предложение УПОРЯДОЧИТЬ ПО, но есть предложение ИТОГИ, тогда результат запроса будет упорядочен по полям, присутствующим в предложении ИТОГИ после ключевого слова ПО, в той же последовательности и, в случае если итоги рассчитывались по полям – ссылкам, то по полям сортировки по умолчанию таблиц, на которые были ссылки.
Если в запросе отсутствуют предложения УПОРЯДОЧИТЬ ПО и ИТОГИ, но есть предложение СГРУППИРОВАТЬ ПО, тогда результат запроса будет упорядочен по полям, присутствующим в предложении, в той же последовательности и, в случае если группировка велась по полям – ссылкам, то по полям сортировки по умолчанию таблиц, на которые были ссылки.
В случае же, если в запросе отсутствуют предложения и УПОРЯДОЧИТЬ ПО, ИТОГИ и СГРУППИРОВАТЬ ПО, результат будет упорядочен по полям сортировки по умолчанию для таблиц, из которых выбираются данные, в порядке их появления в запросе.
В случае, если запрос содержит предложение ИТОГИ, каждый уровень итогов упорядочивается отдельно.
3) Что бы избежать повторного запроса к базе данных при выводе результата запроса пользователю (например, построение запроса или отображение результата запроса с помощью табличного документа) полезно использовать инструкцию ПРЕДСТАВЛЕНИЕССЫЛКИ, которая позволяет получать представление ссылочного значения. Пример:
Так же возможно использование инструкции ПРЕДСТАВЛЕНИЕ - предназначена для получения строкового представления значения произвольного типа. Отличие этих инструкций в том, что в первом случае, если инструкции передать ссылку, результатом будет строка, В остальных случаях результатом будет значение переданного параметра. Во втором случае, результатом инструкции всегда будет строка!
4) Если в запросе имеется поле с составным типом, то для таких полей возникает необходимость привести значения поля к какому-либо определенному типу с помощью инструкции ВЫРАЗИТЬ, что позволит убрать лишние таблицы из левого соединения с полем составного типа данных и ускорить выполнение запроса. Пример:
Имеется регистра накопления ОстаткиТоваров, у которого поле Регистратор имеет составной тип. В запросе выбираются Дата и Номер документов ПоступлениеТоваров, при этом при обращении к реквизитам документа через поле Регистратор не происходит множество левых соединений таблицы регистра накопления с таблицами документов-регистраторов.
Если приведение типа считается не осуществимым, то результатом приведения типа будет значение NULL.
5) Не стоит забывать про инструкцию РАЗРЕШЕННЫЕ, которая означает, что запрос выберет только те записи, на которые у текущего пользователя есть права. Если данное слово не указать, то в случае, когда запрос выберет записи, на которые у пользователя нет прав, запрос отработает с ошибкой.
6) В случае, если в запросе используется объединение, и в некоторых частях объединения присутствуют вложенные таблицы (документ с табличной частью), а в некоторых нет, возникает необходимость дополнения списка выборки полями – пустыми вложенными таблицами. Делается это при помощи ключевого слова ПУСТАЯТАБЛИЦА, после которого в скобках указываются псевдонимы полей, из которых будет состоять вложенная таблица. Пример:
7) Что бы в результат запроса не попали повторяющиеся строки, следует использовать инструкцию РАЗЛИЧНЫЕ, потому что так нагляднее и понятнее, а инструкция СГРУППИРОВАТЬ ПО применяется для группировки с помощью агрегатных функций. Ксати, при использовании агрегатных функций предложение СГРУППИРОВАТЬ ПО может быть и не указано совсем, при этом все результаты запроса будут сгруппированы в одну единственную строку. Пример:
8) Инструкция СГРУППИРОВАТЬ ПО позволяет обращаться к полям верхнего уровня, без группировки результатов по этим полям, если агрегатные функции применены к полям вложенной таблицы. Хотя в справке 1С написано, при группировке результатов запроса в списке полей выборки обязательно должны быть указаны агрегатные функции, а помимо агрегатных функций в списке полей выборки допускается указывать только поля, по которым осуществляется группировка. Пример:
9) Инструкция ЕСТЬNULL предназначена для замены значения NULL на другое значение, но не забываем, что второй параметр будет преобразован к типу первого в случае, если тип первого параметра является строкой или числом.
10) При обращении к главной таблице можно в условии обратиться к данным подчиненной таблицы. Такая возможность называется разыменование полей подчиненной таблицы.
