При добавлении новых объектов в типовые конфигурации возможна ошибка при обращении к этому объекту в режиме 1C:Предприятие: "Объект не найден в Справочнике "ИдентификаторыОбъектовМетаданных".
{Справочник.ИдентификаторыОбъектовМетаданных.МодульМенеджера(738)}: Ошибка при выполнении функции ОбщегоНазначения.ИдентификаторОбъектаМетаданных().
Для объекта метаданных "Отчет.РИК_РасчетыСПартнерами" не найден идентификатор в справочнике "Идентификаторы объектов метаданных".
Для разработчика: возможно требуется обновить вспомогательные данные, которые влияют на работу программы. Для выполнения обновления можно:
- воспользоваться внешней обработкой "Инструменты разработчика: Обновление вспомогательных данных",
- либо запустить программу с параметром командной строки 1С:Предприятия 8 "/С ЗапуститьОбновлениеИнформационнойБазы",
- либо увеличить номер версии конфигурации, чтобы при очередном запуске выполнились процедуры обновления данных информационной базы.
Варианты решения:
1. В некоторых конфигурациях режиме предприятия
Все функции - Обработки - "Инструменты разработчика: Обновление вспомогательных данных", Если обработки нет, то пункт 2
Все функции - Справочники - "Идентификаторы объектов метаданных", нажать кнопку "Обновить данные справочника", Если кнопки обновить нет, то пункт 2
2. Из Конфигуратора запустить с параметром «/С ЗапуститьОбновлениеИнформационнойБазы», т.к. обработки может не оказаться под руками, а изменение версии производится с обновлением конфигурации и базы, что может оказаться не удобным:
При запуске Предприятия появится окно обновления конфигурации. Потом не забудьте Убрать параметр запуска, чтобы больше не запускалось обновление!
3. Обновить конфигурацию или вручную увеличить номер версии конфигурации, чтобы при очередном запуске выполнились процедуры обновления данных информационной базы.
Для добавления отчета или обработки нужно в модуле добавить Функцию СведенияОВнешнейОбработке()
После сохранения приступим к добавлению в программу:
Ставим галку Дополнительные отчеты и обработки
Открываем дополнительные отчеты и обработки и жмем создать, появляется окно выбора файла, после выбора:
Укажите Размещение (в каком разделе отображать данный отчет/обработку) и в списке в колонке Быстрый доступ выберите пользователей, которым будет доступен данный отчет/обработка.
Если при добавлении вы получаете ошибку:
{ОбщийМодуль.ДополнительныеОтчетыИОбработки.Модуль(2621)}: Поле объекта не обнаружено (ХранилищеВариантов)
Если ВнешнийОбъектМетаданные.ХранилищеВариантов <> Неопределено Тогда
То нужно заменить в модуле объекта, в функции СведенияОВнешнейОбработке():
Итак, устанавливаем минимальный CentOS, настраиваем имена хостов, DNSы и сетевые подключения и приступаем собственно к установке серверных компонентов.
1. Установка Postgre SQL server
Обновление от 03-ноя-2016: в последних версиях CentOS (у меня сегодня был 7.2.1511) отсутствует поддержка libtermcap (и как-то "иначе" реализована libreadline), из-за чего сборки с сайта 1С не устанавливаются - решил поставить сборку от Postgres Professionals https://postgrespro.ru/products/1c_build - вроде работает, но о стабильности и производительности пока судить рано. Так что у кого проблемы с libtermcap.so.2() и/ли libreadline.so.5() при установке PostgreSQL с патчами 1С, можете попробовать этот альтернативный вариант.
Для установки использовался рекомендованный (адаптированный) 1С дистрибутив, для чего потребуется скачать его из раздела поддержки пользователей сайта 1С. В моём случае это был "Дистрибутив СУБД PostgreSQL для Linux x86 (64-bit) одним архивом (RPM)", который я сохранил в /root/temp. Распаковываем архив:
[root@vm-sql01 temp]# tar -vxf postgresql-9.2.1-1.1C_x86_64_rpm.tar.gz
Все недостающие зависимости (пакеты) будут установлены в процессе установки этих rpm, хотя на сайте 1С рекомендуют предварительно установить пакеты readline, libtermcap, krb5-libs и openssl, но в моём случае они либо уже были установлены, либо не были обнаружены в репозиториях.
2. Первый запуск Postgre SQL server
В отличии от сценариев установки большинства знакомых мне sql-серверов, postgres требует предварительной инициализации перед запуском, для чего существует два пути - первый, правильный:
[root@vm-sql01 pgsql]# su postgres -c '/usr/pgsql-9.2/bin/initdb -D /var/lib/pgsql/9.2/data --locale=ru_RU.UTF-8'
Файлы, относящиеся к этой СУБД, будут принадлежать пользователю "postgres".
От его имени также будет запускаться процесс сервера.
Кластер баз данных будет инициализирован с локалью "ru_RU.UTF-8".
Кодировка БД по умолчанию, выбранная в соответствии с настройками: "UTF8".
Выбрана конфигурация текстового поиска по умолчанию "russian".
исправление прав для существующего каталога /var/lib/pgsql/9.2/data... ок
создание подкаталогов... ок
выбирается значение max_connections... 100
выбирается значение shared_buffers... 32MB
создание конфигурационных файлов... ок
создание базы template1 в /var/lib/pgsql/9.2/data/base/1... ок
инициализация pg_authid... ок
инициализация зависимостей... ок
создание системных представлений... ок
загрузка описаний системных объектов... ок
создание правил сортировки... ок
создание преобразований... ок
создание словарей... ок
установка прав для встроенных объектов... ок
создание информационной схемы... ок
загрузка серверного языка PL/pgSQL... ок
очистка базы данных template1... ок
копирование template1 в template0... ок
копирование template1 в postgres... ок
ВНИМАНИЕ: используется проверка подлинности "trust" для локальных подключений.
Другой метод можно выбрать, отредактировав pg_hba.conf или используя ключи -A,
--auth-local или --auth-host при следующем выполнении initdb.
Готово. Теперь вы можете запустить сервер баз данных:
Или второй, более простой, но не всегда дающий необходимый результат (зависит от региональных настроек сервера, но у меня иногда приводивший к установке базы данных без поддержки необходимого collation ru_RU.UTF-8):
[root@vm-sql01 pgsql]# service postgresql-9.2 initdb
Инициализируется база данных: [ OK ]
[root@vm-sql01 pgsql]#
В результате была создана структура базы данных (с настройками) в /var/lib/pgsql/9.2/data. Хочу обратить особое внимание на конструкцию --locale=ru_RU.UTF-8, которую необходимо указать при инициализации, иначе сервер может быть инициализирован с неверным набором языковых параметров, что в конечном итоге приведёт к сообщениям
Ошибка установки или изменения национальных настроек информационной базы
Порядок сортировки не поддерживается базой данных
по причине:
Порядок сортировки не поддерживается базой данных
при установке информационной базы. Теперь можно настраивать автоматический запуск sql-сервера и, собственно, запускать его:
[root@vm-sql01 temp]# chkconfig postgresql-9.2 on
[root@vm-sql01 temp]# service postgresql-9.2 start
Запускается служба postgresql-9.2: [ OK ]
[root@vm-sql01 temp]#
Всё. Для локальных подключений сервер настроен. В моём случае сервер 1С и сервер SQL находятся на разных машинах, поэтому потребуется настроить и удалённые подключения с авторизацией.
В случае каких-то проблем, читаем содержимое файлов:
/var/lib/pgsql/9.2/pgstartup.log
/var/lib/pgsql/9.2/data/postgresql-*.log
Для повышения быстродействия документация PostgreSQL рекомендует как минимум унести журнал /var/lib/pgsql/9.2/data/pg_xlog на отдельный физический том и создать симлинк на него в исходном месте; из личных наблюдений - надо ещё и значительно увеличить размер используемой памяти... но необъятное не охватить, поэтому за статьями по оптимизации работы PostgreSQL для 1С предлагаю обращаться в поисковые системы, а оттуда - на профильные форумы.
