PostgreSQL напрямую "из коробки" применяться для использования с 1С Предприятем не может. Необходима именно адаптированная версия от 1С, превращающая PostgreSQL в блокировочник, причем нужно понимать, что блокировки будут накладываться на всю таблицу сразу. Если нужны блокировки на уровне записей, включаем в 1С режим управляемых блокировок и прописываем их в конфигурации ручками. Вывод: необходимо скачать специальный дистрибутив с сайта 1С или взять на диске ИТС.
Установка
Сама установка особых затруднений не вызывает, обратить внимание нужно на правильную инициализацию базы данных, а именно настройку локали, изменить потом это можно только повторной начальной инициализацией. Например, база 1С с украинскими региональными установками в СУБД с установленной русской локалью не загрузится. Да и проблемы с сортировкой потом не нужны. Поэтому делаем init в соответствии с нужным языком.
5.Удаляем службу PostgreSQL, которая была установлена в ходе установки.
sc delete pgsql-9.1.2-1.1C-x64
Где pgsql-9.1.2-1.1C-x64 – Это название службы. Если не знаете название точно, можно посмотреть свойствах службы “PostgreSQL Database Server…” (Пуск – Панель управления – Администрирование – Службы )
6.Создаем новый сервис с указанием нашего кластера
7.Теперь заходим в службы. Пуск – Панель управления – Администрирование – Службы и стартуем нашу службу.
Ошибка СУБД: ERROR: new encoding (UTF8) is incompatible with the encoding of the template database (WIN1251).
HINT: Use the same encoding as in the template database, or use template0 as template.
Вы выбрали неправильную локаль при установке СУБД (WIN1251) для сервера и клиента, нужно изменить на UTF-8 в конфигурации или переустановить СУБД со следующими параметрами:
Внимание при установке НЕ выбирайте локаль Настройки ОС, выбирайте из списка Russian, Russia
Настройка PostgreSQL
Следует помнить о рекомендации 1С не использовать в запросах конструкции ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ и заменять его, используя, например, комбинацию из нескольких левых соединений. Известна также проблема с потерей производительности в запросах, где применяется соединение с виртуальной таблицей СрезПоследних, к ней рекомендуется делать отдельные запросы и сохранять результаты во временных таблицах.
Настройка конфигурации производится редактированем файла postgresql.conf.
Наиболее важные параметры
effective_cache_size = 0,5 от ёмкости RAM
fsync = off отключаем сброс на диск после каждой транзации (Внимание! Применять только при использовании надежного UPS, есть опасность потери данных при неожиданном отключении)
synchronous_commit = off отключаем синхронную запись в лог (риски теже, что и у fsync)
wal_buffers = 0,25 от ёмкости RAM
После настройки не забываем выполнить перезапуск службы:
service postgresql restart
Настройка сети
Для подключения клиентов 1С к серверу извне и работы сервера баз данных, на файрволе, должны быть открыты следующие порты:
Агент сервера (ragent) & tcp:1540 Главный менеджер кластера (rmngr) & tcp:1541 Диапазон сетевых портов, для динамического распределения рабочих процессов & tcp:1560&1591, tcp:5432 & Postgresql. Создадим правило через стандартный интерфейс, либо с помощью команды:
Теперь с другого компьютера мы спокойно запускаем клиент 1С:Предприятия, добавляем существующую информационную базу newdb. Не забываем про лицензии, программной / аппаратной защиты.