Пример (поиск документов, содержащих в табличной части определенный товар):
Преимущество этого запроса перед запросом к подчиненной таблице Приходная.Товары в том, что если есть дубли в документах, результат запроса вернет только уникальные документы без использования ключевого слова РАЗЛИЧНЫЕ.
11) Интересный вариант оператора В - это проверка вхождения упорядоченного набора в множество таких наборов (Поле1, Поле2, ... , ПолеN) В (Поле1, Поле2, ... , ПолеN).
Пример:
12) При любой возможности используйте виртуальные таблицы запросов. При создании запроса система предоставляет в качестве источников данных некоторое количество виртуальных таблиц - это таблицы, которые так же являются результатом запроса, который система формирует в момент выполнения соответствующего участка кода.
Разработчик может самостоятельно получить те же самые данные, которые система предоставляет ему в качестве виртуальных таблиц, однако алгоритм получения этих данных не будет оптимизирован, так как:
Все виртуальные таблицы параметризованы, т. е. разработчику предоставляется возможность задать некоторые параметры, которые система будет использовать при формировании запроса создания виртуальной таблицы. В зависимости от того, какие параметры виртуальной таблицы указаны разработчиком, система может формировать РАЗЛИЧНЫЕ запросы для получения одной и той же виртуальной таблицы, причем они будут оптимизированы с точки зрения переданных параметров.
Не всегда разработчик имеет возможность получить доступ к тем данным, к которым имеет доступ система.
13) В клиент-серверном варианте работы функция ПОДСТРОКА() реализуется при помощи функции SUBSTRING() соответствующего оператора SQL, передаваемого серверу баз данных SQL Server, который вычисляет тип результата функции SUBSTRING() по сложным правилам в зависимости от типа и значений ее параметров, а так же в зависимости от контекста, в котором она используется. В большинстве случаев эти правила не оказывают влияния на выполнение запроса, но бывают случаи, когда для выполнения запроса существенна максимальная длина строки результата, вычисленная SQL Server. Важно иметь в виду, что в некоторых контекстах использования функции ПОДСТРОКА() максимальная длина ее результата может оказаться равной максимальной длине строки ограниченной длины, которая в SQL Server равна 4000 символам. Это может привести к неожиданному аварийному завершению выполнения запроса:
Microsoft OLE DB Provider for SQL Server: Warning: The query processor could not produce a query plan from the optimizer because the total length of all the columns in the GROUP BY or ORDER BY clause exceeds 8000 bytes.
HRESULT=80040E14, SQLSTATE=42000, native=8618
Чтобы избежать такой ошибки, не рекомендуют использовать функцию ПОДСТРОКА() с целью приведения строк неограниченной длины к строкам ограниченной длины. Вместо нее лучше использовать операцию приведения типа ВЫРАЗИТЬ().
14) С осторожностью используйте ИЛИ в конструкции ГДЕ, так как использование условия с ИЛИ может значительно "утяжелить" запрос. Решить проблему можно конструкцией ОБЪЕДИНИТЬ ВСЕ. Пример:
15) Условие НЕ В в конструкции ГДЕ увеличивает время исполнения запроса, так как это своего рода НЕ (ИЛИ1 ИЛИ2 ... ИЛИn), поэтому для больших таблиц старайтесь использовать ЛЕВОЕ СОЕДИНЕНИЕ с условием ЕСТЬ NULL. Пример:
16) При использовании Временных таблиц нужно индексировать поля условий и соединений в этих таблицах, НО, при использовании индексов запрос может выполняться еще медленнее. Поэтому необходимо анализировать каждый запрос с применением индекса и без, замерять скорость выполнения запроса и принимать окончательное решение.
Если вы помещаете во временную таблицу данные, которые изначально индексированы по некоторым полям, то во временной таблице индекса по этим полям уже не будет.
17) Если вы не используете Менеджер временных таблиц, то явно удалять временную таблицу не требуется, она будет удалена после завершения выполнения пакетного запроса, иначе следует удалить временную таблицу одним из способов: командой УНИЧТОЖИТЬ в запросе, вызвать метод МенеджерВременныхТаблиц.Закрыть().