3. Настройка пользователей (ролей) Postgre SQL server
Для управления PostgreSQL на начальном этапе потребуется сменить текущего пользователя на postgres и создать нового пользователя из командной строки:
[root@vm-sql01 temp]# su - postgres
-bash-4.1$ cd /usr/pgsql-9.2/bin
-bash-4.1$ createuser --interactive -P
Введите имя новой роли:server1c
Введите пароль для новой роли:
Повторите его:
Должна ли новая роль иметь полномочия суперпользователя? (y - да/n - нет) n
Новая роль должна иметь право создавать базы данных? (y - да/n - нет) y
Новая роль должна иметь право создавать другие роли? (y - да/n - нет) n
-bash-4.1$ exit
logout
[root@vm-sql01 temp]#
В принципе, для обслуживания полезно иметь пользователя с правами суперпользователя - создавать его можно тем же путём.
Теперь осталось разрешить удалённое подключение с авторизацией - для этого в файле /var/lib/pgsql/9.2/data/pg_hba.conf потребуется заменить значение ident на md5 в строке "host all all 0.0.0.0/0 md5" и перезапустить сервис.
Не следует забывать и про настройки iptables - для работы Postgre SQL необходимо открыть как минимум порт tcp 5432, хотя привычнее (да и проще) объявить сетевой интерфейс "внутренним" (разрешить все подключения на интерфейсе).
Для управления сервером потребуется pgAdmin, который можно установить из репозиториев используемого для административных целей линукса, либо скачать с сайта проекта.
4. Установка компонентов сервера 1С
Внимание!!! Для избежания проблем с зависимостями, желательно, чтобы разрядность сервера 1С совпадала с разрядностью используемого дистрибутива Linux! Иначе (если ставим 32-битный 1С на 64-битный Linux), при входе в базу, можно получить сообщение типа "Ошибка загрузки библиотеки libWand.so по причине:Библиотека не обнаружена. Часть функций будет недоступна." и клиенты не будут запускаться (хотя конфигуратор - будет). В принципе, я с этой проблемой справился на CentOS 7 (которой не выпускают больше в 32-битном исполнении) - просто поставил не только 'ImageMagick', но и 'ImageMagick.i686' (yum install ImageMagick.i686) - всё заработало (хоть и притянуло за собой гору зависимостей).
Первый шаг установки сервера 1С мало отличается от аналогичного этапа с SQL-сервером - распаковать скачанный дистрибутив сервера командой tar -vxf rpm64.tar.gz. В итоге получим файлы:
1C_Enterprise83-common-8.3.3-715.x86_64.rpm - основные файлы 1С (включая русский и английский интерфейсы)
1C_Enterprise83-common-nls-8.3.3-715.x86_64.rpm - дополнительные языковые модули
Настраиваем автоматический запуск демона и стартуем его:
[root@vh-1c83 temp]# chkconfig srv1cv83 on
[root@vh-1c83 temp]# service srv1cv83 start
Starting 1C:Enterprise 8.3 server: Error: service failed to start!
FAILED
[root@vh-1c83 temp]# service srv1cv83 start
Starting 1C:Enterprise 8.3 server: OK
[root@vh-1c83 temp]#
Хочу обратить внимание - если сразу после установки сервис (как в приведённом примере) не стартовал, а при второй попытке старта он запустился, скорее всего не настроен DNS - об этом чуть ниже. Если верить информации с многочисленных форумов, то наш сервер уже готов обслуживать до 12 клиентов. Для работы большего числа пользователей, необходимо установить лицензию сервера - либо в виде USB HASP и драйвера, либо в виде электронной лицензии. Про установку аппаратных ключей я уже писал, а установка программных лицензий достаточно проста: запускаем конфигуратор (с клиентской машины; кластер уже должен быть настроен и должна быть информационная база), вызываем "Сервис" - "Получение лицензии", вводим номер комплекта (с коробки или "Регистрационный номер" с карточки из конверта "Пинкоды программной лицензии") и пин-код (с той самой карточки из конверта), ставим галочку "Установка на сервер", вводим имя сервера в соответствующем поле, нажимаем "Далее", говорим, что это - "Первый запуск", заполняем форму "Владелец лицензии" (к стати, я не понял что писать в полях "Фамилия", "Имя", "Отчество" - то ли ответственного за эксплуатацию, то ли генерального директора - оставил поля пустыми, и оно получило лицензию, не ругнувшись), "Далее", "Автоматически" - профит! в /var/1C/licenses на сервере появился файлик XXXXXXXXXXXXXX.lic и серверу "стало хорошо" (если это была многопользовательская лицензия, то клиентам тоже "станет хорошо", т.к. они будут получать лицензии на сервере).
Для работы с графическими объектами и экспорта в xls, могут потребоваться дополнительные пакеты: ImageMagick, freetype (входит в зависимости ImageMagick), libgsf (входит в зависимости ImageMagick), corefonts (отсутствует в репозитариях CentOS - см. раздел 6); для "ТАКСИ" и "Управляемого приложения" они необходимы, для классического толстого клиента вроде бы не особо нужны, но 1С всё равно ругается на их отсутствие, хоть и работает.
По умолчанию сервер 1С слушает порт tcp 1541(1540) и для соединений использует диапазон портов 1560-1691.
5. Настройка экземпляра (кластера) сервера 1С
Информации о наличии оснастки управления сервером 1С для Linux мне не попадалось, так что для управления сервером будем использовать традиционную оснастку mmc для Windows "Администрирование серверов 1С:Предприятия", которую следует поставить из дистрибутива технологической платформы для Windows.
В этом месте на тестовом сервере возникли трудности - кластер по умолчанию отсутствовал, а при попытке создания нового кластера, ragent аварийно завершал работу с сообщением Sep 3 21:29:04 vh-1c83 kernel: ragent[1879]: segfault at 8 ip 00007f56473c9fd4 sp 00007f563b7b14a0 error 4 in rserver.so[7f56472db000+70e000]... странно, но если верить форумам, на CentOS у многих сервер 1С 8.3 ставится некорректно - не создаётся начальная конфигурация, включающая "Кластер по умолчанию". Краткий анализ ситуации выявил, что настройки кластера по умолчанию не были сгенерированы полностью и не попали в /home/usr1cv8/.1cv8/1C/1cv8/.
При попытке подложить файлы с рабочего сервера на неудачный, сервис 1С не запускается абсолютно без каких-либо диагностических сообщений - подобное поведение я видел при проблемах (неверных контекстах) SELinux, но в данном случае никаких отказов в audit.log не обнаружилось.
