 Как получить координаты выделенной области на Яндекс Карте?
Как получить координаты выделенной области на Яндекс Карте? На одном проекте потребовалось получать координаты выделенной области на яндекс карте, после долгих изучений получилось следующее:
Вид Формы: На карте выделяете объект, нажимаете кнопку Получить координаты выделенной области и заполняется таблица координат

Код инициализации карты и обработчик кнопки получения координат:
Макет
Установка сервера 1С 8.3 и PostgreSQL 9.2 на CentOS Заказали виртуальный сервер на FastVPS, купили мини сервер 1С и пришло время установки.
В сети нашлась хорошая статья, где все по порядку:
Итак, устанавливаем минимальный CentOS, настраиваем имена хостов, DNSы и сетевые подключения и приступаем собственно к установке серверных компонентов.
1. Установка Postgre SQL server
Обновление от 03-ноя-2016: в последних версиях CentOS (у меня сегодня был 7.2.1511) отсутствует поддержка libtermcap (и как-то "иначе" реализована libreadline), из-за чего сборки с сайта 1С не устанавливаются - решил поставить сборку от Postgres Professionals https://postgrespro.ru/products/1c_build - вроде работает, но о стабильности и производительности пока судить рано. Так что у кого проблемы с libtermcap.so.2() и/ли libreadline.so.5() при установке PostgreSQL с патчами 1С, можете попробовать этот альтернативный вариант.
Для установки использовался рекомендованный (адаптированный) 1С дистрибутив, для чего потребуется скачать его из раздела поддержки пользователей сайта 1С. В моём случае это был "Дистрибутив СУБД PostgreSQL для Linux x86 (64-bit) одним архивом (RPM)", который я сохранил в /root/temp. Распаковываем архив:
[root@vm-sql01 temp]# tar -vxf postgresql-9.2.1-1.1C_x86_64_rpm.tar.gz
postgresql92-9.2.1-1.1C.x86_64.rpm
postgresql92-libs-9.2.1-1.1C.x86_64.rpm
postgresql92-server-9.2.1-1.1C.x86_64.rpm
postgresql92-contrib-9.2.1-1.1C.x86_64.rpm
[root@vm-sql01 temp]#
Устанавливаем в следующей последовательности:
yum install postgresql92-libs-9.2.1-1.1C.x86_64.rpm
yum install postgresql92-9.2.1-1.1C.x86_64.rpm
yum install postgresql92-server-9.2.1-1.1C.x86_64.rpm
yum install postgresql92-contrib-9.2.1-1.1C.x86_64.rpm
Все недостающие зависимости (пакеты) будут установлены в процессе установки этих rpm, хотя на сайте 1С рекомендуют предварительно установить пакеты readline, libtermcap, krb5-libs и openssl, но в моём случае они либо уже были установлены, либо не были обнаружены в репозиториях.
2. Первый запуск Postgre SQL server
В отличии от сценариев установки большинства знакомых мне sql-серверов, postgres требует предварительной инициализации перед запуском, для чего существует два пути - первый, правильный:
[root@vm-sql01 pgsql]# su postgres -c '/usr/pgsql-9.2/bin/initdb -D /var/lib/pgsql/9.2/data --locale=ru_RU.UTF-8'
Файлы, относящиеся к этой СУБД, будут принадлежать пользователю "postgres".
От его имени также будет запускаться процесс сервера.
Кластер баз данных будет инициализирован с локалью "ru_RU.UTF-8".
Кодировка БД по умолчанию, выбранная в соответствии с настройками: "UTF8".
Выбрана конфигурация текстового поиска по умолчанию "russian".
исправление прав для существующего каталога /var/lib/pgsql/9.2/data... ок
создание подкаталогов... ок
выбирается значение max_connections... 100
выбирается значение shared_buffers... 32MB
создание конфигурационных файлов... ок
создание базы template1 в /var/lib/pgsql/9.2/data/base/1... ок
инициализация pg_authid... ок
инициализация зависимостей... ок
создание системных представлений... ок
загрузка описаний системных объектов... ок
создание правил сортировки... ок
создание преобразований... ок
создание словарей... ок
установка прав для встроенных объектов... ок
создание информационной схемы... ок
загрузка серверного языка PL/pgSQL... ок
копирование template1 в template0... ок
копирование template1 в postgres... ок
ВНИМАНИЕ: используется проверка подлинности "trust" для локальных подключений.
Другой метод можно выбрать, отредактировав pg_hba.conf или используя ключи -A,
--auth-local или --auth-host при следующем выполнении initdb.
Готово. Теперь вы можете запустить сервер баз данных:
/usr/pgsql-9.2/bin/postgres -D /var/lib/pgsql/9.2/data
или
/usr/pgsql-9.2/bin/pg_ctl -D /var/lib/pgsql/9.2/data -l logfile start
-bash-4.1$
Или тот же вывод на английском языке:
[root@vm-sql01 ~]# su postgres -c '/usr/pgsql-9.2/bin/initdb -D /var/lib/pgsql/9.2/data --locale=ru_RU.UTF-8'
could not change directory to "/root"
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "ru_RU.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "russian".
fixing permissions on existing directory /var/lib/pgsql/9.2/data ... ok
creating subdirectories ... ok
selecting default max_connections ... 100
selecting default shared_buffers ... 32MB
creating configuration files ... ok
creating template1 database in /var/lib/pgsql/9.2/data/base/1 ... ok
initializing pg_authid ... ok
initializing dependencies ... ok
creating system views ... ok
loading system objects' descriptions ... ok
creating collations ... ok
creating conversions ... ok
creating dictionaries ... ok
setting privileges on built-in objects ... ok
creating information schema ... ok
loading PL/pgSQL server-side language ... ok
vacuuming database template1 ... ok
copying template1 to template0 ... ok
copying template1 to postgres ... ok
WARNING: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the option -A, or
--auth-local and --auth-host, the next time you run initdb.