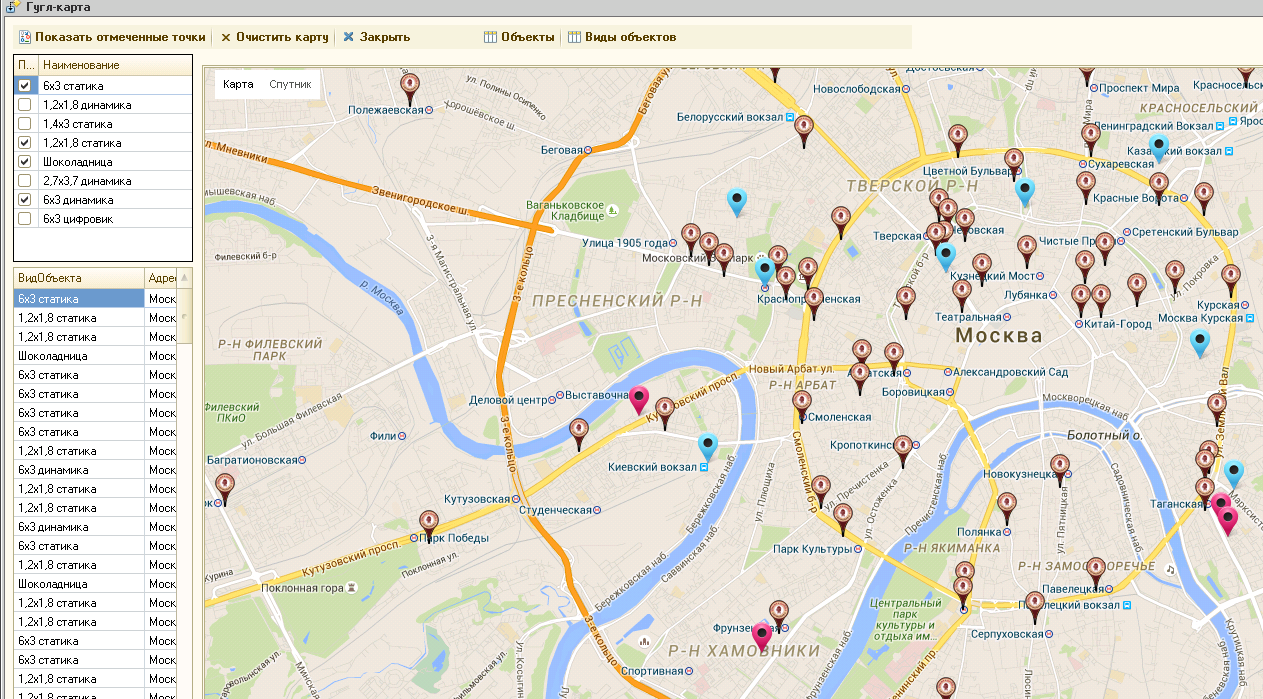
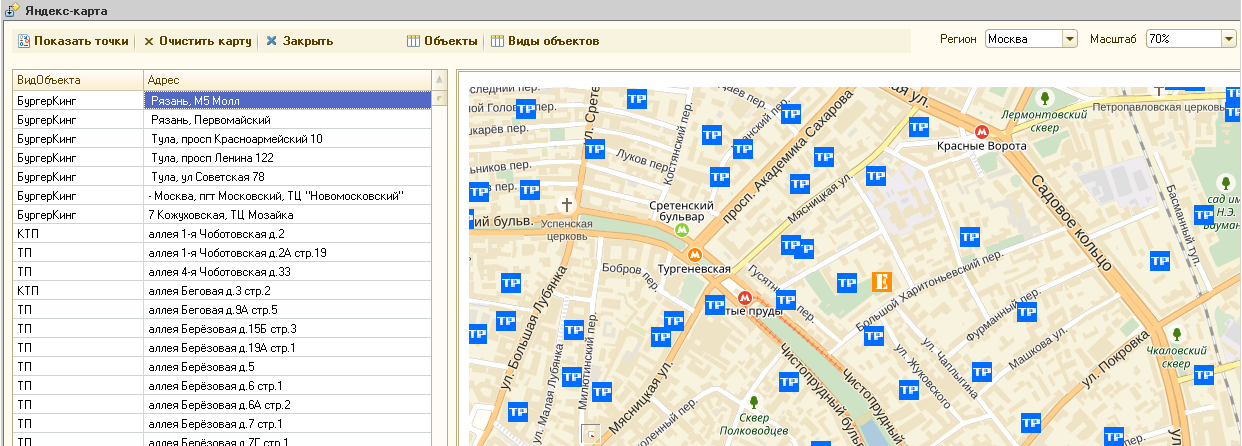
В отличие от яндекс карт в GMaps можно использовать панорамы - за что им большой плюс! Надеюсь в яндексе прочитают этот пост и тоже когда-нибудь это сделают!