В результате детального изучения проблемы с применением strace удалось выяснить, что агент сервера при запуске ищет настройки по пути ~/.1cv8/1C/1cv8/ (в домашнем каталоге запустившего пользователя) и если не находит, пытается создать настройки кластера по умолчанию, для чего ему нужно имя хоста (выяснено экспериментально), и если верить "Руководству администратора", нужен корректно работающий DNS; экспериментально же был установлен факт, что сначала ragent читает файл /etc/hosts, затем обращается к DNS-серверу, а затем вызывает uname и снова лезет в hosts и к DNS и если не находит сопоставления, аварийно завершается. Итак, для нормального запуска потребуется полноценная и правильно настроенная сетевая инфраструктура, ну а в отсутствии работающего DNS достаточно дописать строчку в /etc/hosts и привести его примерно к такому виду:
За дальнейшими инструкциями пока отсылаю к своей статье про 8.2 - принципиальных отличий пока нет. Единственное замечание - при создании новой информационной базы, если указывать пользователя подключения к базе данных не с правами суперпользователя (а с набором прав из пункта 3), информационная база не создавалась, а в /var/lib/pgsql/9.2/data/pg_log/postgresql-Xxx.log наблюдались сообщения:
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: нет доступа к языку c
ОПЕРАТОР: CREATE OR REPLACE FUNCTION plpgsql_call_handler() RETURNS language_handler AS '$libdir/plpgsql' LANGUAGE C
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: ошибка синтаксиса (примерное положение: "application") в символе 24
ОПЕРАТОР: lock table pg_class in application share mode
ПРЕДУПРЕЖДЕНИЕ: нет незавершённой транзакции
ОШИБКА: тип "mvarchar" не существует в символе 31
ОПЕРАТОР: create table Config (FileName mvarchar(128) not null, Creation timestamp not null, Modified timestamp not null, Attributes int not null, DataSize int8 not null, BinaryData bytea not null, PartNo int not null, PRIMARY KEY (FileName, PartNo))
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: нет доступа к языку c
ОПЕРАТОР: CREATE OR REPLACE FUNCTION plpgsql_call_handler() RETURNS language_handler AS '$libdir/plpgsql' LANGUAGE C
После подключения с учётными данными суперпользователя БД, сообщения изменились на англоязычные и проблемы исчезли. Судя по всему, если на сервере установлен язык по умолчанию en_US, данного казуса не случится, но это - не проверенная информация, а лишь предположение, сделанное по прочтении чужой статьи про 8.1 и праздных раздумий =)
Ещё одна странность - если создать пустую SQL базу не из шаблона1 (см. официальную документацию по 1С), и попытаться ей указать на этапе создания ИБ, то всё равно получим сообщение "ОШИБКА: тип "mvarchar" не существует (символ 31)"/"ERROR: type "mvarchar" does not exist at character 31", но мне так и не удалось создать из требуемого шаблона БД - валились разные ошибки, но если пользователя sql, от которого создаётся ИБ временно повысить до суперпользователя с правом создания БД, и указать создание базы данных в случае её отсутствия, то всё получается в лучшем виде, так что на этапе первичной настройки, видимо, придётся повышать пользователя до супер...
Что порадовало - теперь в 1С можно работать непосредственно из Linux, что актуально для компаний, использующих его как основную ОС в корпоративной сети (я сейчас работаю как раз в такой компании); из неожиданностей - что при установке клиента 1С, он заявляет о зависимости от сервера и требует его установки, но потом ставится, прописывает значки запуска в "Офис" - "Финансы" и работает довольно сносно (по ощущениям - чуть менее комфортно, чем 8.2 под Windows, но заметно приятнее, чем тот же 8.2 через WINE от Ethersoft).
6. Установка недостающих зависимостей
При запуске клиента к настроенному по данной инструкции серверу, появится сообщение "На сервере отсутствуют шрифты из состава Microsoft Core Fonts. Внешний вид приложения может отличаться от ожидаемого. Процедура установки описана в справочной системе..." - данное сообщение появляется достаточно редко (периодичность не выявил, но появляется точно не единожды, но и не при каждом запуске), и на работе особо не сказывается, но "для красоты" я решил пройтись по всей цепочке и поставить рекомендуемые пакеты. Всё, кроме "corefonts" поставилось из репозиториев (хотя в той самой "справочной системе" безбожно перепутаны регистры в названиях пакетов, из-за чего их идентификация оказалась весьма развлекательна), ну а шрифты я решил пересобрать (в соответствии с рекомендациями из "справочной системы") и результат прикрепляю к статье - msttcorefonts-2.5-1.noarch.rpm, заодно и сами шрифты (уже переименованные в нижний регистр, как происходит при сборке rpm рекомендованным скриптом) - msttcorefonts.tar.gz - содержимое этого архива рекомендуют распаковать в /home/usr1cv8/.fonts (не забыв сменить владельца как на папку, так и на файлы!), если нет возможности установить предложенный .rpm
Кроме "ImageMagick" и шрифтов, для возможности сохранения в табличные файлы (кроме xls - его я пока не заставил формироваться, хотя xlsx формируется), на клиенте должны быть установлены пакеты "libMagickWand5", "libgomp1", "liblcms2-2" и "libbz2-1" - на ряде машин они отсутствовали. При чём той же разрядности, что и сервер 1С (см. п. 4).
7. Настройка аппаратного hasp для виртуализированного сервера 1С (работающего на виртуальной машине KVM)
Не планировал описывать эту процедуру, но раз уж столкнулся с такой ситуацией, опишу... Итак, на этот раз я использовал драйвер от "Alladin Knowledge Systems USB HASP", предоставляемый компанией Sentinel - мне попались две версии:
2878061 сен 11 2012 aksusbd-2.0-1.i386.rpm - с сайта aladdin-rd.ru
3009880 авг 6 16:35 aksusbd-2.2-1.i386.rpm - с сайта safenet-inc.com
Можно воспользоваться драйвером эзерсофт - окончательный выбор следует делать из опыта практической эксплуатации.
Наиболее правильная (на мой взгляд) последовательность действий:
а) убедиться, что на хост-машине драйвер HASP не установлен;
б) установить выбранный драйвер USB HASP4 на виртуальном сервере;
в) выяснить список подключенных USB-устройств к хост-машине
[root@vh01 files]# ls -R /dev/bus/usb
/dev/bus/usb:
001
002
003
004
/dev/bus/usb/001:
001
002
/dev/bus/usb/002:
001
/dev/bus/usb/003:
001
/dev/bus/usb/004:
001
[root@vh01 files]#
г) подключить USB-HASP к хост-машине и выяснить адрес ключа:
[root@vh01 files]# ls -R /dev/bus/usb
/dev/bus/usb:
001
002
003
004
/dev/bus/usb/001:
001
002
/dev/bus/usb/002:
001
/dev/bus/usb/003:
001
/dev/bus/usb/004:
001
002 <==== это наш ключ - раньше его не было
[root@vh01 files]#
д) используя любой из способов (я использовал Virtual Manager на удалённой машине) добавить "USB Host Device" с найденным адресом (в моём примере - 004:002) к виртуальной машине 1С - может потребоваться выключение и включение машины (я добавлял устройство на выключенную машину).
Собственно, всё - на CentOS 6.4 x64/i686 всё работает (были багрепорты про CentOS 6.0/6.1, но вроде всё починили). Если при запуске виртуалки выдаётся сообщение о занятости устройства, скорее всего подцепился драйвер на хост-машине (так писали на паре форумов, хотя мне эту ситуацию воспроизвести не получилось - даже с установленным драйвером на сервере устройство мапилось корректно). Естественно, если переставить ключ в другой порт USB, придётся перенацеливать и виртуальную машину!
/home/usr1cv8/.1cv8/1C/1cv8/1cv8wsrv.lst - файл, в котором хранятся основные свойства сервера - например, учётные данные администратора сервера, зарегистрированые кластеры и т.п.
/home/usr1cv8/.1cv8/1C/1cv8/reg_1541/1CV8Clst.lst - файл, в котором хранятся свойства кластера по умолчанию
/opt/1C/v8.3/x86_64/ - (вместо "x86_64" может быть "i386" - в зависимости от архитектуры системы) исполняемые файлы и сопутствующие ресурсы сервера (и клиента) 1С
/var/1C/licenses - здесь лежат файлы электронных ключей лицензий
8. Настройка локального репозитория 1С для удобства обновления платформы
В процессе эксплуатации 1С нередко приходится обновлять платформу. Если всё установлено по приведённой выше инструкции, это вызывает определённые неудобства - надо останавливать сервис, удалять старые пакеты, ставить новые... не знаю - мне это ещё в винде надоело смертельно. Linux предлагает очень удобный механизм пакетного обновления из локального репозитория - всё, что нужно - это выбрать место, где будут лежать обновки: для одиночного сервера, к которому все ходят только через web-интерфейс, это может быть /root/repo (всё равно обновление под рутом идёт), ну а в общем случае - хоть /var/www/1c-repo - главное, чтобы все, кому он нужен, его видели. Далее надо установить пакет 'createrepo' (yum install createrepo) - за собой он притащит немало зависимостей, но не смертельно. Теперь командой 'createrepo /root/repo' (где "/root/repo" - выбранный путь хранения репозитория) создаём его "описание" и можно пользоваться.