Success. You can now start the database server using:
/usr/pgsql-9.2/bin/postgres -D /var/lib/pgsql/9.2/data
or
/usr/pgsql-9.2/bin/pg_ctl -D /var/lib/pgsql/9.2/data -l logfile start
[root@vm-sql01 ~]#
Или второй, более простой, но не всегда дающий необходимый результат (зависит от региональных настроек сервера, но у меня иногда приводивший к установке базы данных без поддержки необходимого collation ru_RU.UTF-8):
[root@vm-sql01 pgsql]# service postgresql-9.2 initdb
Инициализируется база данных: [ OK ]
[root@vm-sql01 pgsql]#
В результате была создана структура базы данных (с настройками) в /var/lib/pgsql/9.2/data. Хочу обратить особое внимание на конструкцию --locale=ru_RU.UTF-8, которую необходимо указать при инициализации, иначе сервер может быть инициализирован с неверным набором языковых параметров, что в конечном итоге приведёт к сообщениям
Ошибка установки или изменения национальных настроек информационной базы
Порядок сортировки не поддерживается базой данных
по причине:
Порядок сортировки не поддерживается базой данных
при установке информационной базы. Теперь можно настраивать автоматический запуск sql-сервера и, собственно, запускать его:
[root@vm-sql01 temp]# chkconfig postgresql-9.2 on
[root@vm-sql01 temp]# service postgresql-9.2 start
Запускается служба postgresql-9.2: [ OK ]
[root@vm-sql01 temp]#
Всё. Для локальных подключений сервер настроен. В моём случае сервер 1С и сервер SQL находятся на разных машинах, поэтому потребуется настроить и удалённые подключения с авторизацией.
В случае каких-то проблем, читаем содержимое файлов:
/var/lib/pgsql/9.2/pgstartup.log
/var/lib/pgsql/9.2/data/postgresql-*.log
Для повышения быстродействия документация PostgreSQL рекомендует как минимум унести журнал /var/lib/pgsql/9.2/data/pg_xlog на отдельный физический том и создать симлинк на него в исходном месте; из личных наблюдений - надо ещё и значительно увеличить размер используемой памяти... но необъятное не охватить, поэтому за статьями по оптимизации работы PostgreSQL для 1С предлагаю обращаться в поисковые системы, а оттуда - на профильные форумы.
3. Настройка пользователей (ролей) Postgre SQL server
Для управления PostgreSQL на начальном этапе потребуется сменить текущего пользователя на postgres и создать нового пользователя из командной строки:
[root@vm-sql01 temp]# su - postgres
-bash-4.1$ cd /usr/pgsql-9.2/bin
-bash-4.1$ createuser --interactive -P
Введите имя новой роли:server1c
Введите пароль для новой роли:
Повторите его:
Должна ли новая роль иметь полномочия суперпользователя? (y - да/n - нет) n
Новая роль должна иметь право создавать базы данных? (y - да/n - нет) y
Новая роль должна иметь право создавать другие роли? (y - да/n - нет) n
-bash-4.1$ exit
logout
[root@vm-sql01 temp]#
В принципе, для обслуживания полезно иметь пользователя с правами суперпользователя - создавать его можно тем же путём.
Теперь осталось разрешить удалённое подключение с авторизацией - для этого в файле /var/lib/pgsql/9.2/data/pg_hba.conf потребуется заменить значение ident на md5 в строке "host all all 0.0.0.0/0 md5" и перезапустить сервис.
Не следует забывать и про настройки iptables - для работы Postgre SQL необходимо открыть как минимум порт tcp 5432, хотя привычнее (да и проще) объявить сетевой интерфейс "внутренним" (разрешить все подключения на интерфейсе).
Для управления сервером потребуется pgAdmin, который можно установить из репозиториев используемого для административных целей линукса, либо скачать с сайта проекта.
4. Установка компонентов сервера 1С
Внимание!!! Для избежания проблем с зависимостями, желательно, чтобы разрядность сервера 1С совпадала с разрядностью используемого дистрибутива Linux! Иначе (если ставим 32-битный 1С на 64-битный Linux), при входе в базу, можно получить сообщение типа "Ошибка загрузки библиотеки libWand.so по причине:Библиотека не обнаружена. Часть функций будет недоступна." и клиенты не будут запускаться (хотя конфигуратор - будет). В принципе, я с этой проблемой справился на CentOS 7 (которой не выпускают больше в 32-битном исполнении) - просто поставил не только 'ImageMagick', но и 'ImageMagick.i686' (yum install ImageMagick.i686) - всё заработало (хоть и притянуло за собой гору зависимостей).