Для клиента нужно было сделать вывод объектов на карту
Полнотекстовый поиск - позволит найти текстовую информацию, размещенную практически в любом месте используемой конфигурации. При этом искать нужные данные можно либо по всей конфигурации в целом, либо сузив область поиска до нескольких объектов (например, определенных видов документов или справочников). Сами критерии поиска могут варьироваться в довольно широком диапазоне. То есть найти нужные данные можно, даже не помня точно, где они хранятся в конфигурации и как именно записаны.
Полнотекстовый поиск предоставляет следующие возможности:
Есть поддержка транслитерации (написание русских слов символами латиницы в соответствии с ГОСТ 7.79-2000). Пример: "русская фраза" = "russkaya fraza".
Есть поддержка замещения (написание части символов в русских словах одноклавишными латинскими символами). Пример: "руссrfz фраpf" (окончания каждого слова набраны латиницей, допустим, в результате ошибки оператора).
Есть возможность нечеткого поиска (буквы в найденных словах могут отличаться) с указанием порога нечеткости. Пример: указав в строке поиска слово "привет" и нечеткость 17 %, найдем все аналогичные слова с ошибками и без: "привет", "превет", "привед".
Есть возможность указать область выполнения поиска по выбранным объектам метаданных.
Полнотекстовое индексирование названий стандартных полей ("Код", "Наименование" и т. д.) производится на всех языках конфигурации.
Поиск выполняется с учетом синонимов русского, английского и украинского языков.
Морфологический словарь русского языка содержит ряд специфических слов, относящихся к областям деятельности, автоматизируемым с помощью системы программ "1С:Предприятие".
Стандартно в состав поставляемых словарей включены словарные базы и словари тезауруса и синонимов русского, украинского и английского языков, которые предоставлены компанией "Информатик".
Поиск можно осуществлять с использованием подстановочных символов ("*"), а также с указанием поисковых операторов ("И", "ИЛИ", "НЕ", "РЯДОМ") и спецсимволов.
Полнотекстовый поиск можно осуществлять в любой конфигурации на платформе 1С:Предприятие 8
Для того чтобы открыть окно управления полнотекстовым поиском необходимо выполнить следующее:
Обычное приложение - пункт меню Операции - Управление полнотекстовым поиском.
Управляемое приложение - пункт меню Главное меню - Все функции - Стандартные - Управление полнотекстовым поиском.
Обновить индекс – Создание индекса/Обновление индекса;
Очистить индекс – обнуление индекса(рекомендуется после обновления всех данных);
пункт Разрешить слияние индексов – отвечает за слияние основного и дополнительного индекса.
Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.
Как вы можете заметить свойство Использовать установлено для всего справочника Контрагенты, но сделать это можно и для каждого его реквизита соответствующего типа.
Рассмотрим более подробно полнотекстовый индекс, который состоит из двух частей (индексов): основного индекса и дополнительного. Высокая скорость поиска данных обеспечивается за счет основного индекса, но обновление его происходит относительно медленно, в зависимости от объема данных. Дополнительный индекс ему противоположен. Данные добавляются в него намного быстрее, но поиск осуществляется медленнее. Система осуществляет поиск одновременно в обоих индексах. Большая часть данных находится в основном индексе, а данные добавляемые в систему попадают в дополнительный индекс. Пока объем данных в дополнительном индексе небольшой, поиск по нему происходит относительно быстро. В тот момент, когда нагрузка на систему невелика, происходит операция слияния индексов, в результате чего дополнительный индекс очищается, а все данные помещаются в основной индекс. Слияние индексов предпочтительнее выполнять в тот момент времени, когда нагрузка на систему минимальна. С этой целью можно создавать регламентированные задания и задания по расписанию.