Затем создаём файл описания нашего репозитория и помещаем его в каталог описаний репозиториев (для CentOS это /etc/yum.repos.d). Пример конфига локального файлового репозитария:
[root@1c yum.repos.d]# cat local-1c.repo
[local-1c]
name=1C Enterprise
#baseurl=http://inhost.firm.lan/repo
baseurl=file:///root/repo
gpgcheck=0
enabled=1
По-моему, разъяснять что за что отвечает, особого смысла нет. Единственное, что важно - сразу yum его может не увидеть - в этой ситуации поможет очистка его кэшей (yum clean all).
Всё. Теперь если надо обновиться, то помещаем новые файлы дистрибутива 1С рядом со старыми, повторяем 'createrepo /root/repo' вызываем 'yum update' - и всё - платформа пошла обновляться! Естественно, за сохранностью и защищённостью своего репозитория надо следить, так как GPG у нас выключен, и это всё же дыра в безопасности, хоть и не особо толстая...
Последовательность событий, которые происходят при открытии формы нового элемента, можно представить следующей схемой:
Прежде всего, при заполнении нового объекта данными, можно попробовать обойтись вообще без написания какого-либо кода. Для этого у реквизитов объектов конфигурации есть свойства ЗначениеЗаполнения и ЗаполнятьИзДанныхЗаполнения.
Эти свойства позволяют визуально (в конфигураторе) задать правила, по которым реквизит будет заполняться данными при создании нового объекта.
Если этих возможностей недостаточно, то тогда нужно использовать возможности встроенного языка.
Действия с данными объекта нужно выполнять в модуле объекта, в обработчике события ОбработкаЗаполнения. Этот событие возникает только при создании новых объектов, при открытии форм существующих объектов это событие не вызывается. Поэтому в нем не нужно узнавать, новый это объект, или нет. Нужно только описать алгоритм заполнения объекта данными. При этом следует учитывать, что это событие будет вызываться в нескольких случаях:
при интерактивном создании нового объекта,
при вводе на основании,
при выполнении метода объекта Заполнить().
При этом параметр Основание, передаваемый в этот обработчик, может иметь различные значения в зависимости от того, каким образом создается новый элемент.
Например, он может иметь тип ссылки, если новый объект вводится на основании.
Или он может иметь тип Структура, если новый объект создается интерактивной командой из списка, в котором установлен отбор. В этом случае структура будет содержать значения элементов отбора этого списка.
Также этот параметр может иметь тип Неопределено, если новый элемент создается интерактивной командой из панели действий. То есть в своем алгоритме начального заполнения полезно анализировать этот параметр.
Что касается внешнего вида формы нового объекта, то им нужно управлять в обработчике события формы ПриСозданииНаСервере.
Это событие возникает и для новых, и для существующих объектов. Поэтому в нем нужно убедиться в том, что открывается форма именно нового объекта. Убедиться в этом можно проанализировав параметр формы Ключ.
Если объект новый, в этом параметре будет пустая ссылка. Если это существующий объект – в этом параметре будет ссылка на этот объект:
Если требуется выполнять какие-то действия в обработчике события формы ПриОткрытии, то в нем ситуация аналогичная, нужно анализировать параметр формы Ключ.
Для тех кто не хочет читать все что выше, код проверки на ЭтоНовый в Управляемом приложении:
Мне частенько приходится взаимодействовать с 1С-разработчиками, и во время совместной работы над проектами замечаю, что далеко не все из них хорошо знают свой главный инструмент – «Конфигуратор». Причем это не относится к степени крутости девелопера. Как оказалось, даже синьоры пользуются далеко не всеми возможностями «Конфигуратора», а ведь они могут сэкономить кучу времени, а тем самым повысить продуктивность разработчика.
Под катом я решил собрать несколько полезных фишек стандартного конфигуратора, которыми пользуюсь регулярно. Многие из них появились в платформе «1С:Предприятие 8.3.х», поэтому перед тестированием обязательно проверьте номер версии установленной у вас платформы.
Закладки
Функция установки в коде закладок появилось еще с первых релизов 8-й версии платформы «1С:Предприятие». Штука чрезвычайно полезная и помогает разработчику быстрей передвигаться по коду. Например, у нас есть большой модуль, в который мы решили добавить ряд функций. Естественно, потом нам предстоит их отлаживать, а соответственно постоянно между ними переключаться.
Хорошо, если новые функции добавлены в самый конец модуля, а если потребовалось расположить в разных частях? Вот тут начинается самое интересное. Одни программисты начинают скролить текст (как правило, этим страдают новички). Более продвинутые применяют поиск по тексту (Ctrl + F).
Оба способа рабочие, но пользоваться ими долго. Куда правильней использовать функцию «закладки». Например, переходим к какой-нибудь строке. Нажимаем ALT + F2 и получаем закладку (слева от строки отобразиться квадратик).
Убирается закладка тем же сочетанием клавиш. Так вот, закладок может быть в модуле расставлено много. По ним легко передвигаться нажатием клавиши F2. Фича крутая, но она была изначально не доделана и не позволяла, например, передвигаться по закладкам в разных модулях. Это досадное ограничение создавало лишние тормоза для программистов, привыкших к хорошим IDE (например, Visual Studio, PHP Storm).
В версии 8.3 недочет исправили и сделали классную вещь – «Список закладок». Нажимаем клавиши «Ctrl + Shift + F2», и перед нами откроется окно с полным списком установленных закладок:
В нем перечислены все закладки в разрезе модулей. Для каждой закладки указан номер строк и доступен перечень действий: перейти к коду, удалить закладку, удалить все закладки.
Таким образом, работать с закладками стало на порядок проще. Еще бы добавили возможность установки горячих клавиш на закладки, и стало бы совсем хорошо. Помню еще со времен «Delphi 6» привык к установке закладок по горячим клавишам Alt + <Цифра>. Наставил закладок и быстро перемещайся по ним.
Группировка строк
В «1С:Предприятие» с самого начала была одна большая проблема – отсутствие возможности создавать дополнительные модули для определенных объектов. Например, есть у меня справочник «Контрагенты» и мне хочется разделить его функционал на модули. Допустим, функционала очеееень много. Так вот, в моем распоряжении все равно стандартный набор: Модуль объекта, Модуль менеджера и модуль формы. Понятное дело, что у каждого модуля своя роль, но что делать мне с моими 100500 функциями, которые относятся непосредственно к справочнику «Контрагенты»?
По мнению 1С я должен оформить их в виде общего модуля. С одной стороны, идея классная. Делаем модуль, его сразу видно и т.д., и т.п. Правда всегда есть один нюанс. Если следователь этой методике, то при наличии кучу объектов в конфигурации число общих модулей будет зашкаливать.
Вот взять хотя бы библиотеку БСП. Стоит ее внедрить и в количестве модулей начинает теряться. Я уже молчу про конфигурации, которые построены на базе БСП. Там и сто пятьсот модулей от БСП, и еще столько же специально для конфигурации.
