Иногда возникает необходимость обработать фотографии в 1С автоматически, уменьшить вес картинок в килобайтах, за счет удаления из файла не нужной технической информации и сглаживания цветов, или изменить размер, уменьшить картинку пропорционально задав максимальный размер по ширине или высоте.В этом случае можно:1) установить специальные библиотеки в операционной системе для работы с графикой, н-р GFLAx и подключать их как com-объекты2) использовать api сервисов, таких как optipic.io.
Рассмотрим оба варианта:1) Использование GFLAxСкачиваем и устанавливаем библиотеку GFLAx, скачать можно здесь https://www.xnview.com/en/#downloads
Далее её надо зарегистрировать в Windows. Для этого запускаем CMD.exe с правами администратора и набираем: regsrv32 "путь_к_DLL\GFLAx.dll"Далее уже в программе, для пропорционального изменения размера файла до максимального размера в 500 пикселей можно вставить такой код:
Данный способ требует специальных настроек операционной системы, навыков системного администрирования и данный способ не проводит полноценную оптимизацию картинки.Кроме того, на компьютере или сервере, где производиться оптимизация эта библиотека должна быть установлена.2) Использование сервиса optipic.ioПодобные сервисы обычно платные, но стоимость использования не высокая, а качество и гибкость существенно выше.
Преимущества использования сервиса optipic.io в проектах 1С:
Легко подключить
Не нужно устанавливать дополнительные библиотеки в операционной системе
Можно использовать как для оптимизации изображений, так и для изменения размера изображения в пикселях (ресайз)
Не зависит от операционной системы и типа используемого клиента
Конфигурация будет работать после переезда на другой компьютер или сервер
Качество и эффективность сжатия производятся в самом оптимальном виде
Использование сервиса можно легко встроить в любой свой проект на 1С. Для этого можно добавить себе функцию, в которую передавать имя файла с исходной картинкой и параметры оптимизации. А в качестве ответа получить имя файла уже оптимизированного сервисом.
Пример такой функции для 1C8:
И далее в коде обращаться к данной функции, н-р так
Для примера , у меня будет цикл по запросу, который отправляет заранее заданный текст из справочника, клиентам.
В нем у нас есть 2 объекта.
1) HTTP соединения
2) HTTP Запрос
В запрос кидаем сформированную строку, в которой есть
1) API ключ - записан в константы
2) Текст, из справочника (с заменой)
3) номер телефона из заказа (у кого откуда )
4) конец строки JSON= 1 , означает получение ответа от сайта , о успешной или не успешной отправке смс с кодами авторизации/отправки в формате JSON (Разбор JSON отдельная тема)
В запросе, указываем адрес который идет после sms.ru, начиная со слэша!
В соединении, если httpS , не указываем изначально , какой это протокол, указать порт и создать объект защищенного соединения.
Очень часто менеджеры дублируют информацию в справочниках и время от времени их приходится чистить.
Но как удалить только те элементы справочника, которые не используются в документах?
Следующий пример кода поможет это сделать(в примере обрабатывается 4 справочника: Сотрудники, ФизЛица, Договора и Контрагенты) Скачать: Обработка для УТ 10:
Мне частенько приходится взаимодействовать с 1С-разработчиками, и во время совместной работы над проектами замечаю, что далеко не все из них хорошо знают свой главный инструмент – «Конфигуратор». Причем это не относится к степени крутости девелопера. Как оказалось, даже синьоры пользуются далеко не всеми возможностями «Конфигуратора», а ведь они могут сэкономить кучу времени, а тем самым повысить продуктивность разработчика.
Под катом я решил собрать несколько полезных фишек стандартного конфигуратора, которыми пользуюсь регулярно. Многие из них появились в платформе «1С:Предприятие 8.3.х», поэтому перед тестированием обязательно проверьте номер версии установленной у вас платформы.
Закладки
Функция установки в коде закладок появилось еще с первых релизов 8-й версии платформы «1С:Предприятие». Штука чрезвычайно полезная и помогает разработчику быстрей передвигаться по коду. Например, у нас есть большой модуль, в который мы решили добавить ряд функций. Естественно, потом нам предстоит их отлаживать, а соответственно постоянно между ними переключаться.
Хорошо, если новые функции добавлены в самый конец модуля, а если потребовалось расположить в разных частях? Вот тут начинается самое интересное. Одни программисты начинают скролить текст (как правило, этим страдают новички). Более продвинутые применяют поиск по тексту (Ctrl + F).
