 Восстановление пароля с версии 8.3.17
Восстановление пароля с версии 8.3.17 Бывают случаи когда нужно восстановить доступ к 1С, но пароль утерян или прошлый программист уволился и прочее. Доступные методы в интернете не работают с версии 8.3.17, а некоторые методы полностью вычищают список пользователей. Данный метод позволит просто сменить пароль администратора и восстановить доступ к 1С, но для его исполнения Вам нужен доступ к MS SQL
Пункт 1. Открываем Microsoft Management Studios, выбираем нужную базу, нажимаем правой кнопкой мыши, выбираем Новый запрос (New Query)
Пункт 2. Вставляем запрос, который указан ниже
EXEC sp_rename 'v8users', 'v8users_passwords_data'GOUPDATE ParamsSET FileName = 'users.usr_pd'WHERE FileName = 'users.usr'GO
DROP TABLE v8usersGO
create table v8users(ID binary(16) NOT NULL,Name nvarchar(64) NOT NULL,Descr nvarchar(128) NOT NULL,OSName nvarchar(128) NULL,Changed datetime2(0) NOT NULL,RolesID numeric(10,0) NOT NULL,Show binary(1) NOT NULL,Data varbinary(max) NOT NULL,EAuth binary(1) NULL,AdmRole binary(1) NULL,UsSprH numeric(10,0) NULL,PRIMARY KEY (ID));
Пункт 3. Открываем конфигуратор 1С (откроется с
DROP TABLE v8usersGOEXEC sp_rename 'v8users_passwords_data', 'v8users'GOUPDATE ParamsSET FileName = 'users.usr'WHERE FileName = 'users.usr_pd'GO
Пункт 4. Открываем в конфигураторе список пользователей (Администрирование - пользователи) и меняем пароль нужного пользователя. Закрываем конфигуратор и запускаем 1С, теперь пароль изменен.
Как посмотреть движения документа в управляемом приложении? При работе с документами в 1С очень часто возникает необходимость просматривать их движения по регистрам. И при работе с обычными формами в режиме толстого клиента никаких проблем не возникало. Кнопка Перейти и далее можно выбрать по какому регистру будем смотреть движения или сформировать отчет о движениях документа по всем регистрам.
Но когда в первый раз сталкиваешься с такой необходимостью в управляемом приложении, то оказывается, что не все так просто. И на первый взгляд кажется, что это вообще невозможно, т.к. в меню никаких подходящих команд обнаружить не удается. Конечно же с
И тем не менее с помощью определенных настроек мы можем добиться нашей цели и переходить к движениям регистров непосредственно из документа. Рассмотрим это на примере демо версии конфигурации ЗУП 3.1.
Итак, откроем любой документ Начисление зарплаты и взносов. В Шапке документа нет кнопки ПЕРЕЙТИ и нет ссылок на регистры движений, добавим их: выберем пункт меню Вид – Настройка панели навигации формы
В открывшемся окне выберем регистры, движения которых нам надо видеть и перенесем их в правую панель
В результате этих манипуляций шапка документа будет отображать названия регистров движений документа
И теперь, щелкнув по этим ссылкам, можно просматривать движения документа.
Как в excel сохраненный из 1С вставить новый лист? Я думаю, все сталкивались с однолистовым excel файлом из 1С, у которого на первый взгляд, нет возможности добавить листы. Все не так страшно - их просто скрыли или, что чаще всего - даже не отображали (обусловлено созданием файла из стороннего приложения, например 1С)
Решение:
Вот и все. Но бывает так, что вы и не увидите их с

нажать левую кнопку мыши и не отпуская её потянуть вправо(рис.2).

Ярлычки появятся!
Как изменить картинку главное в панели инструментов УП 1С? Разрабатывая конфигурацию, задался вопросом: Как изменить картинку раздела "Главное" в интерфейсе Такси?
С

Циклы в языке 1С, примеры и тест - какой цикл быстрее? Циклы применяются для выполнения каких либо повторяющихся действий, возможные варианты перебора в цикле:
Перебираем строки с помощью цикла Для каждого
Перебираем строки с помощью цикла Пока
Перебираем строки с помощью цикла Для
Еще вариант, но советую его использовать только в без выходных ситуациях, Если
Итак, я нашел пять способов, как можно организовать цикл средствами 1С.
Первый вид цикла, назовем его условно «Для По» выглядит так:
Второй вид «Для Каждого»:
Третий «Пока»:
Далее вспомнил ассемблерную молодость & цикл «Если»:
Ну и напоследок «Рекурсия»
Естественно, что относить рекурсию к циклам не совсем корректно, но тем ни менее с её помощью можно добиться похожих результатов. С
Последнее отступление. Одним из условий было выполнение в цикле каких-либо действий. Во первых пустой цикл используется очень редко. Во вторых цикл «ДляКаждого» используется для какой-либо коллекции, а значит и остальные циклы должны работать с коллекцией, чтобы тестирование проходило в одинаковых условиях.
Ну что ж, поехали. В качестве тела цикла использовалось чтение из заранее заполненного массива.
или, при использовании цикла «Для Каждого»
Тестирование проводилось на платформе 8.3.5.1231 для трех видов интерфейса (Обычное приложение, Управляемое приложение и Такси).
| Интерфейс | ДляПо | ДляКаждого | Пока | Если |
| Обычное приложение | 5734,2 | 4680,4 | 7235,4 | 7263,0 |
| Управляемое приложение | 5962,4 | 4882,6 | 7497,4 | 7553,6 |
| Такси | 5937,2 | 4854,6 | 7500,8 | 7513,0 |
Числа это время в миллисекундах полученное с помощью функции ТекущаяУниверсальнаяДатаВМиллисекундах(), которую я вызывал до цикла и после его завершения. Числа дробные, потому что я использовал среднее арифметическое пяти замеров. Почему я не использовал Замер производительности? У меня не было цели замерить скорость каждой строчки кода, только скорость циклов с одинаковым результатом работы.
Казалось бы и все, но & тестировать так тестировать!
| Интерфейс | ДляПо | ДляКаждого | Пока | Если |
| Обычное приложение | 4411,8 | 3497,2 | 5432,0 | 5454,0 |
| Управляемое приложение | 4470,8 | 3584,8 | 5522,6 | 5541,0 |
В среднем платформа 8.2 на 25% быстрее, чем 8.3. Я немножко не ожидал такой разницы и решил провести тест на другой машине. Скажу только, что там 8.2 была быстрее процентов на 20.