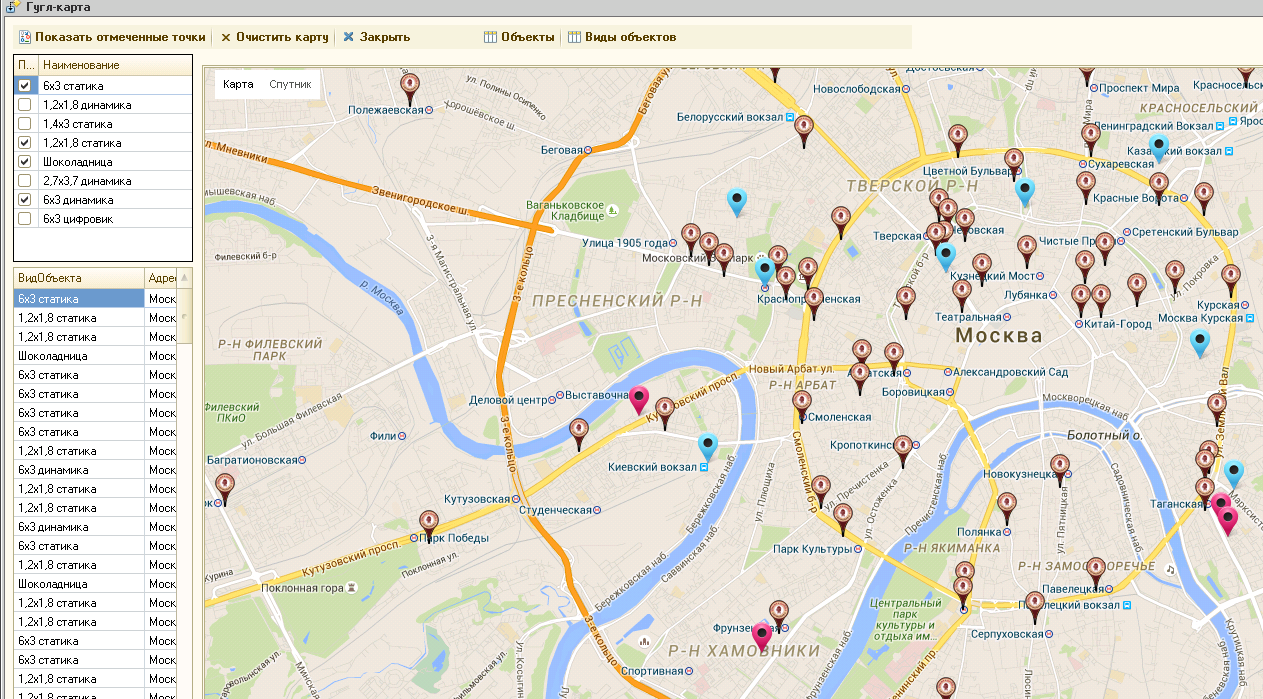
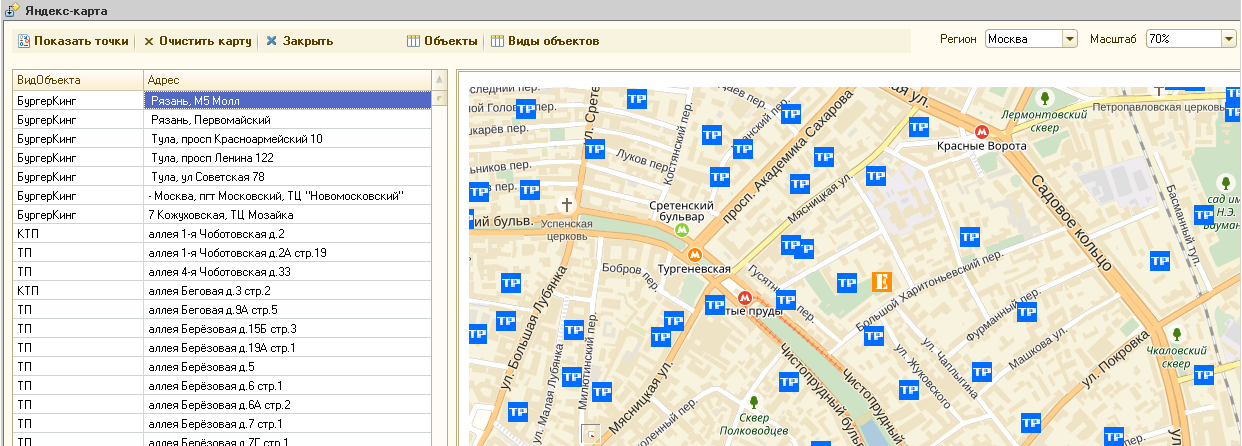
В отличие от яндекс карт в GMaps можно использовать панорамы - за что им большой плюс! Надеюсь в яндексе прочитают этот пост и тоже когда-нибудь это сделают!