Оба способа рабочие, но пользоваться ими долго. Куда правильней использовать функцию «закладки». Например, переходим к какой-нибудь строке. Нажимаем ALT + F2 и получаем закладку (слева от строки отобразиться квадратик).
Убирается закладка тем же сочетанием клавиш. Так вот, закладок может быть в модуле расставлено много. По ним легко передвигаться нажатием клавиши F2. Фича крутая, но она была изначально не доделана и не позволяла, например, передвигаться по закладкам в разных модулях. Это досадное ограничение создавало лишние тормоза для программистов, привыкших к хорошим IDE (например, Visual Studio, PHP Storm).
В версии 8.3 недочет исправили и сделали классную вещь – «Список закладок». Нажимаем клавиши «Ctrl + Shift + F2», и перед нами откроется окно с полным списком установленных закладок:
В нем перечислены все закладки в разрезе модулей. Для каждой закладки указан номер строк и доступен перечень действий: перейти к коду, удалить закладку, удалить все закладки.
Таким образом, работать с закладками стало на порядок проще. Еще бы добавили возможность установки горячих клавиш на закладки, и стало бы совсем хорошо. Помню еще со времен «Delphi 6» привык к установке закладок по горячим клавишам Alt + <Цифра>. Наставил закладок и быстро перемещайся по ним.
Группировка строк
В «1С:Предприятие» с самого начала была одна большая проблема – отсутствие возможности создавать дополнительные модули для определенных объектов. Например, есть у меня справочник «Контрагенты» и мне хочется разделить его функционал на модули. Допустим, функционала очеееень много. Так вот, в моем распоряжении все равно стандартный набор: Модуль объекта, Модуль менеджера и модуль формы. Понятное дело, что у каждого модуля своя роль, но что делать мне с моими 100500 функциями, которые относятся непосредственно к справочнику «Контрагенты»?
По мнению 1С я должен оформить их в виде общего модуля. С одной стороны, идея классная. Делаем модуль, его сразу видно и т.д., и т.п. Правда всегда есть один нюанс. Если следователь этой методике, то при наличии кучу объектов в конфигурации число общих модулей будет зашкаливать.
Вот взять хотя бы библиотеку БСП. Стоит ее внедрить и в количестве модулей начинает теряться. Я уже молчу про конфигурации, которые построены на базе БСП. Там и сто пятьсот модулей от БСП, и еще столько же специально для конфигурации.
В общем, неудобство налицо (особенно после опыта разработки в языках, где нет подобных ограничений). Увы, спастись от этой проблемы в настоящее время не получится. Зато, мы можем использовать возможности группировки функций/процедур в модулях.+
Например, есть у нас общий модуль «РаботаСКонтрагентами». В нем часть функций отвечают за поиск контрагента, другая часть за загрузку контрагентов из внешних источников и т.д. Чтобы не потеряться во всем этом многообразии возможностей, можно логически сгруппировать все функции/процедуру. Для этого в платформе 8.3 появилась функция под названием «Области». Рассмотрим пример:
После добавление областей (язык препроцессора) наш код будет сгруппирован. Если их свернуть (области), то в итоге мы увидим симпатичный комментарий (см. рисунок ниже):
Клик мышкой по плюсику развернет область, и мы увидим свернутые функции. Если хочется сразу развернуть все имеющиеся функции (в пределах области), то кликаем по плюсику удерживая Ctrl.
Вот такая мега удобная вещь и в модулях с большим количеством функций спасает очень даже. В предыдущих версиях платформы было модно использовать для подобных целей блоки комментариев, но управлять/добавлять областями явно удобней.
Форматирование кода
Собственно говоря, тут и рассказывать особо нечего – выделяем код, нажимаем «Alt + Shift + F» и редактор попытается привести его в божеский вид в соответствии с вшитым code-style. Функция работает вполне сносно и ей обязательно надо пользоваться. Пишу это потому, что неоднократно видел, как разработчики пытаются отбивать отступы самостоятельно. Это конечно круто, но зачем тратить время, если большую часть работы можно выполнить одной горячей клавишей?
Комментирование
Опять же, никаких секретных действий – выделили код, нажали “Ctrl + num /” (слеш на дополнительной области клавиатуры) и получили закомментированный участок. Захотели вернуть обратно? Не беда! Выделяем закомментированный участок кода, нажимаем «Ctrl + Shift + num /» и мгновенно приводим его в боевой режим. Фишка попсовая, но опять же, новички про нее не знают, и тратят кучу времени на расстановку слешей. Да еще и матерят компанию «1С», за отсутствие возможности многострочного комментирования, как в продвинутых язык программирования.