В общем, неудобство налицо (особенно после опыта разработки в языках, где нет подобных ограничений). Увы, спастись от этой проблемы в настоящее время не получится. Зато, мы можем использовать возможности группировки функций/процедур в модулях.+
Например, есть у нас общий модуль «РаботаСКонтрагентами». В нем часть функций отвечают за поиск контрагента, другая часть за загрузку контрагентов из внешних источников и т.д. Чтобы не потеряться во всем этом многообразии возможностей, можно логически сгруппировать все функции/процедуру. Для этого в платформе 8.3 появилась функция под названием «Области». Рассмотрим пример:
После добавление областей (язык препроцессора) наш код будет сгруппирован. Если их свернуть (области), то в итоге мы увидим симпатичный комментарий (см. рисунок ниже):
Клик мышкой по плюсику развернет область, и мы увидим свернутые функции. Если хочется сразу развернуть все имеющиеся функции (в пределах области), то кликаем по плюсику удерживая Ctrl.
Вот такая мега удобная вещь и в модулях с большим количеством функций спасает очень даже. В предыдущих версиях платформы было модно использовать для подобных целей блоки комментариев, но управлять/добавлять областями явно удобней.
Форматирование кода
Собственно говоря, тут и рассказывать особо нечего – выделяем код, нажимаем «Alt + Shift + F» и редактор попытается привести его в божеский вид в соответствии с вшитым code-style. Функция работает вполне сносно и ей обязательно надо пользоваться. Пишу это потому, что неоднократно видел, как разработчики пытаются отбивать отступы самостоятельно. Это конечно круто, но зачем тратить время, если большую часть работы можно выполнить одной горячей клавишей?
Комментирование
Опять же, никаких секретных действий – выделили код, нажали “Ctrl + num /” (слеш на дополнительной области клавиатуры) и получили закомментированный участок. Захотели вернуть обратно? Не беда! Выделяем закомментированный участок кода, нажимаем «Ctrl + Shift + num /» и мгновенно приводим его в боевой режим. Фишка попсовая, но опять же, новички про нее не знают, и тратят кучу времени на расстановку слешей. Да еще и матерят компанию «1С», за отсутствие возможности многострочного комментирования, как в продвинутых язык программирования.
Быстрая вставка специальных символов
Иногда возникает необходимость быстро вставить в редактор специальный символ (которого нет на клавиатуре). В большинстве случаев разработчики используют для этого функции встроенного языка (например, символ). А ведь есть способ проще. Если удерживать клавишу Alt и набрать на доп. клавиатуре код нужного символа (из таблицы ASKII), то он тут же будет вставлен. Например, держим ALT и набираем 65. На выходе получаем букву «А». Или вводим 4 и получаем бубновую масть.
Вставка специальных символов
Хорошо, с этим понятно, но какой от этого еще можно получить профит? Лично я, таким образом вставляю символ амперсанда (&). Все знают, что этот символ используется для определения параметров в языке запросов. Неудобство состоит в том, что текст запроса мы пишем на русском языке, а для добавления этого символа перед параметром приходится переключить на английский, затем нажать Shift + 7, а потом вернуться обратно на русский.
Чтобы избавить себя от этой рутиной последовательности действий, я использую выше озвученную функцию. С ее помощью для установки амперсанда требуется лишь набрать с удержанной клавишей «alt» последовательность цифр 38. При этом надобность в двойном переключении языка отпадает.
Многие могут подумать, что я искусственно раздул проблему из ничего, но тут просто дело привычки. Кода приходится писать много и вот такие мелочи немного повышают производительность и избавляют от лишних нажатий клавиши backspace (для удаления случайно набранных символов). Не убедил? Тогда просто выделите время и попробуйте себя переучить
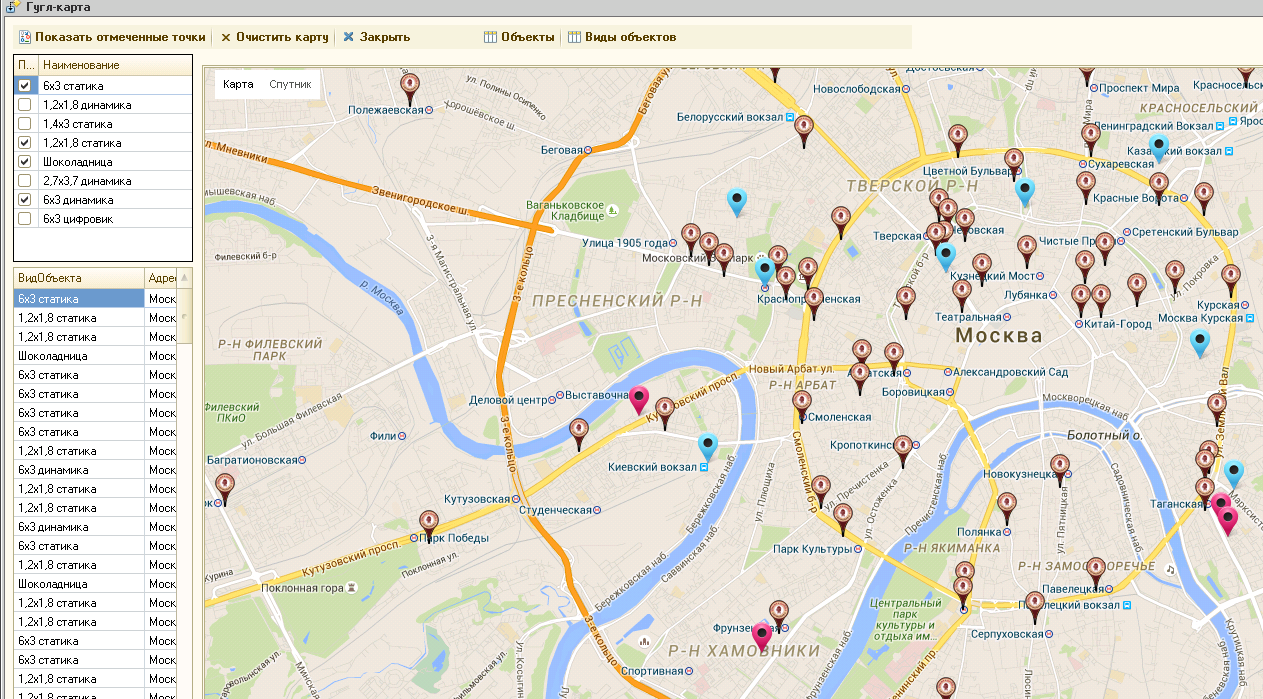
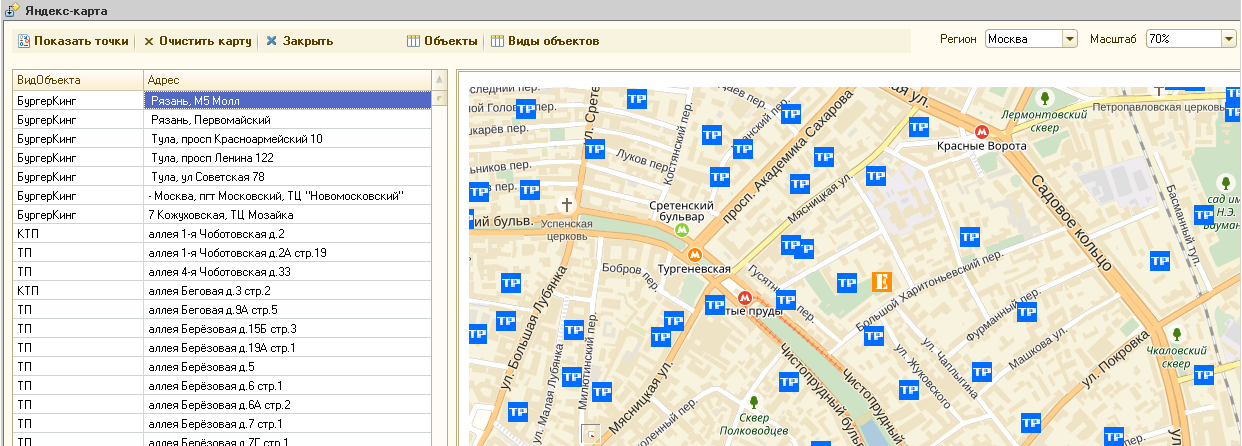
В отличие от яндекс карт в GMaps можно использовать панорамы - за что им большой плюс! Надеюсь в яндексе прочитают этот пост и тоже когда-нибудь это сделают!