Для клиента нужно было сделать вывод объектов на карту
Полнотекстовый поиск - позволит найти текстовую информацию, размещенную практически в любом месте используемой конфигурации. При этом искать нужные данные можно либо по всей конфигурации в целом, либо сузив область поиска до нескольких объектов (например, определенных видов документов или справочников). Сами критерии поиска могут варьироваться в довольно широком диапазоне. То есть найти нужные данные можно, даже не помня точно, где они хранятся в конфигурации и как именно записаны.
Полнотекстовый поиск предоставляет следующие возможности:
Есть поддержка транслитерации (написание русских слов символами латиницы в соответствии с ГОСТ 7.79-2000). Пример: "русская фраза" = "russkaya fraza".
Есть поддержка замещения (написание части символов в русских словах одноклавишными латинскими символами). Пример: "руссrfz фраpf" (окончания каждого слова набраны латиницей, допустим, в результате ошибки оператора).
Есть возможность нечеткого поиска (буквы в найденных словах могут отличаться) с указанием порога нечеткости. Пример: указав в строке поиска слово "привет" и нечеткость 17 %, найдем все аналогичные слова с ошибками и без: "привет", "превет", "привед".
Есть возможность указать область выполнения поиска по выбранным объектам метаданных.
Полнотекстовое индексирование названий стандартных полей ("Код", "Наименование" и т. д.) производится на всех языках конфигурации.
Поиск выполняется с учетом синонимов русского, английского и украинского языков.
Морфологический словарь русского языка содержит ряд специфических слов, относящихся к областям деятельности, автоматизируемым с помощью системы программ "1С:Предприятие".
Стандартно в состав поставляемых словарей включены словарные базы и словари тезауруса и синонимов русского, украинского и английского языков, которые предоставлены компанией "Информатик".
Поиск можно осуществлять с использованием подстановочных символов ("*"), а также с указанием поисковых операторов ("И", "ИЛИ", "НЕ", "РЯДОМ") и спецсимволов.
Полнотекстовый поиск можно осуществлять в любой конфигурации на платформе 1С:Предприятие 8
Для того чтобы открыть окно управления полнотекстовым поиском необходимо выполнить следующее:
Обычное приложение - пункт меню Операции - Управление полнотекстовым поиском.
Управляемое приложение - пункт меню Главное меню - Все функции - Стандартные - Управление полнотекстовым поиском.
Обновить индекс – Создание индекса/Обновление индекса;
Очистить индекс – обнуление индекса(рекомендуется после обновления всех данных);
пункт Разрешить слияние индексов – отвечает за слияние основного и дополнительного индекса.
Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.
Как вы можете заметить свойство Использовать установлено для всего справочника Контрагенты, но сделать это можно и для каждого его реквизита соответствующего типа.
Рассмотрим более подробно полнотекстовый индекс, который состоит из двух частей (индексов): основного индекса и дополнительного. Высокая скорость поиска данных обеспечивается за счет основного индекса, но обновление его происходит относительно медленно, в зависимости от объема данных. Дополнительный индекс ему противоположен. Данные добавляются в него намного быстрее, но поиск осуществляется медленнее. Система осуществляет поиск одновременно в обоих индексах. Большая часть данных находится в основном индексе, а данные добавляемые в систему попадают в дополнительный индекс. Пока объем данных в дополнительном индексе небольшой, поиск по нему происходит относительно быстро. В тот момент, когда нагрузка на систему невелика, происходит операция слияния индексов, в результате чего дополнительный индекс очищается, а все данные помещаются в основной индекс. Слияние индексов предпочтительнее выполнять в тот момент времени, когда нагрузка на систему минимальна. С этой целью можно создавать регламентированные задания и задания по расписанию.
Специальные операторы, допустимые при задании поискового выражения
Механизм полнотекстового поиска допускает написание части символов русского слова одноклавишными латинскими символами. Результат поиска при этом не измениться.
Два оператора РЯДОМ
упрощенный. На расстоянии 8 слов друг от друга
РЯДОМ/[+/-]n – поиск данных в одном реквизите на расстоянии n-1 слов между ними.
Знак указывает в каком направлении от первого слова будет поиск второго. (+ - после, - до)
Групповой символ «*» может использоваться только в качестве замены конца слова
Оператор нечеткости «#». Если неизвестно точное написание названия, имени.