Первый шаг установки сервера 1С мало отличается от аналогичного этапа с SQL-сервером - распаковать скачанный дистрибутив сервера командой tar -vxf rpm64.tar.gz. В итоге получим файлы:
1C_Enterprise83-common-8.3.3-715.x86_64.rpm - основные файлы 1С (включая русский и английский интерфейсы)
1C_Enterprise83-common-nls-8.3.3-715.x86_64.rpm - дополнительные языковые модули
1C_Enterprise83-server-8.3.3-715.x86_64.rpm - сервер 1С
1C_Enterprise83-server-nls-8.3.3-715.x86_64.rpm - дополнительные языковые модули
1C_Enterprise83-ws-8.3.3-715.x86_64.rpm - компоненты вэб-сервера 1С
1C_Enterprise83-ws-nls-8.3.3-715.x86_64.rpm - дополнительные языковые модули
1C_Enterprise83-crs-8.3.3-715.i386.rpm - хранилище конфигураций (только в 32-битном комплекте)
Устанавливаем нужные пакеты командами:
yum install 1C_Enterprise83-common-8.3.3-715.x86_64.rpm
yum install 1C_Enterprise83-server-8.3.3-715.x86_64.rpm
Настраиваем автоматический запуск демона и стартуем его:
[root@vh-1c83 temp]# chkconfig srv1cv83 on
[root@vh-1c83 temp]# service srv1cv83 start
Starting 1C:Enterprise 8.3 server: Error: service failed to start!
FAILED
[root@vh-1c83 temp]# service srv1cv83 start
Starting 1C:Enterprise 8.3 server: OK
[root@vh-1c83 temp]#
Хочу обратить внимание - если сразу после установки сервис (как в приведённом примере) не стартовал, а при второй попытке старта он запустился, скорее всего не настроен DNS - об этом чуть ниже. Если верить информации с многочисленных форумов, то наш сервер уже готов обслуживать до 12 клиентов. Для работы большего числа пользователей, необходимо установить лицензию сервера - либо в виде USB HASP и драйвера, либо в виде электронной лицензии. Про установку аппаратных ключей я уже писал, а установка программных лицензий достаточно проста: запускаем конфигуратор (с клиентской машины; кластер уже должен быть настроен и должна быть информационная база), вызываем "Сервис" - "Получение лицензии", вводим номер комплекта (с коробки или "Регистрационный номер" с карточки из конверта "Пинкоды программной лицензии") и пин-код (с той самой карточки из конверта), ставим галочку "Установка на сервер", вводим имя сервера в соответствующем поле, нажимаем "Далее", говорим, что это - "Первый запуск", заполняем форму "Владелец лицензии" (к стати, я не понял что писать в полях "Фамилия", "Имя", "Отчество" - то ли ответственного за эксплуатацию, то ли генерального директора - оставил поля пустыми, и оно получило лицензию, не ругнувшись), "Далее", "Автоматически" - профит! в /var/1C/licenses на сервере появился файлик XXXXXXXXXXXXXX.lic и серверу "стало хорошо" (если это была многопользовательская лицензия, то клиентам тоже "станет хорошо", т.к. они будут получать лицензии на сервере).
Для работы с графическими объектами и экспорта в xls, могут потребоваться дополнительные пакеты: ImageMagick, freetype (входит в зависимости ImageMagick), libgsf (входит в зависимости ImageMagick), corefonts (отсутствует в репозитариях CentOS - см. раздел 6); для "ТАКСИ" и "Управляемого приложения" они необходимы, для классического толстого клиента вроде бы не особо нужны, но 1С всё равно ругается на их отсутствие, хоть и работает.
По умолчанию сервер 1С слушает порт tcp 1541(1540) и для соединений использует диапазон портов 1560-1691.
5. Настройка экземпляра (кластера) сервера 1С
Информации о наличии оснастки управления сервером 1С для Linux мне не попадалось, так что для управления сервером будем использовать традиционную оснастку mmc для Windows "Администрирование серверов 1С:Предприятия", которую следует поставить из дистрибутива технологической платформы для Windows.
В этом месте на тестовом сервере возникли трудности - кластер по умолчанию отсутствовал, а при попытке создания нового кластера, ragent аварийно завершал работу с сообщением Sep 3 21:29:04 vh-1c83 kernel: ragent[1879]: segfault at 8 ip 00007f56473c9fd4 sp 00007f563b7b14a0 error 4 in rserver.so[7f56472db000+70e000]... странно, но если верить форумам, на CentOS у многих сервер 1С 8.3 ставится некорректно - не создаётся начальная конфигурация, включающая "Кластер по умолчанию". Краткий анализ ситуации выявил, что настройки кластера по умолчанию не были сгенерированы полностью и не попали в /home/usr1cv8/.1cv8/1C/1cv8/.
При попытке подложить файлы с рабочего сервера на неудачный, сервис 1С не запускается абсолютно без каких-либо диагностических сообщений - подобное поведение я видел при проблемах (неверных контекстах) SELinux, но в данном случае никаких отказов в audit.log не обнаружилось.