Почему? Не знаю, дезасемблировать ядро в мои планы не входило, но в замер производительности я все же заглянул. Оказалось, что сами циклические операции в 8.3 проходят несколько быстрее, чем в 8.2. Но на строке
то есть при считывании элемента коллекции в переменную происходит значительное снижение производительность.
Для себя я сделал несколько выводов:
1. Если есть возможность использовать специализированный цикл & «Для Каждого», то лучше использовать его. Кстати, сам по себе он отрабатывает дольше чем другие циклы, но скорость доступа к элементу коллекции у него на много выше.
2. Если заранее знаешь количество итераций & используй «Для По». «Пока» отработает медленнее.
3. Если использовать цикл «Если» & другие программисты тебя явно не поймут.
Установка сервера 1С 8.3 и PostgreSQL 9.2 на CentOS Заказали виртуальный сервер на FastVPS, купили мини сервер 1С и пришло время установки.
В сети нашлась хорошая статья, где все по порядку:
Итак, устанавливаем минимальный CentOS, настраиваем имена хостов, DNSы и сетевые подключения и приступаем собственно к установке серверных компонентов.
1. Установка Postgre SQL server
Обновление от 03-ноя-2016: в последних версиях CentOS (у меня сегодня был 7.2.1511) отсутствует поддержка libtermcap (и как-то "иначе" реализована libreadline), из-за чего сборки с сайта 1С не устанавливаются - решил поставить сборку от Postgres Professionals https://postgrespro.ru/products/1c_build - вроде работает, но о стабильности и производительности пока судить рано. Так что у кого проблемы с libtermcap.so.2() и/ли libreadline.so.5() при установке PostgreSQL с патчами 1С, можете попробовать этот альтернативный вариант.
Для установки использовался рекомендованный (адаптированный) 1С дистрибутив, для чего потребуется скачать его из раздела поддержки пользователей сайта 1С. В моём случае это был "Дистрибутив СУБД PostgreSQL для Linux x86 (64-bit) одним архивом (RPM)", который я сохранил в /root/temp. Распаковываем архив:
[root@vm-sql01 temp]# tar -vxf postgresql-9.2.1-1.1C_x86_64_rpm.tar.gz
postgresql92-9.2.1-1.1C.x86_64.rpm
postgresql92-libs-9.2.1-1.1C.x86_64.rpm
postgresql92-server-9.2.1-1.1C.x86_64.rpm
postgresql92-contrib-9.2.1-1.1C.x86_64.rpm
[root@vm-sql01 temp]#
Устанавливаем в следующей последовательности:
yum install postgresql92-libs-9.2.1-1.1C.x86_64.rpm
yum install postgresql92-9.2.1-1.1C.x86_64.rpm
yum install postgresql92-server-9.2.1-1.1C.x86_64.rpm
yum install postgresql92-contrib-9.2.1-1.1C.x86_64.rpm
Все недостающие зависимости (пакеты) будут установлены в процессе установки этих rpm, хотя на сайте 1С рекомендуют предварительно установить пакеты readline, libtermcap, krb5-libs и openssl, но в моём случае они либо уже были установлены, либо не были обнаружены в репозиториях.
2. Первый запуск Postgre SQL server
В отличии от сценариев установки большинства знакомых мне sql-серверов, postgres требует предварительной инициализации перед запуском, для чего существует два пути - первый, правильный:
[root@vm-sql01 pgsql]# su postgres -c '/usr/pgsql-9.2/bin/initdb -D /var/lib/pgsql/9.2/data --locale=ru_RU.UTF-8'
Файлы, относящиеся к этой СУБД, будут принадлежать пользователю "postgres".
От его имени также будет запускаться процесс сервера.
Кластер баз данных будет инициализирован с локалью "ru_RU.UTF-8".
Кодировка БД по умолчанию, выбранная в соответствии с настройками: "UTF8".
Выбрана конфигурация текстового поиска по умолчанию "russian".
исправление прав для существующего каталога /var/lib/pgsql/9.2/data... ок
создание подкаталогов... ок
выбирается значение max_connections... 100
выбирается значение shared_buffers... 32MB
создание конфигурационных файлов... ок
создание базы template1 в /var/lib/pgsql/9.2/data/base/1... ок
инициализация pg_authid... ок
инициализация зависимостей... ок
создание системных представлений... ок
загрузка описаний системных объектов... ок
создание правил сортировки... ок
создание преобразований... ок
создание словарей... ок
установка прав для встроенных объектов... ок
создание информационной схемы... ок
загрузка серверного языка PL/pgSQL... ок
очистка базы данных template1... ок
копирование template1 в template0... ок
копирование template1 в postgres... ок
ВНИМАНИЕ: используется проверка подлинности "trust" для локальных подключений.
Другой метод можно выбрать, отредактировав pg_hba.conf или используя ключи -A,
--auth-local или --auth-host при следующем выполнении initdb.
Готово. Теперь вы можете запустить сервер баз данных:
/usr/pgsql-9.2/bin/postgres -D /var/lib/pgsql/9.2/data
или
/usr/pgsql-9.2/bin/pg_ctl -D /var/lib/pgsql/9.2/data -l logfile start
-bash-4.1$
Или тот же вывод на английском языке:
[root@vm-sql01 ~]# su postgres -c '/usr/pgsql-9.2/bin/initdb -D /var/lib/pgsql/9.2/data --locale=ru_RU.UTF-8'
could not change directory to "/root"
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "ru_RU.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "russian".
fixing permissions on existing directory /var/lib/pgsql/9.2/data ... ok
creating subdirectories ... ok
selecting default max_connections ... 100
selecting default shared_buffers ... 32MB
creating configuration files ... ok
creating template1 database in /var/lib/pgsql/9.2/data/base/1 ... ok
initializing pg_authid ... ok
initializing dependencies ... ok
creating system views ... ok
loading system objects' descriptions ... ok
creating collations ... ok
creating conversions ... ok
creating dictionaries ... ok
setting privileges on built-in objects ... ok
creating information schema ... ok
loading PL/pgSQL server-side language ... ok
vacuuming database template1 ... ok
copying template1 to template0 ... ok
copying template1 to postgres ... ok
WARNING: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the option -A, or
--auth-local and --auth-host, the next time you run initdb.