Программными средствами и средствами 1с: программирование.
Оператор синонимов «!». Позволяет найти слово и его синонимы
Как программно обновить индекс полнотекстового поиска?
Пример полнотекстового поиска данных
Определение переменной СписокПоиска
Кроме этого в процедуре обработки события ПриОткрыии формы определим, что эта переменная будет содержать список полнотекстового поиска, с помощью которого мы и будем осуществлять поиск в данных
Теперь для события нажатия на кнопку Найти напишем код, который позволит нам выполнять поиск в соответствии с тем выражением, которое задано в поле ПоисковоеВыражение
Сначала в этой процедуре мы устанавливаем поисковое выражение, введенное пользователем, в качестве строки поиска для полнотекстового поиска. Затем выполняем метод ПерваяЧасть(), который собственно запускает полнотекстовый поиск и возвращает первую порцию результатов. По умолчанию порция содержит 20 элементов. После этого мы анализируем количество элементов в списке поиска. Если он не содержит ни одного элемента, то мы выводим в форму соответствующее сообщение. В противном случае вызывается процедура ВывестиРезультатПоиска(), которая отображает полученные результаты пользователю.
Создадим в модуле формы процедуру с таким именем и напишем в ней код,
Действия, выполняемые в этой процедуре, просты. Сначала мы формируем сообщение о том, какие элементы отображены и сколько всего элементов найдено. Затем получаем результат полнотекстового поиска в виде HTML-текста и выводим этот текст в поле HTML-документа, расположенное в форме.
В заключение передаем управление в процедуру ДоступностьКнопок() для того, чтобы сделать доступными или, наоборот, запретить доступ к кнопкам Предыдущая порция и Следующая порция (в зависимости от того, какая порция полученных результатов отображена). Текст этой процедуры представлен в Коде
Теперь необходимо создать обработчики событий нажатия на кнопки ПредыдущаяПорция() и СледующаяПорция().
Заключительным «штрихом» будет создание обработчика события onclick поля HTML-документа, расположенного в форме. Дело в том, что результат полнотекстового поиска, представленный в виде HTML-текста, содержит гиперссылки на номера элементов списка поиска. И нам хотелось бы, чтобы при переходе пользователя на эту ссылку система открывала бы форму того объекта, который содержится в этом элементе списка. Для этого мы будем перехватывать событие onclick HTML-документа, содержащегося в поле HTML-документа, получать номер элемента списка из гиперссылки и открывать форму соответствующего объекта. Текст обработчика события onclick поля HTML-документа представлен в коде
Для управления регистрацией документа в последовательности документов служит набор записей регистрации в последовательности документов.
У документа есть свойство ПринадлежностьПоследовательностям. Значением свойства является коллекция наборов записей регистрации в последовательности документов. Для каждой последовательности, в которой участвует документ, существует свой собственный экземпляр набора записей. Если у документа стоит режим автоматического заполнения последовательностей, то перед записью документа наборы записей регистрации будут автоматически заполнены. Для последовательностей без измерений набор записей будет содержать только одну запись. Для последовательностей с измерениями число записей зависит от содержания документа и настройки соответствия измерений последовательности реквизитам документа.
Набор записей автоматически заполняется до записи документа и записывается после записи документа в одной транзакции с ним. Это позволяет в обработчиках событий документа ПередЗаписью() и ПриЗаписи() переопределить набор записей регистрации. Так, например, если документ входит в последовательность Последовательность1 и у документа стоит признак автоматического заполнения последовательности, то для того что бы отменить его регистрацию в последовательности в зависимости от значения реквизита документа достаточно в модуль документа вставить обработчик события ПередЗаписью() следующего содержания:
В этом случае если реквизит Регистрировать имеет значение "Ложь", то документ не будет зарегистрирован в последовательности Последовательность1. Кроме отмены регистрации документа в последовательности, доступна возможность написания собственного алгоритма регистрации документа в последовательности. Для этого надо очистить набор записей регистрации и заполнить его новыми записями.
Формат JSON в 1С до версии 8.3.6 не реализован, но нижет я приведу примеры функций которые можно использовать для полноценной работы JSON в 1С предыдущий версий.
JSON (JavaScript Object Notation) это текстовый формат обмена данными, широко используемый в веб-приложениях. По сравнению с XML он является более лаконичным и занимает меньше места. Кроме этого все браузеры имеют встроенные средства для работы с JSON.