Специальные операторы, допустимые при задании поискового выражения
Механизм полнотекстового поиска допускает написание части символов русского слова одноклавишными латинскими символами. Результат поиска при этом не измениться.
Два оператора РЯДОМ
упрощенный. На расстоянии 8 слов друг от друга
РЯДОМ/[+/-]n – поиск данных в одном реквизите на расстоянии n-1 слов между ними.
Знак указывает в каком направлении от первого слова будет поиск второго. (+ - после, - до)
Групповой символ «*» может использоваться только в качестве замены конца слова
Оператор нечеткости «#». Если неизвестно точное написание названия, имени.
Программными средствами и средствами 1с: программирование.
Оператор синонимов «!». Позволяет найти слово и его синонимы
Как программно обновить индекс полнотекстового поиска?
Пример полнотекстового поиска данных
Определение переменной СписокПоиска
Кроме этого в процедуре обработки события ПриОткрыии формы определим, что эта переменная будет содержать список полнотекстового поиска, с помощью которого мы и будем осуществлять поиск в данных
Теперь для события нажатия на кнопку Найти напишем код, который позволит нам выполнять поиск в соответствии с тем выражением, которое задано в поле ПоисковоеВыражение
Сначала в этой процедуре мы устанавливаем поисковое выражение, введенное пользователем, в качестве строки поиска для полнотекстового поиска. Затем выполняем метод ПерваяЧасть(), который собственно запускает полнотекстовый поиск и возвращает первую порцию результатов. По умолчанию порция содержит 20 элементов. После этого мы анализируем количество элементов в списке поиска. Если он не содержит ни одного элемента, то мы выводим в форму соответствующее сообщение. В противном случае вызывается процедура ВывестиРезультатПоиска(), которая отображает полученные результаты пользователю.
Создадим в модуле формы процедуру с таким именем и напишем в ней код,
Действия, выполняемые в этой процедуре, просты. Сначала мы формируем сообщение о том, какие элементы отображены и сколько всего элементов найдено. Затем получаем результат полнотекстового поиска в виде HTML-текста и выводим этот текст в поле HTML-документа, расположенное в форме.
В заключение передаем управление в процедуру ДоступностьКнопок() для того, чтобы сделать доступными или, наоборот, запретить доступ к кнопкам Предыдущая порция и Следующая порция (в зависимости от того, какая порция полученных результатов отображена). Текст этой процедуры представлен в Коде
Теперь необходимо создать обработчики событий нажатия на кнопки ПредыдущаяПорция() и СледующаяПорция().
Заключительным «штрихом» будет создание обработчика события onclick поля HTML-документа, расположенного в форме. Дело в том, что результат полнотекстового поиска, представленный в виде HTML-текста, содержит гиперссылки на номера элементов списка поиска. И нам хотелось бы, чтобы при переходе пользователя на эту ссылку система открывала бы форму того объекта, который содержится в этом элементе списка. Для этого мы будем перехватывать событие onclick HTML-документа, содержащегося в поле HTML-документа, получать номер элемента списка из гиперссылки и открывать форму соответствующего объекта. Текст обработчика события onclick поля HTML-документа представлен в коде
В нынешнее время для электронного каталога или интернет-магазина необходимо выгружать не только информацию о цене и характеристиках товара, но и сопутствующие изображения. Хранящиеся в базе или связанные с номенклатурой изображения порой приходилось выгружать отдельно, подвергая предварительной обработке имена файлов, подгоняя их под правила связи товара с изображениями в приемнике. Тем не менее, в 1С существует возможность поместить двоичные данные изображений в виде строки в XML, либо другой файл выгрузки, чтобы уже на месте разобрать информацию о товаре.
Рассмотрим на примере следующей конфигурации.
Перечень объектов:
- справочники "Номенклатура", подчиненный ему справочник "Файлы";
Для начала, добавим форму элемента для справочника "Файлы"
Настроим форму документа "Установка цен".