Success. You can now start the database server using:
/usr/pgsql-9.2/bin/postgres -D /var/lib/pgsql/9.2/data
or
/usr/pgsql-9.2/bin/pg_ctl -D /var/lib/pgsql/9.2/data -l logfile start
[root@vm-sql01 ~]#
Или второй, более простой, но не всегда дающий необходимый результат (зависит от региональных настроек сервера, но у меня иногда приводивший к установке базы данных без поддержки необходимого collation ru_RU.UTF-8):
[root@vm-sql01 pgsql]# service postgresql-9.2 initdb
Инициализируется база данных: [ OK ]
[root@vm-sql01 pgsql]#
В результате была создана структура базы данных (с настройками) в /var/lib/pgsql/9.2/data. Хочу обратить особое внимание на конструкцию --locale=ru_RU.UTF-8, которую необходимо указать при инициализации, иначе сервер может быть инициализирован с неверным набором языковых параметров, что в конечном итоге приведёт к сообщениям
Ошибка установки или изменения национальных настроек информационной базы
Порядок сортировки не поддерживается базой данных
по причине:
Порядок сортировки не поддерживается базой данных
при установке информационной базы. Теперь можно настраивать автоматический запуск sql-сервера и, собственно, запускать его:
[root@vm-sql01 temp]# chkconfig postgresql-9.2 on
[root@vm-sql01 temp]# service postgresql-9.2 start
Запускается служба postgresql-9.2: [ OK ]
[root@vm-sql01 temp]#
Всё. Для локальных подключений сервер настроен. В моём случае сервер 1С и сервер SQL находятся на разных машинах, поэтому потребуется настроить и удалённые подключения с авторизацией.
В случае каких-то проблем, читаем содержимое файлов:
/var/lib/pgsql/9.2/pgstartup.log
/var/lib/pgsql/9.2/data/postgresql-*.log
Для повышения быстродействия документация PostgreSQL рекомендует как минимум унести журнал /var/lib/pgsql/9.2/data/pg_xlog на отдельный физический том и создать симлинк на него в исходном месте; из личных наблюдений - надо ещё и значительно увеличить размер используемой памяти... но необъятное не охватить, поэтому за статьями по оптимизации работы PostgreSQL для 1С предлагаю обращаться в поисковые системы, а оттуда - на профильные форумы.
3. Настройка пользователей (ролей) Postgre SQL server
Для управления PostgreSQL на начальном этапе потребуется сменить текущего пользователя на postgres и создать нового пользователя из командной строки:
[root@vm-sql01 temp]# su - postgres
-bash-4.1$ cd /usr/pgsql-9.2/bin
-bash-4.1$ createuser --interactive -P
Введите имя новой роли:server1c
Введите пароль для новой роли:
Повторите его:
Должна ли новая роль иметь полномочия суперпользователя? (y - да/n - нет) n
Новая роль должна иметь право создавать базы данных? (y - да/n - нет) y
Новая роль должна иметь право создавать другие роли? (y - да/n - нет) n
-bash-4.1$ exit
logout
[root@vm-sql01 temp]#
В принципе, для обслуживания полезно иметь пользователя с правами суперпользователя - создавать его можно тем же путём.
Теперь осталось разрешить удалённое подключение с авторизацией - для этого в файле /var/lib/pgsql/9.2/data/pg_hba.conf потребуется заменить значение ident на md5 в строке "host all all 0.0.0.0/0 md5" и перезапустить сервис.
Не следует забывать и про настройки iptables - для работы Postgre SQL необходимо открыть как минимум порт tcp 5432, хотя привычнее (да и проще) объявить сетевой интерфейс "внутренним" (разрешить все подключения на интерфейсе).
Для управления сервером потребуется pgAdmin, который можно установить из репозиториев используемого для административных целей линукса, либо скачать с сайта проекта.
4. Установка компонентов сервера 1С
Внимание!!! Для избежания проблем с зависимостями, желательно, чтобы разрядность сервера 1С совпадала с разрядностью используемого дистрибутива Linux! Иначе (если ставим 32-битный 1С на 64-битный Linux), при входе в базу, можно получить сообщение типа "Ошибка загрузки библиотеки libWand.so по причине:Библиотека не обнаружена. Часть функций будет недоступна." и клиенты не будут запускаться (хотя конфигуратор - будет). В принципе, я с этой проблемой справился на CentOS 7 (которой не выпускают больше в 32-битном исполнении) - просто поставил не только 'ImageMagick', но и 'ImageMagick.i686' (yum install ImageMagick.i686) - всё заработало (хоть и притянуло за собой гору зависимостей).
Первый шаг установки сервера 1С мало отличается от аналогичного этапа с SQL-сервером - распаковать скачанный дистрибутив сервера командой tar -vxf rpm64.tar.gz. В итоге получим файлы:
1C_Enterprise83-common-8.3.3-715.x86_64.rpm - основные файлы 1С (включая русский и английский интерфейсы)
1C_Enterprise83-common-nls-8.3.3-715.x86_64.rpm - дополнительные языковые модули
1C_Enterprise83-server-8.3.3-715.x86_64.rpm - сервер 1С
1C_Enterprise83-server-nls-8.3.3-715.x86_64.rpm - дополнительные языковые модули
1C_Enterprise83-ws-8.3.3-715.x86_64.rpm - компоненты вэб-сервера 1С
1C_Enterprise83-ws-nls-8.3.3-715.x86_64.rpm - дополнительные языковые модули
1C_Enterprise83-crs-8.3.3-715.i386.rpm - хранилище конфигураций (только в 32-битном комплекте)
Устанавливаем нужные пакеты командами:
yum install 1C_Enterprise83-common-8.3.3-715.x86_64.rpm
yum install 1C_Enterprise83-server-8.3.3-715.x86_64.rpm
Настраиваем автоматический запуск демона и стартуем его:
[root@vh-1c83 temp]# chkconfig srv1cv83 on
[root@vh-1c83 temp]# service srv1cv83 start
Starting 1C:Enterprise 8.3 server: Error: service failed to start!