В результате детального изучения проблемы с применением strace удалось выяснить, что агент сервера при запуске ищет настройки по пути ~/.1cv8/1C/1cv8/ (в домашнем каталоге запустившего пользователя) и если не находит, пытается создать настройки кластера по умолчанию, для чего ему нужно имя хоста (выяснено экспериментально), и если верить "Руководству администратора", нужен корректно работающий DNS; экспериментально же был установлен факт, что сначала ragent читает файл /etc/hosts, затем обращается к DNS-серверу, а затем вызывает uname и снова лезет в hosts и к DNS и если не находит сопоставления, аварийно завершается. Итак, для нормального запуска потребуется полноценная и правильно настроенная сетевая инфраструктура, ну а в отсутствии работающего DNS достаточно дописать строчку в /etc/hosts и привести его примерно к такому виду:
127.0.0.1 localhost
192.168.122.227 vh-1c83.test.lan vh-1c83
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
За дальнейшими инструкциями пока отсылаю к своей статье про 8.2 - принципиальных отличий пока нет. Единственное замечание - при создании новой информационной базы, если указывать пользователя подключения к базе данных не с правами суперпользователя (а с набором прав из пункта 3), информационная база не создавалась, а в /var/lib/pgsql/9.2/data/pg_log/postgresql-Xxx.log наблюдались сообщения:
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: нет доступа к языку c
ОПЕРАТОР: CREATE OR REPLACE FUNCTION plpgsql_call_handler() RETURNS language_handler AS '$libdir/plpgsql' LANGUAGE C
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: ошибка синтаксиса (примерное положение: "application") в символе 24
ОПЕРАТОР: lock table pg_class in application share mode
ПРЕДУПРЕЖДЕНИЕ: нет незавершённой транзакции
ОШИБКА: тип "mvarchar" не существует в символе 31
ОПЕРАТОР: create table Config (FileName mvarchar(128) not null, Creation timestamp not null, Modified timestamp not null, Attributes int not null, DataSize int8 not null, BinaryData bytea not null, PartNo int not null, PRIMARY KEY (FileName, PartNo))
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: нет доступа к языку c
ОПЕРАТОР: CREATE OR REPLACE FUNCTION plpgsql_call_handler() RETURNS language_handler AS '$libdir/plpgsql' LANGUAGE C
После подключения с учётными данными суперпользователя БД, сообщения изменились на англоязычные и проблемы исчезли. Судя по всему, если на сервере установлен язык по умолчанию en_US, данного казуса не случится, но это - не проверенная информация, а лишь предположение, сделанное по прочтении чужой статьи про 8.1 и праздных раздумий =)
Ещё одна странность - если создать пустую SQL базу не из шаблона1 (см. официальную документацию по 1С), и попытаться ей указать на этапе создания ИБ, то всё равно получим сообщение "ОШИБКА: тип "mvarchar" не существует (символ 31)"/"ERROR: type "mvarchar" does not exist at character 31", но мне так и не удалось создать из требуемого шаблона БД - валились разные ошибки, но если пользователя sql, от которого создаётся ИБ временно повысить до суперпользователя с правом создания БД, и указать создание базы данных в случае её отсутствия, то всё получается в лучшем виде, так что на этапе первичной настройки, видимо, придётся повышать пользователя до супер...
Что порадовало - теперь в 1С можно работать непосредственно из Linux, что актуально для компаний, использующих его как основную ОС в корпоративной сети (я сейчас работаю как раз в такой компании); из неожиданностей - что при установке клиента 1С, он заявляет о зависимости от сервера и требует его установки, но потом ставится, прописывает значки запуска в "Офис" - "Финансы" и работает довольно сносно (по ощущениям - чуть менее комфортно, чем 8.2 под Windows, но заметно приятнее, чем тот же 8.2 через WINE от Ethersoft).
6. Установка недостающих зависимостей
При запуске клиента к настроенному по данной инструкции серверу, появится сообщение "На сервере отсутствуют шрифты из состава Microsoft Core Fonts. Внешний вид приложения может отличаться от ожидаемого. Процедура установки описана в справочной системе..." - данное сообщение появляется достаточно редко (периодичность не выявил, но появляется точно не единожды, но и не при каждом запуске), и на работе особо не сказывается, но "для красоты" я решил пройтись по всей цепочке и поставить рекомендуемые пакеты. Всё, кроме "corefonts" поставилось из репозиториев (хотя в той самой "справочной системе" безбожно перепутаны регистры в названиях пакетов, из-за чего их идентификация оказалась весьма развлекательна), ну а шрифты я решил пересобрать (в соответствии с рекомендациями из "справочной системы") и результат прикрепляю к статье - msttcorefonts-2.5-1.noarch.rpm, заодно и сами шрифты (уже переименованные в нижний регистр, как происходит при сборке rpm рекомендованным скриптом) - msttcorefonts.tar.gz - содержимое этого архива рекомендуют распаковать в /home/usr1cv8/.fonts (не забыв сменить владельца как на папку, так и на файлы!), если нет возможности установить предложенный .rpm
Кроме "ImageMagick" и шрифтов, для возможности сохранения в табличные файлы (кроме xls - его я пока не заставил формироваться, хотя xlsx формируется), на клиенте должны быть установлены пакеты "libMagickWand5", "libgomp1", "liblcms2-2" и "libbz2-1" - на ряде машин они отсутствовали. При чём той же разрядности, что и сервер 1С (см. п. 4).