Добавляем обработку выгрузки в XML.
При заполнении табличной части "Товары" документа "Установка цен" и в обработке выгрузки мы обращаемся к общему модулю "Выгрузка прайса":
Кодирование изображений выполняется с помощью функции Base64Строка, в качестве аргумента передаются двоичные данные из справочника "Файлы". Предполагается, что приемник XML может выполнить обратное преобразование. В 1С это можно сделать с помощью функции Base64Значение.
Считать данные из двоичного файла можно при помощи функции ДвоичныеДанные(ИмяФайла). Например:
или через ADODB.Stream
Двоичные данные и кодировка Base64 в 1С 8.Х
Считать данные из двоичного файла можно при помощи функции
ДвоичныеДанные(ИмяФайла). Например:
Здесть ДД - специальный объект, который называется "двоичные данные".
В языке 1С есть функция, которая преобразует двоичные данные в строку
Base64Строка(ДвоичныеДанные). Например:
Здесть Строка64 - обычная строка, с которой можно делать все, что угодно.
В конце статьи приведена функция Преобразовать64(Строка64 = неопределено, Массив64 = неопределено), которая преобразовывает строку в массив байтов, и обратно.
Для того, чтобы получить массив байтов из строки, вызываем ее так:
Для обратного преобразования вызываем так:
Преобразовать строку в двоичные данные можно при помощи функции Base64Значение(Строка64)
Все указанные функции, кроме Преобразовать64, являются встроенными функциям платформы.
Меня часто спрашивают, как быстро и просто загрузить базу из файла DT?
Вот несколько простых шагов:
1. Запустите 1С и в окне выбора баз нажмите справа кнопку Добавить
2. Укажите название Базы
В данном примере мы рассматриваем загрузку файлового варианта базы - поэтому выбираем: На данном компьютере или на компьютере в локальной сети
3. Укажите Папку для сохранения файлов базы
4. Тут оставьте как есть - Готово
5. Теперь выберите добавленную базу и нажмите Конфигуратор
6. На вопрос: Информационная база не обнаружена! Создать новую?
Ответьте Да
Результаты не радуют. 1С в Internet Explorer, как и в тонком клиенте Windows не работает ничего. Видно проверка в 1С идет именно на IE и все замещается и не работает. Без библиотеки excanvas.js она просто ругается, но и она не спасает. Все остальные браузеры показывают правильный результат. Видно руки 1С туда не дошли, как и в тонком клиенте на Linux.
Меня 1C научила никогда не отступать от решения задачи, насколько сложной она не казалась с первого раза. Для этого надо понять, а как работает библиотека excanvas. Посмотреть на пример в http://infostart.ru/public/57648/. Да вспомнить, что до html5 Microsoft усиленно толкала свою систему VLM (http://msdn.microsoft.com/en-us/library/ee384217%28v=vs.85%29.aspx). Вот она и прекрасно работает со старыми версиями движков IE. И excanvas это эмуляция функций обрисовки графиков html5 через эту систему. Значит 1С надо немного помочь. Посмотрев как эта библиотека работает в старых IE, получилось решение что нужно добавить в для 1С. Делаем дополнительный флаг “Довесок для 1С”. Тестируем обработку HTML5-1С-min (см. вложение к статье). Ура, заработало. Делаем 1С ближе к HTML5.
Любителям “Такси” тоже сделаем картинку, пусть проверяют
Но таким методом не получиться протащить видео и звук в HTML5. Надо решать проблему не через 1С.
И из дополнительного, что очень хочется сделать – показ катринок заменяя значение src в поле image.
А переменной СсылкаНаКартинку можно получить с помощью функций: ПолучитьНавигационнуюСсылку
ПоместитьВоВременноеХранилище
И для полноты картины посмотрим как сама 1С выводит свои графики:
Просто делает динамически картинку во временном хранилище и ее показываем.