FAILED
[root@vh-1c83 temp]# service srv1cv83 start
Starting 1C:Enterprise 8.3 server: OK
[root@vh-1c83 temp]#
Хочу обратить внимание - если с
Для работы с графическими объектами и экспорта в xls, могут потребоваться дополнительные пакеты: ImageMagick, freetype (входит в зависимости ImageMagick), libgsf (входит в зависимости ImageMagick), corefonts (отсутствует в репозитариях CentOS - см. раздел 6); для "ТАКСИ" и "Управляемого приложения" они необходимы, для классического толстого клиента вроде бы не особо нужны, но 1С всё равно ругается на их отсутствие, хоть и работает.
По умолчанию сервер 1С слушает порт tcp 1541(1540) и для соединений использует диапазон портов 1560-1691.
5. Настройка экземпляра (кластера) сервера 1С
Информации о наличии оснастки управления сервером 1С для Linux мне не попадалось, так что для управления сервером будем использовать традиционную оснастку mmc для Windows "Администрирование серверов 1С:Предприятия", которую следует поставить из дистрибутива технологической платформы для Windows.
В этом месте на тестовом сервере возникли трудности - кластер по умолчанию отсутствовал, а при попытке создания нового кластера, ragent аварийно завершал работу с сообщением Sep 3 21:29:04 vh-1c83 kernel: ragent[1879]: segfault at 8 ip 00007f56473c9fd4 sp 00007f563b7b14a0 error 4 in rserver.so[7f56472db000+70e000]... странно, но если верить форумам, на CentOS у многих сервер 1С 8.3 ставится некорректно - не создаётся начальная конфигурация, включающая "Кластер по умолчанию". Краткий анализ ситуации выявил, что настройки кластера по умолчанию не были сгенерированы полностью и не попали в /home/usr1cv8/.1cv8/1C/1cv8/.
При попытке подложить файлы с рабочего сервера на неудачный, сервис 1С не запускается абсолютно без каких-либо диагностических сообщений - подобное поведение я видел при проблемах (неверных контекстах) SELinux, но в данном случае никаких отказов в audit.log не обнаружилось.
В результате детального изучения проблемы с применением strace удалось выяснить, что агент сервера при запуске ищет настройки по пути ~/.1cv8/1C/1cv8/ (в домашнем каталоге запустившего пользователя) и если не находит, пытается создать настройки кластера по умолчанию, для чего ему нужно имя хоста (выяснено экспериментально), и если верить "Руководству администратора", нужен корректно работающий DNS; экспериментально же был установлен факт, что сначала ragent читает файл /etc/hosts, затем обращается к DNS-серверу, а затем вызывает uname и снова лезет в hosts и к DNS и если не находит сопоставления, аварийно завершается. Итак, для нормального запуска потребуется полноценная и правильно настроенная сетевая инфраструктура, ну а в отсутствии работающего DNS достаточно дописать строчку в /etc/hosts и привести его примерно к такому виду:
127.0.0.1 localhost
192.168.122.227 vh-1c83.test.lan vh-1c83
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
За дальнейшими инструкциями пока отсылаю к своей статье про 8.2 - принципиальных отличий пока нет. Единственное замечание - при создании новой информационной базы, если указывать пользователя подключения к базе данных не с правами суперпользователя (а с набором прав из пункта 3), информационная база не создавалась, а в /var/lib/pgsql/9.2/data/pg_log/postgresql-Xxx.log наблюдались сообщения:
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: нет доступа к языку c
ОПЕРАТОР: CREATE OR REPLACE FUNCTION plpgsql_call_handler() RETURNS language_handler AS '$libdir/plpgsql' LANGUAGE C
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: ошибка синтаксиса (примерное положение: "application") в символе 24
ОПЕРАТОР: lock table pg_class in application share mode
ПРЕДУПРЕЖДЕНИЕ: нет незавершённой транзакции
ОШИБКА: тип "mvarchar" не существует в символе 31
ОПЕРАТОР: create table Config (FileName mvarchar(128) not null, Creation timestamp not null, Modified timestamp not null, Attributes int not null, DataSize int8 not null, BinaryData bytea not null, PartNo int not null, PRIMARY KEY (FileName, PartNo))
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: нет доступа к языку c
ОПЕРАТОР: CREATE OR REPLACE FUNCTION plpgsql_call_handler() RETURNS language_handler AS '$libdir/plpgsql' LANGUAGE C
После подключения с учётными данными суперпользователя БД, сообщения изменились на англоязычные и проблемы исчезли. Судя по всему, если на сервере установлен язык по умолчанию en_US, данного казуса не случится, но это - не проверенная информация, а лишь предположение, сделанное по прочтении чужой статьи про 8.1 и праздных раздумий =)
Ещё одна странность - если создать пустую SQL базу не из шаблона1 (см. официальную документацию по 1С), и попытаться ей указать на этапе создания ИБ, то всё равно получим сообщение "ОШИБКА: тип "mvarchar" не существует (символ 31)"/"ERROR: type "mvarchar" does not exist at character 31", но мне так и не удалось создать из требуемого шаблона БД - валились разные ошибки, но если пользователя sql, от которого создаётся ИБ временно повысить до суперпользователя с правом создания БД, и указать создание базы данных в случае её отсутствия, то всё получается в лучшем виде, так что на этапе первичной настройки, видимо, придётся повышать пользователя до супер...
Что порадовало - теперь в 1С можно работать непосредственно из Linux, что актуально для компаний, использующих его как основную ОС в корпоративной сети (я сейчас работаю как раз в такой компании); из неожиданностей - что при установке клиента 1С, он заявляет о зависимости от сервера и требует его установки, но потом ставится, прописывает значки запуска в "Офис" - "Финансы" и работает довольно сносно (по ощущениям - чуть менее комфортно, чем 8.2 под Windows, но заметно приятнее, чем тот же 8.2 через WINE от Ethersoft).