7. Настройка аппаратного hasp для виртуализированного сервера 1С (работающего на виртуальной машине KVM)
Не планировал описывать эту процедуру, но раз уж столкнулся с такой ситуацией, опишу... Итак, на этот раз я использовал драйвер от "Alladin Knowledge Systems USB HASP", предоставляемый компанией Sentinel - мне попались две версии:
2878061 сен 11 2012 aksusbd-2.0-1.i386.rpm - с сайта aladdin-rd.ru
3009880 авг 6 16:35 aksusbd-2.2-1.i386.rpm - с сайта safenet-inc.com
Можно воспользоваться драйвером эзерсофт - окончательный выбор следует делать из опыта практической эксплуатации.
Наиболее правильная (на мой взгляд) последовательность действий:
а) убедиться, что на хост-машине драйвер HASP не установлен;
б) установить выбранный драйвер USB HASP4 на виртуальном сервере;
в) выяснить список подключенных USB-устройств к хост-машине
[root@vh01 files]# ls -R /dev/bus/usb
/dev/bus/usb:
001
002
003
004
/dev/bus/usb/001:
001
002
/dev/bus/usb/002:
001
/dev/bus/usb/003:
001
/dev/bus/usb/004:
001
[root@vh01 files]#
г) подключить USB-HASP к хост-машине и выяснить адрес ключа:
[root@vh01 files]# ls -R /dev/bus/usb
/dev/bus/usb:
001
002
003
004
/dev/bus/usb/001:
001
002
/dev/bus/usb/002:
001
/dev/bus/usb/003:
001
/dev/bus/usb/004:
001
002 <==== это наш ключ - раньше его не было
[root@vh01 files]#
д) используя любой из способов (я использовал Virtual Manager на удалённой машине) добавить "USB Host Device" с найденным адресом (в моём примере - 004:002) к виртуальной машине 1С - может потребоваться выключение и включение машины (я добавлял устройство на выключенную машину).
Собственно, всё - на CentOS 6.4 x64/i686 всё работает (были багрепорты про CentOS 6.0/6.1, но вроде всё починили). Если при запуске виртуалки выдаётся сообщение о занятости устройства, скорее всего подцепился драйвер на хост-машине (так писали на паре форумов, хотя мне эту ситуацию воспроизвести не получилось - даже с установленным драйвером на сервере устройство мапилось корректно). Естественно, если переставить ключ в другой порт USB, придётся перенацеливать и виртуальную машину!
И напоследок, коротко о том "что где лежит":
/etc/sysconfig/srv1cv83 - файл конфигурации сервера 1С
/home/usr1cv8/.1cv8/1C/1cv8/1cv8wsrv.lst - файл, в котором хранятся основные свойства сервера - например, учётные данные администратора сервера, зарегистрированые кластеры и т.п.
/home/usr1cv8/.1cv8/1C/1cv8/reg_1541/1CV8Clst.lst - файл, в котором хранятся свойства кластера по умолчанию
/opt/1C/v8.3/x86_64/ - (вместо "x86_64" может быть "i386" - в зависимости от архитектуры системы) исполняемые файлы и сопутствующие ресурсы сервера (и клиента) 1С
/var/1C/licenses - здесь лежат файлы электронных ключей лицензий
8. Настройка локального репозитория 1С для удобства обновления платформы
В процессе эксплуатации 1С нередко приходится обновлять платформу. Если всё установлено по приведённой выше инструкции, это вызывает определённые неудобства - надо останавливать сервис, удалять старые пакеты, ставить новые... не знаю - мне это ещё в винде надоело смертельно. Linux предлагает очень удобный механизм пакетного обновления из локального репозитория - всё, что нужно - это выбрать место, где будут лежать обновки: для одиночного сервера, к которому все ходят только через web-интерфейс, это может быть /root/repo (всё равно обновление под рутом идёт), ну а в общем случае - хоть /var/www/1c-repo - главное, чтобы все, кому он нужен, его видели. Далее надо установить пакет 'createrepo' (yum install createrepo) - за собой он притащит немало зависимостей, но не смертельно. Теперь командой 'createrepo /root/repo' (где "/root/repo" - выбранный путь хранения репозитория) создаём его "описание" и можно пользоваться.
Затем создаём файл описания нашего репозитория и помещаем его в каталог описаний репозиториев (для CentOS это /etc/yum.repos.d). Пример конфига локального файлового репозитария:
[root@1c yum.repos.d]# cat local-1c.repo
[local-1c]
name=1C Enterprise
#baseurl=http://inhost.firm.lan/repo
baseurl=file:///root/repo
gpgcheck=0
enabled=1
По-моему, разъяснять что за что отвечает, особого смысла нет. Единственное, что важно - сразу yum его может не увидеть - в этой ситуации поможет
Всё. Теперь если надо обновиться, то помещаем новые файлы дистрибутива 1С рядом со старыми, повторяем 'createrepo /root/repo' вызываем 'yum update' - и всё - платформа пошла обновляться! Естественно, за сохранностью и защищённостью своего репозитория надо следить, так как GPG у нас выключен, и это всё же дыра в безопасности, хоть и не особо толстая...
Google maps : вывод точек на карту и режим панорамы В отличие от яндекс карт в GMaps можно использовать панорамы - за что им большой плюс! Надеюсь в яндексе прочитают этот пост и тоже когда-нибудь это сделают!