Быстрая вставка специальных символов
Иногда возникает необходимость быстро вставить в редактор специальный символ (которого нет на клавиатуре). В большинстве случаев разработчики используют для этого функции встроенного языка (например, символ). А ведь есть способ проще. Если удерживать клавишу Alt и набрать на доп. клавиатуре код нужного символа (из таблицы ASKII), то он тут же будет вставлен. Например, держим ALT и набираем 65. На выходе получаем букву «А». Или вводим 4 и получаем бубновую масть.
Вставка специальных символов
Хорошо, с этим понятно, но какой от этого еще можно получить профит? Лично я, таким образом вставляю символ амперсанда (&). Все знают, что этот символ используется для определения параметров в языке запросов. Неудобство состоит в том, что текст запроса мы пишем на русском языке, а для добавления этого символа перед параметром приходится переключить на английский, затем нажать Shift + 7, а потом вернуться обратно на русский.
Чтобы избавить себя от этой рутиной последовательности действий, я использую выше озвученную функцию. С ее помощью для установки амперсанда требуется лишь набрать с удержанной клавишей «alt» последовательность цифр 38. При этом надобность в двойном переключении языка отпадает.
Многие могут подумать, что я искусственно раздул проблему из ничего, но тут просто дело привычки. Кода приходится писать много и вот такие мелочи немного повышают производительность и избавляют от лишних нажатий клавиши backspace (для удаления случайно набранных символов). Не убедил? Тогда просто выделите время и попробуйте себя переучить
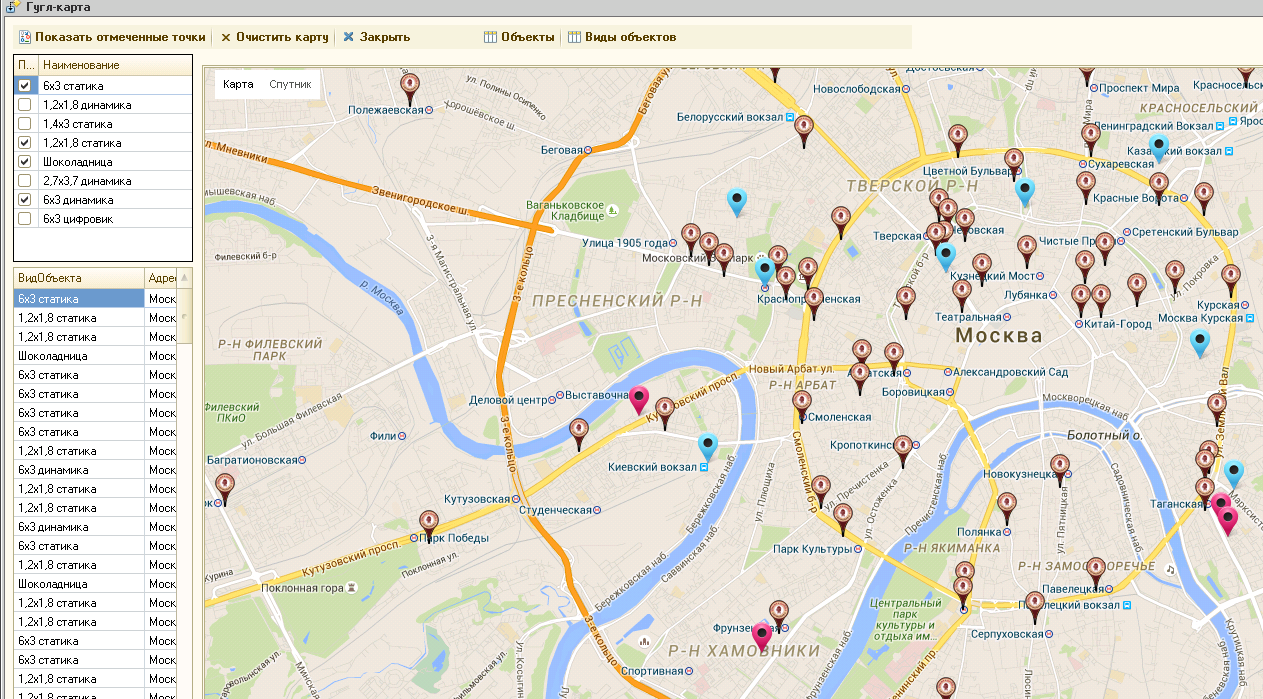
В отличие от яндекс карт в GMaps можно использовать панорамы - за что им большой плюс! Надеюсь в яндексе прочитают этот пост и тоже когда-нибудь это сделают!