Источник: sikuda
Обработку ЗагрузкаданныхизТабличногоДокументаконечно должен знать каждый 1С-ник. И сколько бы обработок такого плана не появлялось, эта остается классикой. Даже претензии можно предъявлять если вы в ней что-то не понимаете к самой 1С. Хотя какие претензии, исходный код открыть – изучай, не хочу…
Еще чем мне нравится эта обработка – тем что вы читаете данные из внешнего источника, показываете их с помощью объекта табличное поле и только затем выбираете алгоритм загрузки в 1С. При чем загрузка у Вас происходит в среде 1С без привлечения дополнительных компонентов. Без всяких выпадов в неизвестный объект OLE, полей которые не прочитались в обработке загрузки. Если вы видете данные в табличном поле, то они и будут грузиться по вашему алгоритму.
Но что-то в ней не хватает. Конечно стандарта офисных документов ODF (Open Document Format и между прочим ГОСТ Р ИСО/МЭК 26300-2010). Как говаривал мой начальник – есть чем себя занять. Из всех внешних загрузок, которые сейчас есть к сожалению самыми распостраненными являются OLE(Com+) технологии. Возможно что-то еще появиться, но пока примемся за них.
Залезаем в код и видим несколько однотипных функуций
Функция мПрочитатьТабличныйДокументИзExcel(ТабличныйДокумент, ИмяФайла, НомерЛистаExcel = 1) Экспорт
Функция мПрочитатьТабличныйДокументИзТекста(ТабличныйДокумент, ИмяФайла, НомерЛистаExcel = 1) Экспорт
Пора добавить свою:
И добавим в форму выбора файла ods по тексту.
И выбор функции для ods
ИначеЕсли нРег(ФайлНаДиске.Расширение) = “.ods” Тогда
мПрочитатьТабличныйДокументИзCalc(ТабличныйДокумент,ДиалогВыбораФайла.ПолноеИмяФайла);
В данной статье рассматривается способ программного формирования HTML документа, содержащего ссылки на объекты базы данных 1С, такие как справочники, документы и т.д. Показан пример построения обработчика события OnClick ПоляHTMLДокумента, для обработки клика на html-ссылке.
Предисловие
Однажды, дописывая обработку, создающую и модифицирующую, не суть важно какие документы, я подумал, что неплохо было бы вывести для пользователя некое резюме:
“Создан документ такой-то”
“Изменен документ такой-то” и т.д.
От обычного, в таких случаях, вывода информации в окно сообщений я сразу отказался, так как не удобно это, сначала читать в окне сообщений “Создан документ … ” а потом запоминать его номер, открывать соответствующий журнал (или форму списка) и искать там этот документ. А если документов много и пользователь хочет посмотреть все документы?(или выборочно) Насколько это неудобно я убедился при отладке обработки …
То, что в форме есть элемент управления именуемый ПолеHTMLДокумента я конечно знал, но вот представилась возможность познакомиться с ним поближе. Было решено реестр обработанных документов выводить в виде html документа содержащего ссылки на эти самые документы, а по клику на ссылке открывать форму соответствующего документа. Здесь мне многие могут возразить: “А почему бы для этих целей не использовать обычный макет, выводимый в табличный документ, а для открытия документов использовать расшифровку? И чем Ваш способ лучше?” Отвечаю: Конечно можно использовать, и мой способ ничем не лучше. Он просто другой. Ведь у хорошего программиста для решения одной задачи должно быть в арсенале несколько инструментов.
Итак, перейдем от слов к делу, в рамках данной статьи рассмотрим следующую задачу: Сформировать html-документ, содержащий ссылки на элементы справочника номенклатура, по клику требуется открывать форму соответствующего элемента. Создаем новый отчет, его форму, на форме размещаем элемент управления ПолеHTMLДокумента.
Текст модуля формы:
Ну вот html мы сформировали, теперь чтобы ссылки “ожили” надо написать обработчик события OnClick элемента управления ПолеHTMLДокумента.
Всё можно пробовать!