6. Установка недостающих зависимостей
При запуске клиента к настроенному по данной инструкции серверу, появится сообщение "На сервере отсутствуют шрифты из состава Microsoft Core Fonts. Внешний вид приложения может отличаться от ожидаемого. Процедура установки описана в справочной системе..." - данное сообщение появляется достаточно редко (периодичность не выявил, но появляется точно не единожды, но и не при каждом запуске), и на работе особо не сказывается, но "для красоты" я решил пройтись по всей цепочке и поставить рекомендуемые пакеты. Всё, кроме "corefonts" поставилось из репозиториев (хотя в той самой "справочной системе" безбожно перепутаны регистры в названиях пакетов, из-за чего их идентификация оказалась весьма развлекательна), ну а шрифты я решил пересобрать (в соответствии с рекомендациями из "справочной системы") и результат прикрепляю к статье - msttcorefonts-2.5-1.noarch.rpm, заодно и сами шрифты (уже переименованные в нижний регистр, как происходит при сборке rpm рекомендованным скриптом) - msttcorefonts.tar.gz - содержимое этого архива рекомендуют распаковать в /home/usr1cv8/.fonts (не забыв сменить владельца как на папку, так и на файлы!), если нет возможности установить предложенный .rpm
Кроме "ImageMagick" и шрифтов, для возможности сохранения в табличные файлы (кроме xls - его я пока не заставил формироваться, хотя xlsx формируется), на клиенте должны быть установлены пакеты "libMagickWand5", "libgomp1", "liblcms2-2" и "libbz2-1" - на ряде машин они отсутствовали. При чём той же разрядности, что и сервер 1С (см. п. 4).
7. Настройка аппаратного hasp для виртуализированного сервера 1С (работающего на виртуальной машине KVM)
Не планировал описывать эту процедуру, но раз уж столкнулся с такой ситуацией, опишу... Итак, на этот раз я использовал драйвер от "Alladin Knowledge Systems USB HASP", предоставляемый компанией Sentinel - мне попались две версии:
2878061 сен 11 2012 aksusbd-2.0-1.i386.rpm - с сайта aladdin-rd.ru
3009880 авг 6 16:35 aksusbd-2.2-1.i386.rpm - с сайта safenet-inc.com
Можно воспользоваться драйвером эзерсофт - окончательный выбор следует делать из опыта практической эксплуатации.
Наиболее правильная (на мой взгляд) последовательность действий:
а) убедиться, что на хост-машине драйвер HASP не установлен;
б) установить выбранный драйвер USB HASP4 на виртуальном сервере;
в) выяснить список подключенных USB-устройств к хост-машине
[root@vh01 files]# ls -R /dev/bus/usb
/dev/bus/usb:
001
002
003
004
/dev/bus/usb/001:
001
002
/dev/bus/usb/002:
001
/dev/bus/usb/003:
001
/dev/bus/usb/004:
001
[root@vh01 files]#
г) подключить USB-HASP к хост-машине и выяснить адрес ключа:
[root@vh01 files]# ls -R /dev/bus/usb
/dev/bus/usb:
001
002
003
004
/dev/bus/usb/001:
001
002
/dev/bus/usb/002:
001
/dev/bus/usb/003:
001
/dev/bus/usb/004:
001
002 <==== это наш ключ - раньше его не было
[root@vh01 files]#
д) используя любой из способов (я использовал Virtual Manager на удалённой машине) добавить "USB Host Device" с найденным адресом (в моём примере - 004:002) к виртуальной машине 1С - может потребоваться выключение и включение машины (я добавлял устройство на выключенную машину).
Собственно, всё - на CentOS 6.4 x64/i686 всё работает (были багрепорты про CentOS 6.0/6.1, но вроде всё починили). Если при запуске виртуалки выдаётся сообщение о занятости устройства, скорее всего подцепился драйвер на хост-машине (так писали на паре форумов, хотя мне эту ситуацию воспроизвести не получилось - даже с установленным драйвером на сервере устройство мапилось корректно). Естественно, если переставить ключ в другой порт USB, придётся перенацеливать и виртуальную машину!
И напоследок, коротко о том "что где лежит":
/etc/sysconfig/srv1cv83 - файл конфигурации сервера 1С
/home/usr1cv8/.1cv8/1C/1cv8/1cv8wsrv.lst - файл, в котором хранятся основные свойства сервера - например, учётные данные администратора сервера, зарегистрированые кластеры и т.п.
/home/usr1cv8/.1cv8/1C/1cv8/reg_1541/1CV8Clst.lst - файл, в котором хранятся свойства кластера по умолчанию
/opt/1C/v8.3/x86_64/ - (вместо "x86_64" может быть "i386" - в зависимости от архитектуры системы) исполняемые файлы и сопутствующие ресурсы сервера (и клиента) 1С
/var/1C/licenses - здесь лежат файлы электронных ключей лицензий
8. Настройка локального репозитория 1С для удобства обновления платформы
В процессе эксплуатации 1С нередко приходится обновлять платформу. Если всё установлено по приведённой выше инструкции, это вызывает определённые неудобства - надо останавливать сервис, удалять старые пакеты, ставить новые... не знаю - мне это ещё в винде надоело смертельно. Linux предлагает очень удобный механизм пакетного обновления из локального репозитория - всё, что нужно - это выбрать место, где будут лежать обновки: для одиночного сервера, к которому все ходят только через web-интерфейс, это может быть /root/repo (всё равно обновление под рутом идёт), ну а в общем случае - хоть /var/www/1c-repo - главное, чтобы все, кому он нужен, его видели. Далее надо установить пакет 'createrepo' (yum install createrepo) - за собой он притащит немало зависимостей, но не смертельно. Теперь командой 'createrepo /root/repo' (где "/root/repo" - выбранный путь хранения репозитория) создаём его "описание" и можно пользоваться.
Затем создаём файл описания нашего репозитория и помещаем его в каталог описаний репозиториев (для CentOS это /etc/yum.repos.d). Пример конфига локального файлового репозитария:
[root@1c yum.repos.d]# cat local-1c.repo
[local-1c]
name=1C Enterprise
#baseurl=http://inhost.firm.lan/repo
baseurl=file:///root/repo
gpgcheck=0
enabled=1
По-моему, разъяснять что за что отвечает, особого смысла нет. Единственное, что важно - с
Всё. Теперь если надо обновиться, то помещаем новые файлы дистрибутива 1С рядом со старыми, повторяем 'createrepo /root/repo' вызываем 'yum update' - и всё - платформа пошла обновляться! Естественно, за сохранностью и защищённостью своего репозитория надо следить, так как GPG у нас выключен, и это всё же дыра в безопасности, хоть и не особо толстая...