Для клиента нужно было сделать вывод объектов на карту
Порядок расчета фиксированных страховых взносов за 2014 и 2015, 2016 год
Сумма взноса в ПФР = МРОТ * 12 * 26 %
Сумма взноса в ФОМС = МРОТ * 12 * 5.1 %
где МРОТ (Минимальный Размер Оплаты Труда):
5554 рублей в 2014 году
5965 рублей в 2015 году
6204 рублей в 2016 году
Таким образом, суммы страховых взносов равны:
За 2016 год - 23 153,33 руб.
За 2015 год - 22 261,38 руб.
За 2014 год - 20 727,53 руб.
Также, начиная с 2014 года при получении более 300 000 рублей дохода за год, ИП обязан оплатить 1% в ПФР от суммы, превышающей 300000р. Например, при получении дохода 400 000 рублей, 1% нужно заплатить с суммы 400 000 - 300 000 = 100 000 руб., получаем 1 000 руб.
НО Законодательно предусмотрено ограничение суммы страховых взносов в ПФР. Страховые взносы не могут превышать произведение восьмикратного МРОТ на начало года и тарифа ПФР, увеличенное в 12 раз. То есть, на 2014 год максимальный размер взносов в ПФР составляет 138 627,84 руб. (5554 х 8 х 26% х 12).
Расчет страховых взносов за неполный год
При уплате страхового взноса за неполный год (при начале предпринимательской деятельности не с начала года либо при прекращении деятельности) размер взноса соответственно уменьшается пропорционально календарным дням. Формула для расчета:
МРОТ × М × Тариф + МРОТ × Д/П × Тариф
М & количество полных месяцев деятельности ИП в отчетном году;
Д & количество дней в неполном месяце (день регистрации / прекращения деятельности включать НУЖНО);
П & количество календарных дней в этом месяце;
В программе 1С для отражения уплаты и начисления за себя фиксированных взносов и доп. взносов никаких специальных настроек делать не нужно.
В плане счетов ИП для расчетов с бюджетом предусмотрены:
ПФР - специальный субсчет 69.06.5 «Обязательное пенсионное страхование предпринимателя»
ФОМС - субсчет 69.06.3 «Взносы в ФОМС».
Главное необходимо правильно заполнять документ "Списание с расчетного счета":
Фиксированные страховые взносы
его проводка:
И с доходов свыше 300 000 тыс. руб. Вид страховых взносов установите как: Страховые взносы, исчисленные с суммы дохода
Проводка будет такой:
Для ФОМС:
Проводка
При квартальной процедуре Закрытия месяца будет выполнена регламентная операция «Начисление страховых взносов ИП»
Закрытие месяца - Операция "Начисление страховых взносов ИП" отражает уплаченные в течение года страховые взносы в бухгалтерском и налоговом учете. Операция выполняется раз в год или раз в квартал в зависимости от применяемой системы налогообложения и наличия наемных работников. В случае применения общей системы налогообложения или упрощенной системы с объектом налогообложения «доходы, уменьшенные на величину расходов», сумма уплаченных страховых взносов отражается в налоговом учете в составе расходов.
Она создаст следующие проводки начисления страховых взносов ИП:
И главное помните: Фиксированные взносы нужно оплатить до 31 декабря, дополнительные(свыше 300т.р.) до 01 Апреля следующего года за отчетным!
Полнотекстовый поиск - позволит найти текстовую информацию, размещенную практически в любом месте используемой конфигурации. При этом искать нужные данные можно либо по всей конфигурации в целом, либо сузив область поиска до нескольких объектов (например, определенных видов документов или справочников). Сами критерии поиска могут варьироваться в довольно широком диапазоне. То есть найти нужные данные можно, даже не помня точно, где они хранятся в конфигурации и как именно записаны.
Полнотекстовый поиск предоставляет следующие возможности:
Есть поддержка транслитерации (написание русских слов символами латиницы в соответствии с ГОСТ 7.79-2000). Пример: "русская фраза" = "russkaya fraza".
Есть поддержка замещения (написание части символов в русских словах одноклавишными латинскими символами). Пример: "руссrfz фраpf" (окончания каждого слова набраны латиницей, допустим, в результате ошибки оператора).