Для клиента нужно было сделать вывод объектов на карту
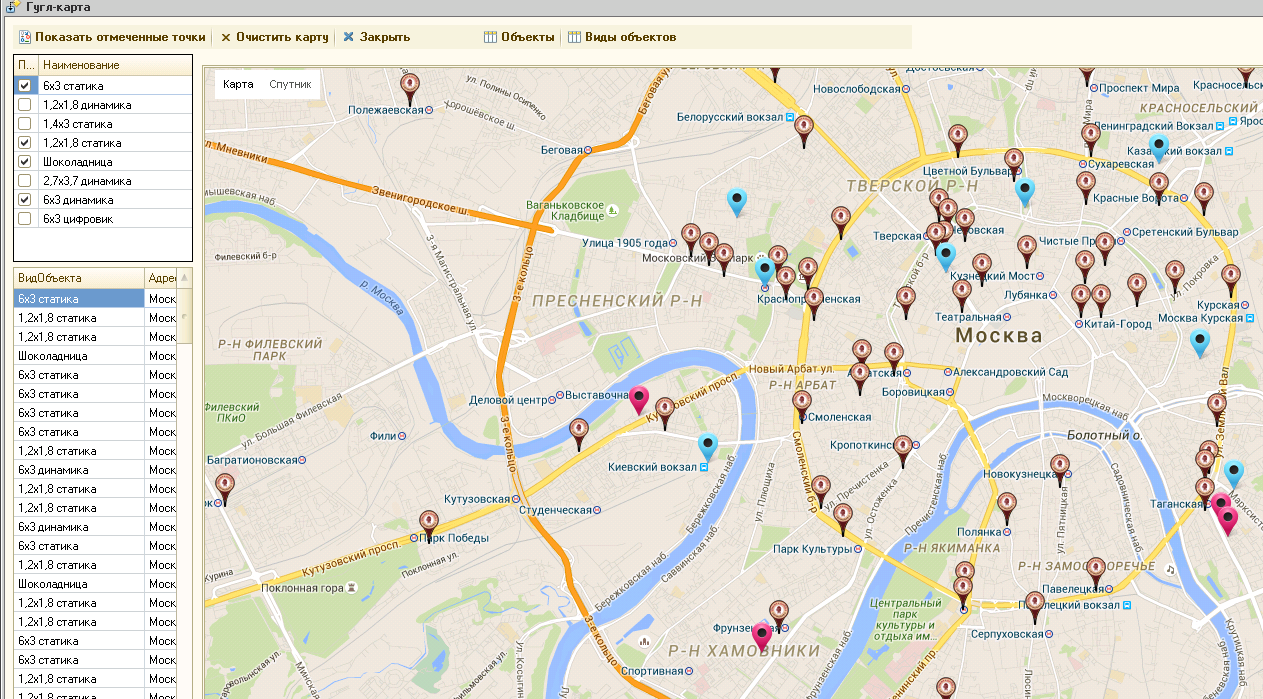
С возможностью просмотра панорамы:

Основной HTML код карты хранится в макете:
Код вывода карты:
Вырванная из конфигурации обработка GMaps.rar
Можно ее использовать как макет для создания обработки под свои требования.
Невозможно применить фиксированные настройки. Пересекаются элементы отбора. В некоторых релизах конфигураций на управляемом приложении на платформе 1С: Предприятие 8.3 можно получить следующую ошибку:

Текст по кнопочке “Подробно”:
Параметры Отбора, Сортировки, Группировки или список отображаемых полей заданы неверно. по причине: Невозможно применить фиксированные настройки. Пересекаются элементы отбора.
Воспроизведение ошибки
Ошибка появляется если в какой либо форме списка или выборка указать отбор, а после форму закрыть. При следующем открытии формы получим сообщение об ошибке.
Причина
Причина в использовании новой технологии в еще не подготовленной конфигурации, а именно свойство динамического списка “АвтоматическоеСохранениеПользовательскихНастроек”.
Два варианта решения данной проблемы:
1. Необходимо очистить сохраненные настройки пользователя. Пример для УТ 11.1: Переходим в меню “Администрирование – Настройки пользователей и прав – Очистка настроек” в появившейся форме выбираем пользователя(ей) и чистим. Такой вариант даст разовый результат, если пользователь снова поставит отбор, то получим такую же ошибку.
2. В форме списка или выбора элемента необходимо зайти в свойства динамического списка и свойству “АвтоматическоеСохранениеПользовательскихНастроек” установить значение “Ложь”.

Такой вариант решения можно считать временным, до момента обновления на релиз конфигурации с исправленной ошибкой.
Табличная часть ~ Как настроить отбор строк? Часто возникает задача показать только нужные строки в табличной части документа или справочника (или другого объекта). Для этого можно использовать замечательное свойство:
в обычном приложении параметр для ОтборСтрок - Отбор...
в управляемом приложении - ФиксированнаяСтруктура
ОтборСтрок, которое входит в расширение табличного поля, связанного с табличной частью.
пример:
или такой динамический отбор
Использовать его очень просто:
или 2-й вариант:
А теперь конкретные примеры:
Подчиненные табличные части в 8.х
С помощью свойства ОтборСтрок можно реализовать подчиненные (связанные) табличные части. При смене текущей строки в первой табличной части вторая табличная часть показывает только связанную информаци. Например, таким образом можно реализовать работу с комплектами: 1-я таб. часть - комплекты, вторая - состав комплекта.
Во второй табличной части должна быть колонка - идентификационный признак, связывающий ее с первой табличной частью. Таких колонок может быть несколько (составной ключ);
В событии ПриАктивизацииСтроки для первого табличного поля пишем:
При добавлении новой строки во вторую табличную часть, нужно следить за тем, чтобы идентификационная колонка была установлена.