Заключение
Обратите внимание что ссылку я формировал следующим образом:
<ИмяОбъектаМетаданных>-<УникальныйИдентификатор> это сделано для того, чтобы в обработчике onclick можно было определить к какому объекту метаданных относится данный УникальныйИдентификатор, потому что имея ТОЛЬКО УникальныйИдентификатор невозможно определить к какому объекту метаданных он относиться. Точнее возможно, но уж слишком долго и неудобно – путем перебора всех метаданных в цикле, для каждого объекта метаданных выполнять попытку <ОбъектМетаданных>.ПолучитьСсылку(Новый УникальныйИдентификатор(НашУникальныйИдентификатор))
Хотя в нашем примере только один справочник, и указывать его вид было необязательно, и так понятно что это УникальныйИдентификатор элемента справочника Номенклатура, но вдруг Вам потребуется работать с несколькими справочниками, вот тут то мой способ задания ссылки Вам и пригодится. Скачивать файлы может только зарегистрированный пользователь!
P.S. Платформа 8.2 имеет встроенный механизм работы со ссылками на объекты БД и данная задача наверняка упростится, но это уже другая тема.
Источник: obrabotki.com
Нужно перейти в закладку Командный интерфейс и отметить галками движения доступные для просмотра пользователям, после этого появится на форме документа панель слева в которой можно будет перейти в движения документа по регистрам
Вам встретилось сообщение, содержащее строки: Microsoft OLE DB Provider for SQL Server: CREATE UNIQUE INDEX terminated because a duplicate key was found for index ID
или Cannot I_nsert duplicate key row in object
или Попытка вставки неуникального значения в уникальный индекс.
Варианты решения: 1. В SQL Server managment studio физически уничтожаем сбойный индекс (в моем случае это был индекс по таблице итогов регистра бухгалтерии). В 1С распроводим сбойные документы. В режиме тестирования и исправления ставим галки реиндексация таблиц + пересчет итогов. 1С воссоздает индекс уже без ошибки. Проводим ранее сбоившие документы. 2. 1) С помощью Management Studio 2005 сгенерировала create-скрипт на создание индекса, который глючил, и сохранила в файлик.
2) Вручную убила косячный индекс из таблицы _AccumRgTn19455
3) Запустила запрос вида
После того, как индекс был убит, у меня отобразилось 15 дублирующихся записей, хотя до выполнения п.2 запрос ничего не возвращал.
4) Просмотрела все записи и вручную почистила дубликаты. На самом деле, я ещё пользовалась обработкой "Структура отчёта", чтобы понять, с чем вообще имею дело. Оказалось, что в таблице _AccumRgTn19455 хранится регистр накопления "Выпуск продукции (налоговый учёт)". Я ещё поковырялась sql-запросами, выявила 15 неуникальных документов и после окончания всех действ проверила в 1С, что эти документы проводятся нормально, без ошибок. Просто так чистить таблицы наобум, конечно, не стоит: важно понимать, что чистится и чем это может обернуться.
5) Запустила запрос на создание индекса, который был сохранён в файле.
6) Перевела базу в однопользовательский режим и запустила dbcc checkdb - на этот раз ни одной ошибки не выдалось.
7) Перевела базу обратно в однопользовательский режим.
Всё... проблема побеждена. Ну ещё в 1С запустила "Тестирование и исправление", там тоже всё прошло нормально, перестало ругаться на неуникальный индекс. 3. Если неуникальность заключается в датах с нулевыми значениями, то проблема решается созданием базы с параметром смещения равным 2000.
1. Если проблема загрузкой базы данных, то:
1.1. Если Вы делаете загрузку (используйете dt-файл) в базу MS SQL Server, то при создании базы перед загрузкой укажите смещение дат - 2000.
Если уже база создана со смещением 0, то создайте новую с 2000.
1.2. Если есть возможность в файловом варианте работать с базой, то выполните Тестирование и Исправление, а также Конфигурация - Проверка конфигурации - Проверка логической целостности конфигурации + Поиск некорректных ссылок.