Как очистить справочник удалив все не используемые элементы? Очень часто менеджеры дублируют информацию в справочниках и время от времени их приходится чистить.
Но как удалить только те элементы справочника, которые не используются в документах?
Следующий пример кода поможет это сделать(в примере обрабатывается 4 справочника: Сотрудники, ФизЛица, Договора и Контрагенты) Скачать: Обработка для УТ 10:
Функции сохранения таблицы значений в файл и чтения из файла В данном примере хочу привести несколько универсальных функций по выгрузке таблицы значений в файл и дальнейшего чтения из файла:
Порядок программных действий при выгрузке в файл выглядит так:
При загрузке таблицы порядок действий такой:
Соответственно файл для хранения данных таблицы имеет расширение *.mxl.
Основные функции для реализации поставленной задачи следующие:
ПреобразоватьТДвТЗ – Функция преобразования табличного документа в таблицу значений.
ПреобразоватьТЗвТД – Функция обратного преобразования таблицы значений в табличный документ.
ПрочитатьТЗИзMXL – Читает из файла данные, определяет колонки таблицы и преоб
ЗаписатьТЗВMXL – Преоб
Еще небольшой набор функций для вывода таблицы значений в табличный документ. После формирования табличного документа, - сохраняем его в файл mxl.
Табличный документ можно сохранить a файлы следующих типов:
Пример выгруженной таблицы значений в файл:

Ошибка Таблица не найдена Константы Сегодня после обновления 1С:Бухгалтерии предприятия на версию 2.0.64.6, при открытии Регламентированных отчетов стала появляться ошибка следующего содержания:
{(5, 2)}: Таблица не найдена «Константы» <<?>>Константы КАК Константы

Причем ошибка появилась с
Следующие варианты помогли в разных случаях:
PostgreSQL: установка, настройка, обслуживание PostgreSQL напрямую "из коробки" применяться для использования с 1С Предприятем не может. Необходима именно адаптированная версия от 1С, превращающая PostgreSQL в блокировочник, причем нужно понимать, что блокировки будут накладываться на всю таблицу с
Установка
Сама установка особых затруднений не вызывает, обратить внимание нужно на правильную инициализацию базы данных, а именно настройку локали, изменить потом это можно только повторной начальной инициализацией. Например, база 1С с украинскими региональными установками в СУБД с установленной русской локалью не загрузится. Да и проблемы с сортировкой потом не нужны. Поэтому делаем init в соответствии с нужным языком.
Для русского языка
initdb --locale=ru_RU.UTF-8 --lc-collate=ru_RU.UTF-8 --lc-ctype=ru_RU.UTF-8 --encoding=UTF8 -D /db/postgresql
Для украинского языка
initdb --locale=uk_UA.UTF-8 --lc-collate=uk_UA.UTF-8 --lc-ctype=uk_UA.UTF-8 --encoding=UTF8 -D /db/postgresql
где /db/postgresql ваш каталог данных PostgreSQL. Кодировка, конечно же, UTF-8.

Подробный вариант пересоздания кластера
1.Необходимо выдать полные права на папку в которую мы установили PostgreSQL, обычно это C:\Program Files\PostgreSQL
2.Из под админских прав запускаем cmd. Если это делаете в win7, то запускаем от Администратора.
3.Создаем папку где будет храниться кластер. Например d:\postgredata.
md d:\postgredata
4.Проводим инициализацию кластера вручную с указанием пути где он будет находиться.
“C:\Program Files\PostgreSQL\9.1.2-1.1C\bin\initdb.exe” -D d:\postgredata --locale=Russian_Russia --encoding=UTF8 -U postgres
5.Удаляем службу PostgreSQL, которая была установлена в ходе установки.
sc delete pgsql-9.1.2-1.1C-x64
Где pgsql-9.1.2-1.1C-x64 – Это название службы. Если не знаете название точно, можно посмотреть свойствах службы “PostgreSQL Database Server…” (Пуск – Панель управления – Администрирование – Службы )
6.Создаем новый сервис с указанием нашего кластера
“C:\Program Files\PostgreSQL\9.1.2-1.1C\bin\pg_ctl” register -N pgsql -U postgresql -P пароль -D d:/postgredata
7.Теперь заходим в службы. Пуск – Панель управления – Администрирование – Службы и стартуем нашу службу.
Ошибка СУБД: ERROR: new encoding (UTF8) is incompatible with the encoding of the template database (WIN1251).
HINT: Use the same encoding as in the template database, or use template0 as template.
Вы выбрали неправильную локаль при установке СУБД (WIN1251) для сервера и клиента, нужно изменить на UTF-8 в конфигурации или переустановить СУБД со следующими параметрами:

Внимание при установке НЕ выбирайте локаль Настройки ОС, выбирайте из списка Russian, Russia
Настройка PostgreSQL
Следует помнить о рекомендации 1С не использовать в запросах конструкции ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ и заменять его, используя, например, комбинацию из нескольких левых соединений. Известна также проблема с потерей производительности в запросах, где применяется соединение с виртуальной таблицей СрезПоследних, к ней рекомендуется делать отдельные запросы и сохранять результаты во временных таблицах.
Настройка конфигурации производится редактированем файла postgresql.conf.
Наиболее важные параметры
effective_cache_size = 0,5 от ёмкости RAM
fsync = off отключаем сброс на диск после каждой транзации (Внимание! Применять только при использовании надежного UPS, есть опасность потери данных при неожиданном отключении)
synchronous_commit = off отключаем синхронную запись в лог (риски теже, что и у fsync)
wal_buffers = 0,25 от ёмкости RAM
После настройки не забываем выполнить перезапуск службы:
service postgresql restart
Настройка сети
Для подключения клиентов 1С к серверу извне и работы сервера баз данных, на файрволе, должны быть открыты следующие порты:
Агент сервера (ragent) & tcp:1540 Главный менеджер кластера (rmngr) & tcp:1541 Диапазон сетевых портов, для динамического распределения рабочих процессов & tcp:1560&1591, tcp:5432 & Postgresql. Создадим правило через стандартный интерфейс, либо с помощью команды:
netsh advfirewall firewall add rule name="1Cv8-Server" dir=in action=allow protocol=TCP localport=1540,1541,5432,1560-1590 enable=yes profile=ANY remoteip=ANY interfacetype=LAN
Теперь с другого компьютера мы спокойно запускаем клиент 1С:Предприятия, добавляем существующую информационную базу newdb. Не забываем про лицензии, программной / аппаратной защиты.