Обращаю ваше внимание, что при таком отборе не используются индексы и для больших табличных частей возможно замедление работы.
Еще раз напомню, что ОтборСтрок входит в расширение табличного поля табличной части, т.е. табличное поле должно быть связано с табличной частью. Если же оно связано с динамическим списком типа СправочникСписок, то здесь нужно использовать свойство Отбор для объекта типа СправочникСписок.
Если понадобилось перебрать строки, вошедшие в отбор, то это можно сделать, только заново перебрав все строки и проверив условие отбора для каждой строки. Перебрать строки табличного поля, которые сейчас на экране - невозможно.
Подробный пример заполнения Диаграммы данными (создание, Пример создания, очистки и обновления Диаграммы График
Регламентные операции на уровне субд для MS SQL Server, Оптимизация работы Одной из часто встречающихся причин не оптимальной работы системы является неправильное или несвоевременное выполнение регламентных операций на уровне СУБД. Особенно важно выполнять эти регламентные процедуры в крупных информационных системах, которые работают под значительной нагрузкой и обслуживают одновременно большое количество пользователей. Специфика таких систем в том, что обычных действий, выполняемых СУБД автоматически (на основании настроек) оказывает недостаточно для эффективной работы.
 Если в работающей системе наблюдаются какие-либо симптомы проблем с производительностью, следует проверить, что в системе правильно настроены и регулярно выполняются все рекомендуемые регламентные операции на уровне СУБД.
Если в работающей системе наблюдаются какие-либо симптомы проблем с производительностью, следует проверить, что в системе правильно настроены и регулярно выполняются все рекомендуемые регламентные операции на уровне СУБД.
Выполнение регламентных процедур должно быть автоматизировано. Для автоматизации этих операций рекомендуется использовать встроенное средства MS SQL Server: Maintenance Plan. Существуют так же другие способы автоматизации выполнения этих процедур. В настоящей статье для каждой регламентной процедуры дан пример ее настройки при помощи Maintenance Plan для MS SQL Server 2005.
Для MS SQL Server рекомендуется выполнять следующие регламентные операции:
Обновление статистикОчистка процедурного КЭШаДефрагментация индексовРеиндексация таблиц базы данныхРекомендуется регулярно контролировать своевременность и правильность выполнения данных регламентных процедур.
MS SQL Server строит план запроса на основании статистической информации о распределении значений в индексах и таблицах. Статистическая информация собирается на основании части (образца) данных и автоматически обновляется при изменении этих данных. Иногда этого оказывается недостаточно для того, что MS SQL Server стабильно строил наиболее оптимальный план выполнения всех запросов.
В этом случае возможно проявление проблем с производительностью запросов. При этом в планах запросов наблюдаются характерные признаки неоптимальной работы (неоптимальные операции).
Для того, чтобы гарантировать максимально правильную работу оптимизатора MS SQL Server рекомендуется регулярно обновлять статистики базы данных MS SQL.
Для обновления статистик по всем таблицам базы данных необходимо выполнить следующий SQL запрос:
Обновление статистик не приводит к блокировке таблиц, и не будет мешать работе других пользователей. Статистика может обновляться настолько часто, насколько это необходимо. Следует учитывать, что нагрузка на сервер СУБД во время обновления статистик возрастет, что может негативно сказаться на общей производительности системы.
Оптимальная частота обновления статистик зависит от величины и характера нагрузки на систему и определяется экспериментальным путем. Рекомендуется обновлять статистики не реже одного раза в день.
Приведенный выше запрос обновляет статистики для всех таблиц базы данных. В реально работающей системе разные таблицы требуют различной частоты обновления статистик. Путем анализа планов запроса можно установить, какие таблицы больше других нуждаются в частом обновлении статистик, и настроить две (или более) различных регламентных процедуры: для часто обновляемых таблиц и для всех остальных таблиц. Такой подход позволит существенно снизить время обновления статистик и влияние процесса обновления статистики на работу системы в целом.
Настройка автоматического обновления статистик (MS SQL 2005)
Запустите MS SQL Server Management Studio и подключитесь к серверу СУБД. Откройте папку Management и создайте новый план обслуживания:
 Создайте субплан (Add Sublan) и назовите его «Обновление статистик». Добавьте в него задачу Update Statistics Task из панели задач:
Создайте субплан (Add Sublan) и назовите его «Обновление статистик». Добавьте в него задачу Update Statistics Task из панели задач:

Настройте расписание обновления статистик. Рекомендуется обновлять статистики не реже одного раза в день. При необходимости частота обновления статистик может быть увеличена.
Настройте параметры задачи. Для этого следует два раза кликнуть на задачу в правом нижнем углу окна. В появившейся форме укажите имя базу данных (или несколько баз данных) для которых будет выполняться обновление статистик. Кроме этого вы можете указать для каких таблиц обновлять статистики (если точно неизвестно, какие таблицы требуется указать, то устанавливайте значение All).
Обновление статистик необходимо проводить с включенной опцией Full Scan.

Сохраните созданный план. При наступлении указанного в расписании срока обновление статистик будет запущено автоматически.