1.3. Если нет файлового варианта, попробуйте загрузить из DT в клиент-серверный вариант с DB2 (который менее требователен к уникальности), и затем выполнить Тестирование и Исправление, а также Конфигурация - Проверка конфигурации - Проверка логической целостности конфигурации + Поиск некорректных ссылок.
1.4. Для локализации проблемы можно определить данные объекта, загрузка которого не удалась. Для этого надо включить во время загрузки трассировку в утилите Profiler или включите запись в технологический журнал событий DBMSSQL и EXCP.
2. Если проблема неуникальности проявляется во время работы пользователей:
2.1. Найти с помощью метода пункта 1.4 проблемный запрос.
2.1.2. Иногда ошибка возникает во время исполнения запросов, например:
Данная ошибка возникает из-за того что в модуле регистра накопления "Рабочее время работников организаций" в процедуре "ЗарегистрироватьПерерасчеты" в запросе не стоит служебное слово "РАЗЛИЧНЫЕ".
В последних выпущенных релизах ЗУП и УПП ошибка не возникает, т.к. там стоит "РАЗЛИЧНЫЕ".
2.2. После нахождения проблемного индекса из предыдущего пункта, необходимо найти неуникальную запись.
2.2.1. «Рыба» скрипта для определения неуникальных записей с помощью SQL:
2.2.2 Пример. Индекс в ошибке называется "_Document140_VT1385_IntKeyIndNG".
Перечень полей таблицы: _Document140_IDRRef, _KeyField, _LineNo1386, _Fld1387, _Fld1388, _Fld1389, _Fld1390, _Fld1391RRef, _Fld1392RRef, _Fld1393_TYPE, _Fld1393_RTRef, _Fld1393_RRRef, _Fld1394,_Fld1395, _Fld1396RRef, _Fld1397, _Fld1398, _Fld1399RRef, _Fld22260_TYPE, _Fld22260_RTRef, _Fld22260_RRRef, _Fld22261_TYPE, _Fld22261_RTRef, _Fld22261_RRRef
Перед выполнением приведенной ниже процедуры сделайте резервную копию базы данных.
Выполните в MS SQL Server Query Analizer:
С его помощью узнайте значения колонок _Document140_IDRRef, _KeyField, дублирующихся записей (id, key).
При помощи запроса:
посмотрите на значения других колонок дублирующихся записей.
Если обе записи имеют осмысленные значения и эти значения разные, то исправьте значение _KeyField на уникальное. Для этого определите максимальное занятое значение _KeyField (keymax):
Замените значение _KeyField в одной из повторяющихся записей на правильное:
Здесь _LineNo1386 = - дополнительное условие, которое позволяет выбрать одну из двух повторяющихся записей.
Если одна (или обе) из повторяющихся записей имеет очевидно неправильное значение, то ее нужно удалить:
Если повторяющиеся записи имеют одинаковые значения во всех колонках, то из них нужно оставить одну:
Описанную процедуру необходимо выполнить для каждой пары повторяющихся записей.
2.2.3. Второй пример:
2.3.4 Пример определения неуникальных записей с помощью запроса 1С:Предприятие:
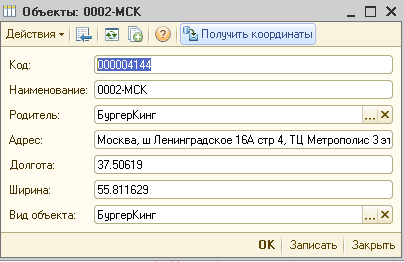
 Как получить координаты выделенной области на Яндекс Карте?
Как получить координаты выделенной области на Яндекс Карте? 





 Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.
Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.




















 и отметить галками движения доступные для просмотра пользователям, после этого появится на форме документа панель слева в которой можно будет перейти в движения документа по регистрам
и отметить галками движения доступные для просмотра пользователям, после этого появится на форме документа панель слева в которой можно будет перейти в движения документа по регистрам