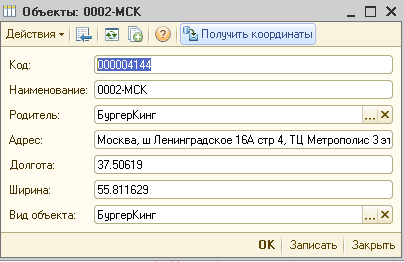
Для клиента нужно было сделать вывод объектов на карту
У управляемой формы реквизиты заведенные как реквизиты формы, при закрытии и открытии ее заново могут сохраняться и восстанавливаться, достаточно только поставить напротив галочку сохранять и в свойствах формы выбрать "АвтоматическоеСохранениеДанныхВНастройках" - Использовать.
Полнотекстовый поиск - позволит найти текстовую информацию, размещенную практически в любом месте используемой конфигурации. При этом искать нужные данные можно либо по всей конфигурации в целом, либо сузив область поиска до нескольких объектов (например, определенных видов документов или справочников). Сами критерии поиска могут варьироваться в довольно широком диапазоне. То есть найти нужные данные можно, даже не помня точно, где они хранятся в конфигурации и как именно записаны.
Полнотекстовый поиск предоставляет следующие возможности:
Есть поддержка транслитерации (написание русских слов символами латиницы в соответствии с ГОСТ 7.79-2000). Пример: "русская фраза" = "russkaya fraza".
Есть поддержка замещения (написание части символов в русских словах одноклавишными латинскими символами). Пример: "руссrfz фраpf" (окончания каждого слова набраны латиницей, допустим, в результате ошибки оператора).
Есть возможность нечеткого поиска (буквы в найденных словах могут отличаться) с указанием порога нечеткости. Пример: указав в строке поиска слово "привет" и нечеткость 17 %, найдем все аналогичные слова с ошибками и без: "привет", "превет", "привед".
Есть возможность указать область выполнения поиска по выбранным объектам метаданных.
Полнотекстовое индексирование названий стандартных полей ("Код", "Наименование" и т. д.) производится на всех языках конфигурации.
Поиск выполняется с учетом синонимов русского, английского и украинского языков.
Морфологический словарь русского языка содержит ряд специфических слов, относящихся к областям деятельности, автоматизируемым с помощью системы программ "1С:Предприятие".
Стандартно в состав поставляемых словарей включены словарные базы и словари тезауруса и синонимов русского, украинского и английского языков, которые предоставлены компанией "Информатик".
Поиск можно осуществлять с использованием подстановочных символов ("*"), а также с указанием поисковых операторов ("И", "ИЛИ", "НЕ", "РЯДОМ") и спецсимволов.
Полнотекстовый поиск можно осуществлять в любой конфигурации на платформе 1С:Предприятие 8
Для того чтобы открыть окно управления полнотекстовым поиском необходимо выполнить следующее:
Обычное приложение - пункт меню Операции - Управление полнотекстовым поиском.
Управляемое приложение - пункт меню Главное меню - Все функции - Стандартные - Управление полнотекстовым поиском.
Обновить индекс – Создание индекса/Обновление индекса;
Очистить индекс – обнуление индекса(рекомендуется после обновления всех данных);
пункт Разрешить слияние индексов – отвечает за слияние основного и дополнительного индекса.
Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.
Как вы можете заметить свойство Использовать установлено для всего справочника Контрагенты, но сделать это можно и для каждого его реквизита соответствующего типа.
Рассмотрим более подробно полнотекстовый индекс, который состоит из двух частей (индексов): основного индекса и дополнительного. Высокая скорость поиска данных обеспечивается за счет основного индекса, но обновление его происходит относительно медленно, в зависимости от объема данных. Дополнительный индекс ему противоположен. Данные добавляются в него намного быстрее, но поиск осуществляется медленнее. Система осуществляет поиск одновременно в обоих индексах. Большая часть данных находится в основном индексе, а данные добавляемые в систему попадают в дополнительный индекс. Пока объем данных в дополнительном индексе небольшой, поиск по нему происходит относительно быстро. В тот момент, когда нагрузка на систему невелика, происходит операция слияния индексов, в результате чего дополнительный индекс очищается, а все данные помещаются в основной индекс. Слияние индексов предпочтительнее выполнять в тот момент времени, когда нагрузка на систему минимальна. С этой целью можно создавать регламентированные задания и задания по расписанию.
Специальные операторы, допустимые при задании поискового выражения
Механизм полнотекстового поиска допускает написание части символов русского слова одноклавишными латинскими символами. Результат поиска при этом не измениться.
Два оператора РЯДОМ
упрощенный. На расстоянии 8 слов друг от друга
РЯДОМ/[+/-]n – поиск данных в одном реквизите на расстоянии n-1 слов между ними.
Знак указывает в каком направлении от первого слова будет поиск второго. (+ - после, - до)
Групповой символ «*» может использоваться только в качестве замены конца слова
Оператор нечеткости «#». Если неизвестно точное написание названия, имени.
Программными средствами и средствами 1с: программирование.
Оператор синонимов «!». Позволяет найти слово и его синонимы
Как программно обновить индекс полнотекстового поиска?
Пример полнотекстового поиска данных
Определение переменной СписокПоиска
Кроме этого в процедуре обработки события ПриОткрыии формы определим, что эта переменная будет содержать список полнотекстового поиска, с помощью которого мы и будем осуществлять поиск в данных
Теперь для события нажатия на кнопку Найти напишем код, который позволит нам выполнять поиск в соответствии с тем выражением, которое задано в поле ПоисковоеВыражение
Сначала в этой процедуре мы устанавливаем поисковое выражение, введенное пользователем, в качестве строки поиска для полнотекстового поиска. Затем выполняем метод ПерваяЧасть(), который собственно запускает полнотекстовый поиск и возвращает первую порцию результатов. По умолчанию порция содержит 20 элементов. После этого мы анализируем количество элементов в списке поиска. Если он не содержит ни одного элемента, то мы выводим в форму соответствующее сообщение. В противном случае вызывается процедура ВывестиРезультатПоиска(), которая отображает полученные результаты пользователю.
Создадим в модуле формы процедуру с таким именем и напишем в ней код,
Действия, выполняемые в этой процедуре, просты. Сначала мы формируем сообщение о том, какие элементы отображены и сколько всего элементов найдено. Затем получаем результат полнотекстового поиска в виде HTML-текста и выводим этот текст в поле HTML-документа, расположенное в форме.
В заключение передаем управление в процедуру ДоступностьКнопок() для того, чтобы сделать доступными или, наоборот, запретить доступ к кнопкам Предыдущая порция и Следующая порция (в зависимости от того, какая порция полученных результатов отображена). Текст этой процедуры представлен в Коде
Теперь необходимо создать обработчики событий нажатия на кнопки ПредыдущаяПорция() и СледующаяПорция().
Заключительным «штрихом» будет создание обработчика события onclick поля HTML-документа, расположенного в форме. Дело в том, что результат полнотекстового поиска, представленный в виде HTML-текста, содержит гиперссылки на номера элементов списка поиска. И нам хотелось бы, чтобы при переходе пользователя на эту ссылку система открывала бы форму того объекта, который содержится в этом элементе списка. Для этого мы будем перехватывать событие onclick HTML-документа, содержащегося в поле HTML-документа, получать номер элемента списка из гиперссылки и открывать форму соответствующего объекта. Текст обработчика события onclick поля HTML-документа представлен в коде
В процессе работы предприятия нередко возникает необходимость узнать кто, когда и что именно изменял в документе или справочнике программы.