Оптимизатор MS SQL Server кэширует планы запросов для их повторного выполнения. Это делается для того, чтобы экономить время, затрачиваемое на компиляцию запроса в том случае, если такой же запрос уже выполнялся и его план известен.
Возможна ситуация, при которой MS SQL Server, ориентируясь на устаревшую статистическую информацию, построит неоптимальный план запроса. Этот план будет сохранен в процедурном КЭШе и использован при повторном вызове такого же запроса. Если Вы обновили статистику, но не очистили процедурный кэш, то SQL Server может выбрать старый (неоптимальный) план запроса из КЭШа вместо того, чтобы построить новый (более оптимальный) план.
Таким образом, рекомендуется всегда после обновления статистик очищать содержимое процедурного КЭШа.
Для очистки процедурного КЭШа MS SQL Server необходимо выполнить следующий SQL запрос:
Этот запрос следует выполнять непосредственно после обновления статистики. Соответственно, частота его выполнения должна совпадать с частотой обновления статистики.
Настройка очистки процедурного КЭШа
для (MS SQL 2005)
Поскольку процедурный КЭШ необходимо очищать при каждом обновлении статистики, данную операцию рекомендуется добавить в уже созданный субплан «Обновление статистик». Для этого следует открыть субплан и добавить в его схему задачу Execute T-SQL Statement Task. Затем следует соединить задачу Update Statistics Task стрелочкой с новой задачей.

В тексте созданной задачи Execute T-SQL Statement Task следует указать запрос «DBCC FREEPROCCACHE»:

При интенсивной работе с таблицами базы данных возникает эффект фрагментации индексов, который может привести к снижению эффективности работы запросов.
Рекомендуется регулярное выполнение дефрагментации индексов. Для дефрагментации всех индексов всех таблиц базы данных необходимо использовать следующий SQL запрос (предварительно подставив имя базы):
Дефрагментация индексов не блокирует таблицы, и не будет мешать работе других пользователей, однако создает дополнительную нагрузку на SQL Server. Оптимальная частота выполнения данной регламентной процедуры должна подбираться в соответствии с нагрузкой на систему и эффектом, получаемым от дефрагментации. Рекомендуется выполнять дефрагментацию индексов не реже одного раза в день.
Возможно выполнение дефрагментации для одной или нескольких таблиц, а не для всех таблиц базы данных.
Настройка дефрагментации индексов (MS SQL 2005)
В ранее созданном плане обслуживания создайте новый субплан с именем «Дефрагментация индексов». Добавьте в него задачу Reorganize Index Task:

Задайте расписание выполнения для задачи дефрагментации индексов. Рекомендуется выполнять задачу не реже одного раза в неделю, а при высокой изменчивости данных в базе еще чаще – до одного раза в день.
Настройте задачу, указав базу данных (или несколько баз данных) и выбрав необходимые таблицы. Если точно неизвестно, какие таблицы следует указать, то устанавливайте значение All.

Реиндексация таблиц включает полное перестроение индексов таблиц базы данных, что приводит к существенной оптимизации их работы. Рекомендуется выполнять регулярную переиндексацию таблиц базы данных. Для реиндексации всех таблиц базы данных необходимо выполнить следующий SQL запрос:
Реиндексация таблиц блокирует их на все время своей работы, что может существенно сказаться на работе пользователей. В связи с этим реиндексацию рекомендуется выполнять во время минимальной загрузки системы.
После выполнения реиндексации нет необходимости делать дефрагментацию индексов.
В ранее созданном плане обслуживания создайте новый субплан с именем «Дефрагментация индексов». Добавьте в него задачу Rebuild Index Task:

Задайте расписание выполнения для задачи реиндексирования таблиц. Рекомендуется выполнять задачу во время минимальной нагрузки на систему, не реже одного раза в неделю.
Настройте задачу, указав базу данных (или несколько баз данных) и выбрав необходимые таблицы. Если точно неизвестно, какие таблицы следует указать, то устанавливайте значение All.

Необходимо осуществлять регулярный контроль выполнения регламентных процедур на уровне СУБД. Ниже приведен пример контроля выполнения плана обслуживания для MS SQL Server 2005.
Откройте созданный вами план обслуживания и выберите из контекстного меню пункт «View History»:

Откроется окно с протоколом выполнения всех заданных регламентных процедур.

Успешно выполненные задачи и задачи, выполненные с ошибками, будут помечены соответствующими иконками. Для задач, выполненных с ошибками, доступна подробная информация об ошибке.
Источник: Регламентные операции MS SQL Server. Оптимизация работы
Яндекс, Google, Рамблер Карты и 1С  Удаление регистрации изменений для узла Категория: Конвертация данных, Обмен, Перенос Как очистить кэш 1С?
Удаление регистрации изменений для узла Категория: Конвертация данных, Обмен, Перенос Как очистить кэш 1С?  Выгрузка в PDF из 1С (Средствами OpenOffice) Как удалить записи независимого регистра сведений с отбором по конкретной организации? Ошибка формата потока 1С
Выгрузка в PDF из 1С (Средствами OpenOffice) Как удалить записи независимого регистра сведений с отбором по конкретной организации? Ошибка формата потока 1С .gif) Ошибка "Нарушена целостность структуры конфигурации"
Ошибка "Нарушена целостность структуры конфигурации" 
 Перемещение базы данных TEMPDB
Перемещение базы данных TEMPDB