Резервное копирование
Создание дампа базы данных делаем командой
su postgres -c 'pg_dump -U postgres -Fc -Z9 -f baza1.sql baza1'
Восстановление из дампа
su postgres -c 'pg_restore -U postgres -c -d baza1 -v baza1.sql'
Периодическое обслуживание
Рекомендуется настроить AVTO VACUUM в файле конфигурации. Но не пренебрегаем и запуском через планировщик принудительной команды.
su postgres -c '/usr/bin/vacuumdb --dbname=$i --analyze --full --quiet'
Просмотр активности PostgreSQL
Иногда полезно видеть чем сейчас занимается сервер. Поможет такая конструкция:
watch -n 1 'ps auxww | grep ^postgres'
Строку в дату по форматной строке Категория: Работа с Датами (Временем) Полезные возможности редактора кода 1С Мне частенько приходится взаимодействовать с 1С-разработчиками, и во время совместной работы над проектами замечаю, что далеко не все из них хорошо знают свой главный инструмент – «Конфигуратор». Причем это не относится к степени крутости девелопера. Как оказалось, даже синьоры пользуются далеко не всеми возможностями «Конфигуратора», а ведь они могут сэкономить кучу времени, а тем самым повысить продуктивность разработчика.
Под катом я решил собрать несколько полезных фишек стандартного конфигуратора, которыми пользуюсь регулярно. Многие из них появились в платформе «1С:Предприятие 8.3.х», поэтому перед тестированием обязательно проверьте номер версии установленной у вас платформы.
Функция установки в коде закладок появилось еще с первых релизов 8-й версии платформы «1С:Предприятие». Штука чрезвычайно полезная и помогает разработчику быстрей передвигаться по коду. Например, у нас есть большой модуль, в который мы решили добавить ряд функций. Естественно, потом нам предстоит их отлаживать, а соответственно постоянно между ними переключаться.
Хорошо, если новые функции добавлены в самый конец модуля, а если потребовалось расположить в разных частях? Вот тут начинается самое интересное. Одни программисты начинают скролить текст (как правило, этим страдают новички). Более продвинутые применяют поиск по тексту (Ctrl + F).
Оба способа рабочие, но пользоваться ими долго. Куда правильней использовать функцию «закладки». Например, переходим к какой-нибудь строке. Нажимаем ALT + F2 и получаем закладку (слева от строки отобразиться квадратик).

Убирается закладка тем же сочетанием клавиш. Так вот, закладок может быть в модуле расставлено много. По ним легко передвигаться нажатием клавиши F2. Фича крутая, но она была изначально не доделана и не позволяла, например, передвигаться по закладкам в разных модулях. Это досадное ограничение создавало лишние тормоза для программистов, привыкших к хорошим IDE (например, Visual Studio, PHP Storm).
В версии 8.3 недочет исправили и сделали классную вещь – «Список закладок». Нажимаем клавиши «Ctrl + Shift + F2», и перед нами откроется окно с полным списком установленных закладок:

В нем перечислены все закладки в разрезе модулей. Для каждой закладки указан номер строк и доступен перечень действий: перейти к коду, удалить закладку, удалить все закладки.
Таким образом, работать с закладками стало на порядок проще. Еще бы добавили возможность установки горячих клавиш на закладки, и стало бы совсем хорошо. Помню еще со времен «Delphi 6» привык к установке закладок по горячим клавишам Alt + <Цифра>. Наставил закладок и быстро перемещайся по ним.
В «1С:Предприятие» с самого начала была одна большая проблема – отсутствие возможности создавать дополнительные модули для определенных объектов. Например, есть у меня справочник «Контрагенты» и мне хочется разделить его функционал на модули. Допустим, функционала очеееень много. Так вот, в моем распоряжении все равно стандартный набор: Модуль объекта, Модуль менеджера и модуль формы. Понятное дело, что у каждого модуля своя роль, но что делать мне с моими 100500 функциями, которые относятся непосредственно к справочнику «Контрагенты»?
По мнению 1С я должен оформить их в виде общего модуля. С одной стороны, идея классная. Делаем модуль, его с
Вот взять хотя бы библиотеку БСП. Стоит ее внедрить и в количестве модулей начинает теряться. Я уже молчу про конфигурации, которые построены на базе БСП. Там и сто пятьсот модулей от БСП, и еще столько же специально для конфигурации.
В общем, неудобство налицо (особенно после опыта разработки в языках, где нет подобных ограничений). Увы, спастись от этой проблемы в настоящее время не получится. Зато, мы можем использовать возможности группировки функций/процедур в модулях.+
Например, есть у нас общий модуль «РаботаСКонтрагентами». В нем часть функций отвечают за поиск контрагента, другая часть за загрузку контрагентов из внешних источников и т.д. Чтобы не потеряться во всем этом многообразии возможностей, можно логически сгруппировать все функции/процедуру. Для этого в платформе 8.3 появилась функция под названием «Области». Рассмотрим пример:
После добавление областей (язык препроцессора) наш код будет сгруппирован. Если их свернуть (области), то в итоге мы увидим симпатичный комментарий (см. рисунок ниже):

Клик мышкой по плюсику развернет область, и мы увидим свернутые функции. Если хочется с
Вот такая мега удобная вещь и в модулях с большим количеством функций спасает очень даже. В предыдущих версиях платформы было модно использовать для подобных целей блоки комментариев, но управлять/добавлять областями явно удобней.
Собственно говоря, тут и рассказывать особо нечего – выделяем код, нажимаем «Alt + Shift + F» и редактор попытается привести его в божеский вид в соответствии с вшитым code-style. Функция работает вполне сносно и ей обязательно надо пользоваться. Пишу это потому, что неоднократно видел, как разработчики пытаются отбивать отступы самостоятельно. Это конечно круто, но зачем тратить время, если большую часть работы можно выполнить одной горячей клавишей?