Необходимость работы с этим форматом на уровне платформы обусловлена не только тем, что это «модный современный» формат, который прикладные решения 1С:Предприятия сами по себе могут использовать для интеграции со сторонними приложениями. Другая причина заключается ещё и в том, что JSON активно используется в HTTP интерфейсах. А в 1С:Предприятии как раз есть такие механизмы, в которых хочется использовать этот формат. Это REST интерфейс приложения, автоматически генерируемый платформой, и HTTP-сервисы, которые вы можете создавать самостоятельно.
В платформе с версии 8.3.6:
Потоковое чтение и запись JSON:
Объекты потоковой работы - это общие объекты ЧтениеJSON и ЗаписьJSON. Они последовательно читают JSON из файла или строки, или последовательно записывают JSON в файл или строку. Таким образом, чтение и запись JSON происходят без формирования всего документа в памяти.
В качестве иллюстрации потокового чтения JSON можно привести следующий пример:
Результат такой записи:
Сериализация примитивных типов и коллекций в JSON
Вторая группа средств работы с JSON хороша тем, что избавляет вас от рутинной работы по чтению/записи каждого отдельного значения или свойства. При чтении документы JSON отображаются в фиксированный набор типов платформы: Строка, Число, Булево, Неопределено, Массив, ФиксированныйМассив, Структура, ФиксированнаяСтруктура, Соответствие, Дата. Соответственно, в обратную сторону, композиция объектов этих типов позволяет сформировать в памяти и быстро записать в файл структуру JSON. Таким образом, чтение и запись небольшого объема JSON заранее известной структуры можно производить немногими строчками кода.
Основное назначение этих средств мы видим в обмене информацией с внешними системами, чтении конфигурационных файлов в формате JSON.
Сериализацию вы можете выполнять с помощью методов глобального контекста ПрочитатьJSON() и ЗаписатьJSON(). Они работают в связке с объектами ЧтениеJSON и ЗаписьJSON.
В качестве примера десериализации JSON можно рассмотреть чтение массива из двух объектов:
Полностью автоматизировали работу с JSON и реализовали в платформе третью группу средств. Они позволяют сериализовать в JSON прикладные типы 1С:Предприятия: ссылки, объекты, наборы записей и вообще любые типы, для которых поддерживается XDTO сериализация. Конечно же, мы обеспечили и обратную операцию - десериализацию. Зачем это нужно!?
Прежде всего, и в основном, XDTO сериализацию в JSON мы рекомендуем использовать при обмене данными между двумя прикладными решениями 1С:Предприятия. По сравнению с XML формат JSON более компактный, сериализация/десериализация в/из JSON выполняется быстрее. Кроме этого мы предприняли дополнительные меры для того, чтобы сократить объём передаваемых данных.
Кроме обмена между приложениями 1С:Предприятия этот механизм можно использовать и для обмена с внешними системами, готовыми принимать типы данных 1С:Предприятия. Например, XDTO сериализацию в JSON можно использовать для организации собственного HTTP интерфейса прикладного решения. Сервис на платформе 1С:Предприятия будет формировать ответ в памяти в виде строки JSON. А затем передавать её при помощи объекта HTTPСервисОтвет. Реализованный нами механизм сериализации полностью соответствует стандарту JSON. Поэтому внешняя система не должна испытывать каких-либо трудностей с десериализацией.
Использование XDTO сериализации в JSON для других задач видится нам маловероятным. Потому что если внешняя система не готова работать с прикладными типами 1С:Предприятия, то зачем их ей передавать? А если предполагается обмениваться только примитивными типами и коллекциями, то для этой задачи хорошо подходят методы ПрочитатьJSON() и ЗаписатьJSON(). Подробнее здесь
Периодически во встроенном языке возникает необходимость изменения текста запроса в зависимости от разных алгоритмических условий. Раньше подобная задача решалась путём непосредственного формирования нужного текста запроса в виде строки. А это не всегда удобно и зачастую очень громоздко.
Теперь во встроенном языке мы реализовали объектную модель схемы запроса. Вы можете создать пустую схему запроса конструктором и загрузить в неё имеющийся текст запроса. После этого отдельные элементы текста запроса будут доступны вам как свойства объектной модели.
На рисунке ниже стрелки показывают, в каких объектах встроенного языка будут доступны те или иные элементы простого запроса, загруженного в схему:
Редактирование текста запроса с помощью объектной модели позволяет вам проще и понятнее модифицировать имеющиеся запросы. Или даже создавать их во встроенном языке «с нуля». А затем просто получать готовый текст запроса из схемы методом ПолучитьТекстЗапроса().