Есть возможность нечеткого поиска (буквы в найденных словах могут отличаться) с указанием порога нечеткости. Пример: указав в строке поиска слово "привет" и нечеткость 17 %, найдем все аналогичные слова с ошибками и без: "привет", "превет", "привед".
Есть возможность указать область выполнения поиска по выбранным объектам метаданных.
Полнотекстовое индексирование названий стандартных полей ("Код", "Наименование" и т. д.) производится на всех языках конфигурации.
Поиск выполняется с учетом синонимов русского, английского и украинского языков.
Морфологический словарь русского языка содержит ряд специфических слов, относящихся к областям деятельности, автоматизируемым с помощью системы программ "1С:Предприятие".
Стандартно в состав поставляемых словарей включены словарные базы и словари тезауруса и синонимов русского, украинского и английского языков, которые предоставлены компанией "Информатик".
Поиск можно осуществлять с использованием подстановочных символов ("*"), а также с указанием поисковых операторов ("И", "ИЛИ", "НЕ", "РЯДОМ") и спецсимволов.
Полнотекстовый поиск можно осуществлять в любой конфигурации на платформе 1С:Предприятие 8
Для того чтобы открыть окно управления полнотекстовым поиском необходимо выполнить следующее:
Обычное приложение - пункт меню Операции - Управление полнотекстовым поиском.
Управляемое приложение - пункт меню Главное меню - Все функции - Стандартные - Управление полнотекстовым поиском.
Обновить индекс – Создание индекса/Обновление индекса;
Очистить индекс – обнуление индекса(рекомендуется после обновления всех данных);
пункт Разрешить слияние индексов – отвечает за слияние основного и дополнительного индекса.
Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.
Как вы можете заметить свойство Использовать установлено для всего справочника Контрагенты, но сделать это можно и для каждого его реквизита соответствующего типа.
Рассмотрим более подробно полнотекстовый индекс, который состоит из двух частей (индексов): основного индекса и дополнительного. Высокая скорость поиска данных обеспечивается за счет основного индекса, но обновление его происходит относительно медленно, в зависимости от объема данных. Дополнительный индекс ему противоположен. Данные добавляются в него намного быстрее, но поиск осуществляется медленнее. Система осуществляет поиск одновременно в обоих индексах. Большая часть данных находится в основном индексе, а данные добавляемые в систему попадают в дополнительный индекс. Пока объем данных в дополнительном индексе небольшой, поиск по нему происходит относительно быстро. В тот момент, когда нагрузка на систему невелика, происходит операция слияния индексов, в результате чего дополнительный индекс очищается, а все данные помещаются в основной индекс. Слияние индексов предпочтительнее выполнять в тот момент времени, когда нагрузка на систему минимальна. С этой целью можно создавать регламентированные задания и задания по расписанию.
Специальные операторы, допустимые при задании поискового выражения
Механизм полнотекстового поиска допускает написание части символов русского слова одноклавишными латинскими символами. Результат поиска при этом не измениться.
Два оператора РЯДОМ
упрощенный. На расстоянии 8 слов друг от друга
РЯДОМ/[+/-]n – поиск данных в одном реквизите на расстоянии n-1 слов между ними.
Знак указывает в каком направлении от первого слова будет поиск второго. (+ - после, - до)
Групповой символ «*» может использоваться только в качестве замены конца слова
Оператор нечеткости «#». Если неизвестно точное написание названия, имени.
Программными средствами и средствами 1с: программирование.
Оператор синонимов «!». Позволяет найти слово и его синонимы
Как программно обновить индекс полнотекстового поиска?
Пример полнотекстового поиска данных
Определение переменной СписокПоиска
Кроме этого в процедуре обработки события ПриОткрыии формы определим, что эта переменная будет содержать список полнотекстового поиска, с помощью которого мы и будем осуществлять поиск в данных
Теперь для события нажатия на кнопку Найти напишем код, который позволит нам выполнять поиск в соответствии с тем выражением, которое задано в поле ПоисковоеВыражение
Сначала в этой процедуре мы устанавливаем поисковое выражение, введенное пользователем, в качестве строки поиска для полнотекстового поиска. Затем выполняем метод ПерваяЧасть(), который собственно запускает полнотекстовый поиск и возвращает первую порцию результатов. По умолчанию порция содержит 20 элементов. После этого мы анализируем количество элементов в списке поиска. Если он не содержит ни одного элемента, то мы выводим в форму соответствующее сообщение. В противном случае вызывается процедура ВывестиРезультатПоиска(), которая отображает полученные результаты пользователю.