Очень часто мне задают вопросы:
Как в 1С 8.2 посмотреть поменявшего документ?
Как в 1с посмотреть изменившего документ?
Как в 1С узнать кто и когда изменял документы?
Как в 1С узнать кто изменил проводку в документе?
Как посмотреть кто изменял документ в 1с?
Журнал регистрации
Содержит информацию о том, какие события происходили в информационной базе в определенный момент времени или какие действия выполнял тот или иной пользователь. Для каждой записи журнала, отражающей изменение данных, отображается статус завершения транзакции (транзакция завершена успешно, или же транзакция отменена).
Журнал регистрации доступен как в режиме 1С:Предприятие, так и в режиме Конфигуратор.
Доступ к журналу регистрации возможен как из режима Конфигуратора (через меню Администрирование - Журнал регистрации), так и из режима Предприятия (меню Сервис - Журнал регистрации). В режиме Такси (Основное меню - Все функции - Стандартные - Журнал регистрации)
Вид журнала регистрации (Обычные формы и Такси):
Отбор в журнале регистрации (Обычные формы и Такси):
Используя средства работы со списками имеется возможность выгрузить журнал регистрации в табличный или, при необходимости, текстовый документ (через Действия - Вывести список) , который в дальнейшем может быть сохранен например в формате Excel , TXT или HTML. При этом существует возможность настройки уровня событий, которые будут фиксироваться в журнале регистрации, а также периодичности разделения журнала на отдельные файлы (в режиме конфигуратора меню Администрирование - Настройка журнала регистрации).
И там же есть возможность сократить количество записей данного журнала до определенной даты, что делается для ускорения работы с механизмом анализа и регистрации событий в системе или за ненадобностью неактуальной информации.
Где хранится журнал регистрации
В Файловой базе: в каталоге базы папка 1Cv8Log - это и есть директория содержащая журнал регистрации.
Если вы планируете перенести файловую базу данных и хотите сохранить историю журнала регистрации & вам обязательно надо скопировать папку 1Cv8Log в категорию новой базы 1С. Если необходимо очистить журнал регистрации 1С в файловой базе просто удалите папку 1Cv8Log.
В Клиент-серверной базе: C:\Program Files\1cv8\srvinfo\<Имя кластера сервера>\<Идентификатор базы на сервере>\1Cv8Log
С версии 8.3.5.1068. Значительно переработали журнал регистрации для того, чтобы увеличить скорость выполнения запросов к журналу и повысить надёжность хранения данных.
Для этого, в том числе, потребовалось изменить формат хранения журнала регистрации. Теперь он хранится в одном файле базы данных SQLite. Этот файл имеет расширение lgd.
Версионирование объектов
В некоторых конфигурациях 1С внедрен специальный механизм «Версионирование объектов».
По умолчанию версионирование выключено, чтобы включить откройте Сервис - Настройки учета - Настройка параметров учета
По кнопке «Настройка версионирования объектов» выбираем, какие справочники и документы нужно версионировать (наблюдать за тем, кто, что и когда изменил).
По умолчанию наблюдение за объектами информационной базы не ведется, поетому напротив каждого типа документов установлен признак «Не версионировать». Если нужно чтоб наблюдение велось, нужно установить «Версионировать» напротив интересующего журнала документов.
Все, при закрытии окна и нажатии на кнопку «Оk» наблюдение за объектами будет вестись.
Для того чтоб просмотреть все изменения которые кто-то делал в документе или справочнике нужно перейти в меню: Сервис - История изменений объектов
Пример создания внешней печатной формы АКТа для Бухгалтерии 3.0
1. В конфигураторе 1C Предприятия 8 создаем внешнюю обработку (Файл->Новый->Внешняя обработка), задаем имя.
2. В модуле обработки пишем код. Постараюсь его максимально комментировать. Главное должно быть:
функция ПечатьВнешнейПечатнойФормы табличного документа - которая выведет данные в макет
функция Печать - вызывается из конфигурации! в нее передается массив печатаемых объектов
и функция СведенияОВнешнейОбработке(). Она необходима для регистрации печатной формы в справочнике ДополнительныеОтчетыИОбработки, в ней собирается структура с данными для подключения формы. Эта функция, а также ряд сопутствующих ей, практически одинаковы для всех печатных форм, поэтому их можно просто копировать в новую печатную форму ничего не меняя.
3. Добавляем макет вывода печатной формы:
4. Сохраняем и добавляем в конфигурацию:
Подключается через Администрирование - Печатные формы, отчеты и обработки:
Создаете новую обработку, записывайте и при открытии документа Реализация, нажав на Печать - появляются доступные печатные формы с разными подписывающими.
На днях делал несколько однотипных отчетов на СКД.
Общий принцип: формируются все варианты отчета, указанные в настройках схемы и каждый вариант выводится на отдельной вкладке.
Потом возникла мысль попробовать объединить все схемы в один отчет, чтобы не плодить лишних объектов в конфигурации. При этом количество вариантов в этих схемах заранее неизвестно. Ok, challenge accepted.
В тестовой конфигурации создаю для отчета две схемы компоновки, "Склад" и "Заявки".
Запросы наборов данных приводить не буду, для каждой схемы в настройках добавляю несколько вариантов отчетов.
Теперь переходим к созданию формы. Практически все реквизиты формы будут создаваться при выборе необходимого макета отчета.
Передать информацию о контрагентах из УП в БП. Данные передаются в одностороннем порядке, идентификация производится по уникальному идентификатору.Настройка правил конвертации выполняется с помощью специальной конфигурации Конвертация данных, редакция 3.0 (далее – КД 3.0).
Выполняемые действия
Этап 1. Подготовка к настройке правил.
Для настройки правил конвертации в конфигурации КД 3.0 должны содержаться сведения о структуре информационных баз, между которыми производится синхронизация данных, а также о структуре формата Enterprise Data.
Шаг 1. Выгрузка структуры информационных баз УП и БП.
Для выгрузки информации о структуре информационной базы используется обработкаMD83Exp.epf, входящая в комплект поставки конфигурации КД 3.0.
Для каждой информационной базы (УП и БП) необходимо выполнить следующие действия:
Открыть информационную базу в режиме “Предприятие”.
Указать имя файла, в который следует сохранить структуру информационной базы.
Проверить настройки в форме обработки (все флаги должны быть сняты).
Нажать кнопку Выгрузить.
Шаг 2. Экспорт xml-схемы формата обмена
Для выгрузки схемы формата обмена используются стандартные возможности платформы.
Необходимо выполнить следующие действия:
Открыть одну из информационных баз (либо УП либо БП) в режиме “Конфигуратор”.
В дереве метаданных найти XDTO пакеты с именами ExchangeMessage иEnterpriseData_1_0_beta.
Установить курсор на пакет XDTO, нажать правую кнопку мыши и в контекстном меню выбрать пункт Экспорт XML-схемы. Указать путь и имя файла для экспорта. Выполнить это действие для каждого из двух пакетов, сохранив XML-схемы в два разных файла.
Шаг 3. Загрузка структуры информационных баз в конфигурацию КД 3.0
Загрузка выполняется в конфигурацию КД 3.0 в режиме “Предприятие”. Перечисленные ниже действия следует выполнить для каждой из конфигураций, для которых настраиваются правила конвертации (УП и БП).
Перейти в раздел Конфигурации, и выбрать команду Загрузка структуры конфигурации.
Указать путь к файлу со структурой информационной базы (см. Этап 1, Шаг 1).
Указать способ загрузки & в новую версию конфигурации.
Нажать кнопку Выполнить загрузку, дождаться окончания загрузки.