Связка сервера 1С:Предприятие и PostgreSQL вторая по популярности среди установок 1С и самое используемое решение на платформе Linux. В отличии внедрений на базе Windows и MSSQL, где трудно сделать так, чтобы не заработало, внедрения на базе Linux таят множество подводных камней для неопытного администратора. Часто бывает так, что вроде бы все сделано правильно, но ошибка следует за ошибкой. Сегодня мы рассмотрим самые типовые из них.
Общая информация
Перед тем, как начинать искать ошибки установки и, вообще, приступать к внедрению серверной версии 1С:Предприятия было бы неплохо освежить представление как это работает:
Сервер 1С Предприятия. Часть 1 - Общие вопросы.
В небольших внедрениях сервер 1С и сервер СУБД обычно совмещают на одном физическом сервере, что немного сужает круг возможных ошибок. В нашем случае будет рассматриваться ситуация, когда сервера разнесены по разным машинам. В нашей тестовой лаборатории мы развернули следующую схему:
В нашем распоряжении имеются два сервера под управлением Ubuntu 12.04 x64, на одном из них установлен сервер 1С:Предприятие версии 8.3, на другом PostgreSQL 9.04 от Ethersoft, а также клиент под управлением Windows. Напоминаем, что клиент работает только с сервером 1С, который, в свою очередь, формирует необходимые запросы к серверу СУДБ. Никаких запросов от клиента к серверу управления базами данных не происходит.
Сервер баз данных не обнаруженВАЖНО: пользователь "postgres" не прошёл проверку подлинности (Ident)
Данная ошибка возникает при разнесении серверов по разным ПК из-за неправильно настроеной проверки подлинности в локальной сети. Для устранения откройте /var/lib/pgsql/data/pg_hba.conf, найдите строку:
host all all 192.168.31.0/24 ident[/pre]
и приведите ее к виду:
host all all 192.168.31.0/24 md5[/pre]
где 192.168.31.0/24 - диапазон вашей локальной сети. Если такой строки нет, ее следует создать в секции IPv4 local connections.
Сервер баз данных не обнаруженcould not translate host name "NAME" to address: Temporary failure in name resolution
На первый взгляд ошибка понятна: клиент не может разрешить имя сервера СУБД, типичная ошибка для небольших сетей, где отсутствует локальный DNS-сервер. В качестве решения добавляют запись в файлhosts на клиенте, что не дает никакого результата...
А теперь вспоминаем, о чем было сказано несколько раньше. Клиентом сервера СУБД является сервер 1С, но никак не клиентский ПК, следовательно запись нужно добавлять на сервере 1С:Предприятие в файл/etc/hosts на платформе Linux или в C:\Windows\System32\drivers\etc\hosts на платформе Windows.
Аналогичная ошибка будет возникать, если вы забыли добавить запись типа A для сервера СУБД на локальном DNS-сервере.
Ошибка при выполнении операции с информационной базойserver_addr=NAME descr=11001(0x00002AF9): Этот хост неизвестен.
Как и прошлая, эта ошибка связана с неправильным разрешением клиентом имени сервера. На этот раз именно клиентским ПК. В качестве решения добавляем в файл /etc/hosts на платформе Linux или в C:\Windows\System32\drivers\etc\hosts на платформе Windows запись вида:
192.168.31.83SRV-1C-1204[/pre]
где указываете адрес и имя вашего сервера 1С:Предприятия. В случае использования локального DNS следует добавить A-запись для сервера 1С.
Ошибка СУБД: DATABASE не пригоден для использования
Гораздо более серьезная ошибка, которая говорит о том, что вы установили несовместимую с 1С:Предприятие версию PostgreSQL или допустили грубые ошибки при установке, например не установили все необходимые зависимости, в частности библиотеку libICU.
Если вы имеете достаточный опыт администрирования Linux систем, то можете попробовать доустановить необходимые библиотеки и заново инициализировать кластер СУБД. В противном случае PostgreSQL лучше переустановить, не забыв удалить содержимое папки /var/lib/pgsql.
Также данная ошибка может возникать при использовании сборок 9.1.x и 9.2.x Postgre@Etersoft, подробности смотрите ниже.