Создадим в модуле формы процедуру с таким именем и напишем в ней код,
Действия, выполняемые в этой процедуре, просты. Сначала мы формируем сообщение о том, какие элементы отображены и сколько всего элементов найдено. Затем получаем результат полнотекстового поиска в виде HTML-текста и выводим этот текст в поле HTML-документа, расположенное в форме.
В заключение передаем управление в процедуру ДоступностьКнопок() для того, чтобы сделать доступными или, наоборот, запретить доступ к кнопкам Предыдущая порция и Следующая порция (в зависимости от того, какая порция полученных результатов отображена). Текст этой процедуры представлен в Коде
Теперь необходимо создать обработчики событий нажатия на кнопки ПредыдущаяПорция() и СледующаяПорция().
Заключительным «штрихом» будет создание обработчика события onclick поля HTML-документа, расположенного в форме. Дело в том, что результат полнотекстового поиска, представленный в виде HTML-текста, содержит гиперссылки на номера элементов списка поиска. И нам хотелось бы, чтобы при переходе пользователя на эту ссылку система открывала бы форму того объекта, который содержится в этом элементе списка. Для этого мы будем перехватывать событие onclick HTML-документа, содержащегося в поле HTML-документа, получать номер элемента списка из гиперссылки и открывать форму соответствующего объекта. Текст обработчика события onclick поля HTML-документа представлен в коде
Обратился ко мне старый клиент и говорит - беда с нумерацией счетов!
Менеджеры, кто как хотел - так и изменял номера документов. с префиксом, без, писали даже б/н. Но тут пришел новый бухгалтер и сказал - нужно с 1 октября запустить авто нумерацию с номера 00010000, но старые счета не трогать!
Попросили - сделали:
т.к. Старые трогать нельзя - простое восстановление нумерации отпадает
Первое решение, которое пришло в голову, сделать выборку по моментувремени создания счета - обратная сортировка - получить первый - и к полученному номеру документа +1
Но оказалось, что бывает такое: менеджеры создают счета сегодня, но ставят дату вчера - и получается только что созданный документ уже не последний пришлось переделать алгоритм.
Только алгоритм решили немного переделать - не получаем дату создания документа, а сортируем по части ГУИДа, которая является началом периода создания документа.
Для управления регистрацией документа в последовательности документов служит набор записей регистрации в последовательности документов.
У документа есть свойство ПринадлежностьПоследовательностям. Значением свойства является коллекция наборов записей регистрации в последовательности документов. Для каждой последовательности, в которой участвует документ, существует свой собственный экземпляр набора записей. Если у документа стоит режим автоматического заполнения последовательностей, то перед записью документа наборы записей регистрации будут автоматически заполнены. Для последовательностей без измерений набор записей будет содержать только одну запись. Для последовательностей с измерениями число записей зависит от содержания документа и настройки соответствия измерений последовательности реквизитам документа.
Набор записей автоматически заполняется до записи документа и записывается после записи документа в одной транзакции с ним. Это позволяет в обработчиках событий документа ПередЗаписью() и ПриЗаписи() переопределить набор записей регистрации. Так, например, если документ входит в последовательность Последовательность1 и у документа стоит признак автоматического заполнения последовательности, то для того что бы отменить его регистрацию в последовательности в зависимости от значения реквизита документа достаточно в модуль документа вставить обработчик события ПередЗаписью() следующего содержания:
В этом случае если реквизит Регистрировать имеет значение "Ложь", то документ не будет зарегистрирован в последовательности Последовательность1. Кроме отмены регистрации документа в последовательности, доступна возможность написания собственного алгоритма регистрации документа в последовательности. Для этого надо очистить набор записей регистрации и заполнить его новыми записями.
 Отправка и получение почты с использованием технологии шифрования SSL
Отправка и получение почты с использованием технологии шифрования SSL 








 - Да
- Да - Да
- Да









 Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.
Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.
 Менеджеры, кто как хотел - так и изменял номера документов. с префиксом, без, писали даже б/н. Но тут пришел новый бухгалтер и сказал - нужно с 1 октября запустить авто нумерацию с номера 00010000, но старые счета не трогать!
Менеджеры, кто как хотел - так и изменял номера документов. с префиксом, без, писали даже б/н. Но тут пришел новый бухгалтер и сказал - нужно с 1 октября запустить авто нумерацию с номера 00010000, но старые счета не трогать!