Шаг 4. Загрузка структуры формата обмена в конфигурацию КД 3.0
Загрузка выполняется в конфигурацию КД 3.0 в режиме “Предприятие”.
Перейти в раздел Формат данных, и выбрать команду Загрузка структуры формата.
Указать файлы со структурой формата (см. Этап 1, Шаг 2). Необходимо указать сразу оба файла, используя множественный выбор.
Проверить имя основного пакета XDTO – должен совпадать с пространством имен пакета XDTO EnterpriseData_1_0_beta (см. в конфигураторе УП или БП).
Указать способ загрузки & в новую версию формата.
Нажать кнопку Выполнить загрузку, дождаться окончания загрузки.
Этап 2. Создание конвертаций
Для решения описанной задачи необходимо создать две конвертации:
УП (для выгрузки данных из УП в формат обмена)
БП (для загрузки данных из формата обмена в БП)
Создание конвертаций производится в разделе Конвертации, команда Конвертации. Для новой конвертации необходимо указать наименование, конфигурацию и формат обмена. Например, конвертация для конфигурации УП:
Наименование & “УП2.0.7”.
Конфигурация & “УправлениеПредприятием”.
Поддерживаемые версии формата & одна строка, в которой выбрана единственная позиция справочника Версии формата.
Далее для каждой из двух конвертаций требуется настроить правила:
правила обработки данных,
правила конвертации объектов,
правила конвертации предопределенных данных.
Для перехода к комплекту правил конкретной конвертации необходимо перейти в разделКонвертации, выбрать команду Настройка правил конвертации и выбрать в списке конкретную конвертацию, для которой будут настраиваться правила. В результате будет открыта форма Настройка правил обмена, в которой собраны все правила для конкретной конвертации.
Этап 3. Создание правил конвертации объектов
Шаг 1. Правило конвертации для выгрузки контрагентов из УП
Открыть настройку правил обмена для конвертации УП.
Перейти на закладку Правила конвертации объектов.
Создать новое правило конвертации и заполнить данные на закладке Основные сведения:
В открывшейся форме нажать Автосопоставление. Сопоставятся свойства “ИНН”, “КПП”, “Наименование”, “НаименованиеПолное”, “ДополнительнаяИнформация”, “ЮридическоеФизическоеЛицо”
Сохранить результат автоматического сопоставления & нажать кнопкуСоздать правила конвертации свойств и закрыть форму настройки правил конвертации свойств
Вручную добавить правило конвертации свойства для ОКПО (свойство конфигурации & “КодПоОКПО”, свойство формата & “ОКПО”).
Позже потребуется вернуться к правилам конвертации свойств, чтобы заполнить правило конвертации свойства для свойства “ЮридическоеФизическоеЛицо”, которое является перечислением.
Нажать кнопку Записать и закрыть.
Шаг 2. Правило конвертации для загрузки контрагентов в БП
Открыть настройку правил обмена для конвертации БП.
Перейти на закладку Правила конвертации объектов.
Создать новое правило конвертации и заполнить данные на закладке Основные сведения:
В открывшейся форме нажать Автосопоставление. Сопоставятся свойства “ИНН”, “КПП”, “Наименование”, “НаименованиеПолное”, “ДополнительнаяИнформация”, “ЮридическоеФизическоеЛицо”.
Сохранить результат автоматического сопоставления & нажать кнопкуСоздать правила конвертации свойств и закрыть форму настройки правил конвертации свойств.
Вручную добавить правило конвертации свойства для ОКПО (свойство конфигурации & “КодПоОКПО”, свойство формата & “ОКПО”).
Позже потребуется вернуться к правилам конвертации свойств, чтобы заполнить правило конвертации свойства для свойства “ЮридическоеФизическоеЛицо”, которое является перечислением.
Перейти на закладку ПередЗаписьюПолученныхДанных и написать алгоритм для заполнения страны регистрации нового контрагента. Алгоритм содержит следующий текст: «ПолученныеДанные.СтранаРегистрации = Справочники.СтраныМира.Россия;».
Нажать кнопку Записать и закрыть.
Этап 4. Создание правил конвертации предопределенных данных
Порядок действий одинаков для обоих конвертаций.
Открыть настройку правил обмена для конвертации (УП или БП)
Перейти на закладку Правила конвертации предопределенных данных
Создать новое правило конвертации и заполнить его свойства:
Объект конфигурации: “ПеречислениеСсылка.ЮридическоеФизическоеЛицо”
Объект формата: “ЮридическоеФизическоеЛицо”
Область применения: для отправки и получения
В табличном поле заполнить соответствия значений перечисления конфигурации и формата: “ФизическоеЛицо” & “ФизическоеЛицо” и “ЮридическоеЛицо” & “ЮридическоеЛицо”
Нажать кнопку Записать и закрыть
Указать новое правило в правиле конвертации свойства “ЮридическоеФизическоеЛицо” справочника Контрагенты
Перейти на закладку Правила конвертации объектов
Найти правило конвертации справочника Контрагенты, открыть форму правила
Перейти на закладку Правила конвертации свойств и найти правило для свойства “ЮридическоеФизическоеЛицо”
Открыть форму правила конвертации свойства и указать в нем правило конвертации объекта & “Перечисление_ЮридическоеФизическоеЛицо”.
Сохранить внесенные изменения
Этап 5. Создание правил обработки данных
Порядок действий одинаков для обоих конвертаций.
Открыть настройку правил обмена для конвертации (УП или БП)
Перейти на закладку Правила конвертации объектов
Найти правило конвертации справочника Контрагенты, открыть форму правила
Нажать кнопку Создать на основании & Правило обработки данных
В созданном правиле обработки данных проверить заполнившиеся автоматически свойства:
Идентификатор правила & указать такой же как для правила обработки данных (“Справочник_Контрагенты_Отправка” либо “Справочник_Контрагенты_Получение”)
Область применения & такая же как для правила обработки данных
Объект выборки:
для конвертации УП & “СправочникСсылка.Контрагенты”
для конвертации БП & “Справочник.Контрагенты”
Правило конвертации объекта & ссылка на правило конвертации объекта.
Нажать кнопку Записать и закрыть.
Этап 6. Получение модулей менеджера обмена данными
Модуль менеджера обмена данными необходим для обмена данными между конфигурациями в соответствии с настроенными в КД 3.0 правилами.
Порядок действий одинаков для обеих конвертаций:
Открыть информационную базу УП или БП в режиме “Конфигуратор”. Найти в дереве метаданных общий модуль МенеджерОбменаЧерезУниверсальныйФормат и открыть его для редактирования. Модуль должен быть пустым.
Открыть информационную базу КД 3.0 в режиме “Предприятие”.
Перейти в раздел Конвертации и выбрать команду Выгрузка модуля.
В открывшейся форме указать соответствующую конвертацию и нажать кнопку Выгрузить. Модуль будет скопирован в буфер обмена.
Перейти в конфигуратор информационной базы УП или БП и вставить содержимое буфера обмена в общий модуль МенеджерОбменаЧерезУниверсальныйФормат.
Сохранить конфигурацию.
Выгрузка модуля в буфер обмена также может производиться из формы настройки правил обмена по кнопке Сохранить модуль менеджера обмена.
Для того чтобы по настроенным правилам выполнялся обмен данными, необходимо в обеих информационных базах в режиме “Предприятие” настроить синхронизацию данных через универсальный формат.
 Добавление дополнительных отчетов и обработок в тонком клиенте БП 3.0, ЗУП 3.0, УТ 11
Добавление дополнительных отчетов и обработок в тонком клиенте БП 3.0, ЗУП 3.0, УТ 11 
















 нет - напишем:
нет - напишем:


 Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах
Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах 
 Очень часто мне задают вопросы:
Очень часто мне задают вопросы: 














.gif)