Ошибка СУБД: ERROR: could not load library "/usr/lib/x86_64-linux-gnu/postgresql/fasttrun.so"
Довольно специфичная ошибка, характерная для сборок 9.1.x и 9.2.x Postgre@Etersoft, также может приводить предыдущей ошибке. Причина кроется в неисправленной ошибке в библиотеке fasttrun.so. Решение - откатиться на сборку 9.0.x Postgre@Etersoft.
Ошибка СУБДERROR: type "mvarchar" does not exist at character 31
Возникает если база данных была создана без помощи системы 1С:Предприятия. Помните, для работы с 1С базы данных следует создавать только с использованием инструментов платформы 1С: через консоль Администрирование серверов 1С Предприятия
или через средство запуска 1С.
Сервер баз данных не обнаруженВАЖНО: пользователь "postgres" не прошёл проверку подлинности (по паролю)
Очень простая ошибка. Неправильно указан пароль суперпользователя СУБД postgres. Вариантов решения два: вспомнить пароль или изменить его. Во втором случае вам нужно будет изменить пароль в свойствах всех существующих информационных баз через оснастку Администрирование серверов 1С Предприятия.
Сервер баз данных не обнаруженFATAL: database "NAME" does not exist
Еще одна очень простая ошибка. Смысл ее сводится к тому, что указанная БД не существует. Чаще всего возникает из-за ошибки в указании имени базы. Следует помнить, что информационная база 1С в кластере и база данных СУБД - две разные сущности и могут иметь различные имена. Также следует помнить, что Linux системы чувствительны к регистру и для них unf83 и UNF83 два разных имени.
Часто возникает задача показать только нужные строки в табличной части документа или справочника (или другого объекта). Для этого можно использовать замечательное свойство:
в обычном приложении параметр для ОтборСтрок - Отбор...
в управляемом приложении - ФиксированнаяСтруктура
ОтборСтрок, которое входит в расширение табличного поля, связанного с табличной частью.
Управляемые формы
пример:
или такой динамический отбор
Обычные формы
Использовать его очень просто:
или 2-й вариант:
А теперь конкретные примеры:
Подчиненные табличные части в 8.х
С помощью свойства ОтборСтрок можно реализовать подчиненные (связанные) табличные части. При смене текущей строки в первой табличной части вторая табличная часть показывает только связанную информаци. Например, таким образом можно реализовать работу с комплектами: 1-я таб. часть - комплекты, вторая - состав комплекта.
Во второй табличной части должна быть колонка - идентификационный признак, связывающий ее с первой табличной частью. Таких колонок может быть несколько (составной ключ);
В событии ПриАктивизацииСтроки для первого табличного поля пишем:
При добавлении новой строки во вторую табличную часть, нужно следить за тем, чтобы идентификационная колонка была установлена.
Обращаю ваше внимание, что при таком отборе не используются индексы и для больших табличных частей возможно замедление работы.
Еще раз напомню, что ОтборСтрок входит в расширение табличного поля табличной части, т.е. табличное поле должно быть связано с табличной частью. Если же оно связано с динамическим списком типа СправочникСписок, то здесь нужно использовать свойство Отбор для объекта типа СправочникСписок.
Если понадобилось перебрать строки, вошедшие в отбор, то это можно сделать, только заново перебрав все строки и проверив условие отбора для каждой строки. Перебрать строки табличного поля, которые сейчас на экране - невозможно.
 Как установить отбор в табличной части программно?
Как установить отбор в табличной части программно? 



 Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.
Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.


 Необходимость работы с этим форматом на уровне платформы обусловлена не только тем, что это «модный современный» формат, который прикладные решения 1С:Предприятия сами по себе могут использовать для интеграции со сторонними приложениями. Другая причина заключается ещё и в том, что JSON активно используется в HTTP интерфейсах. А в 1С:Предприятии как раз есть такие механизмы, в которых хочется использовать этот формат. Это REST интерфейс приложения, автоматически генерируемый платформой, и HTTP-сервисы, которые вы можете создавать самостоятельно.
Необходимость работы с этим форматом на уровне платформы обусловлена не только тем, что это «модный современный» формат, который прикладные решения 1С:Предприятия сами по себе могут использовать для интеграции со сторонними приложениями. Другая причина заключается ещё и в том, что JSON активно используется в HTTP интерфейсах. А в 1С:Предприятии как раз есть такие механизмы, в которых хочется использовать этот формат. Это REST интерфейс приложения, автоматически генерируемый платформой, и HTTP-сервисы, которые вы можете создавать самостоятельно..gif)