Опять же, никаких секретных действий – выделили код, нажали “Ctrl + num /” (слеш на дополнительной области клавиатуры) и получили закомментированный участок. Захотели вернуть обратно? Не беда! Выделяем закомментированный участок кода, нажимаем «Ctrl + Shift + num /» и мгновенно приводим его в боевой режим. Фишка попсовая, но опять же, новички про нее не знают, и тратят кучу времени на расстановку слешей. Да еще и матерят компанию «1С», за отсутствие возможности многострочного комментирования, как в продвинутых язык программирования.
Быстрая вставка специальных символов
Иногда возникает необходимость быстро вставить в редактор специальный символ (которого нет на клавиатуре). В большинстве случаев разработчики используют для этого функции встроенного языка (например, символ). А ведь есть способ проще. Если удерживать клавишу Alt и набрать на доп. клавиатуре код нужного символа (из таблицы ASKII), то он тут же будет вставлен. Например, держим ALT и набираем 65. На выходе получаем букву «А». Или вводим 4 и получаем бубновую масть.

Хорошо, с этим понятно, но какой от этого еще можно получить профит? Лично я, таким образом вставляю символ амперсанда (&). Все знают, что этот символ используется для определения параметров в языке запросов. Неудобство состоит в том, что текст запроса мы пишем на русском языке, а для добавления этого символа перед параметром приходится переключить на английский, затем нажать Shift + 7, а потом вернуться обратно на русский.
Чтобы избавить себя от этой рутиной последовательности действий, я использую выше озвученную функцию. С ее помощью для установки амперсанда требуется лишь набрать с удержанной клавишей «alt» последовательность цифр 38. При этом надобность в двойном переключении языка отпадает.
Многие могут подумать, что я искусственно раздул проблему из ничего, но тут просто дело привычки. Кода приходится писать много и вот такие мелочи немного повышают производительность и избавляют от лишних нажатий клавиши backspace (для удаления случайно набранных символов). Не убедил? Тогда просто выделите время и попробуйте себя переучить
Автор: Игорь Антонов
Деноминация 2016 в 1С Чтобы провести деноминацию в 1С на 1 июля 2016 года, нужно учесть, что желательно учёт вести в двух суммовых измерениях в белорусских рублях старого и нового образца. Однако, даже если Вы решите упростить задачу и проведёте деноминацию в программе вручную или с помощью обработки на 1 июля, то есть деноминируете итоги в соотношении 1:10000, то получите "кашу" в базе данных. Такие отчёты как ОСВ, акт сверки, карточка счёта, журнал-ордер и все остальные в программе 1С будут воспринимать данную операцию как "логичную". Обороты за период "поплывут", а итоги будут суммировать старые и новые деньги как равнозначные. Поэтому этот вариант исключим с
Пять вариантов решения:
1)Корректный вариант!Разделить базу данных на две. Во второй провести деноминацию 1 июля.
Выполнить доработку форм и метаданных до копеек. Первое полугодие в первой базе оставить как есть. А учёт во втором полугодии, во второй базе, уже начать вести в денежном выражении нового образца. Перед разбиением базы на две, нужно доработать модуль и все метаданные, создать её копию и сделать свёртку обработкой WRAP.ert. Потом, этой же обработкой, в новой базе провести деноминацию - убрать из уже сделанных, во втором квартале, проводок и метаданных "0000". Но есть один недостаток. Разбивая базу на две Вы лишитесь оперативность при получении данных. Теперь, например, для того чтобы построить акт сверки за год по контрагенту - придётся делать это в двух базах! Выбирая этот вариант нужно понимать все нюансы разделения базы на полугодия.
2)Корректный вариант!Проведение деноминации в рабочей базе (без разделения):
Выполнить доработку форм и метаданных до копеек. Создать сторнированные проводоки с учётом коэффициента деноминации 10000 (то есть если на Сч.по Дт.=3.000.000 -> будет сделана проводка Дт. -2.999.700 -> в итоге Сч.Дт=300). Внимание! Нужно иметь ввиду, что отчёты желательно строить в двух экземплярах (до 1 июля и после).
Выполнить доработку форм и метаданных до копеек.
3) Корректный вариант, но очень затратный! Доработать все метаданные 1С для деноминации и провести её на 1 июля 2016 года.
Самый дорогой вариант для предприятия.
В версии 8.2 и 8.3 можно создать дополнительное измерение "сумма в рублях старого образца".
В версии 7.7 на невалютных счетах можно использовать вал.сумму или доп.забалансовый счёт (рубли образца 2009 года).
Плюс ко всему придётся переделать практически все объекты метаданных. Отчеты, справочники, документы, обработки, глобальный(7.7) и общие(8) модули, план счетов, регистры и т.п. Реализовать данный метод смогут лишь крупные предприятия с массивным штатом программистов 1С.
4) Признан некорректным! Продолжить вести учёт в старых денежных единицах.
Совершенно не затратный и для большинства компаний самый оптимальный, так как делать то ничего и не надо. Коротко говоря - оставить всё как есть. В шапке некоторых отчётов, например, акта сверки, для корректности, можно добавить ф
5) Признан некорректным! Разделить базу данных на две. Во второй провести деноминацию 1 января.
"Закрыть" период (первое полугодие) в первой базе, чтобы больше не вносить туда изменения. Во второй базе сделать свёртку обработкой WRAP.ert на 1 января. Незабудьте предварительно создать копию. Соответственно с 1 января 2016г. учёт будет деноминированный. Помните, что вносить изменения (если таковые будут) до 01 июля 2016 придётся вносить в обе информационные базы. В начале 2017 можно будет свернуть и обрезать Вашу рабочую базу на 1 июля. Так у Вас будет две базы: 1-я до 1.07.2016 (без деноминации) и 2-я после 1.07.2016 (с деноминацией).
6) Признан некорректным! Доработать только отчёты в 1С для деноминации 1 июля 2016 года.
В отчётах, которыми чаще всего пользуются бухгалтера для отправки данных "внешним" контрагентам (акт сверки, деб.задолженность, отчёт по движению ДС и т.п.), выводить дополнительную строку с коэффициентом 1:10000 под суммой с названием "сумма в белорусских рублях образца 2009 года".
Google maps : вывод точек на карту и режим панорамы В отличие от яндекс карт в GMaps можно использовать панорамы - за что им большой плюс! Надеюсь в яндексе прочитают этот пост и тоже когда-нибудь это сделают!
Для клиента нужно было сделать вывод объектов на карту
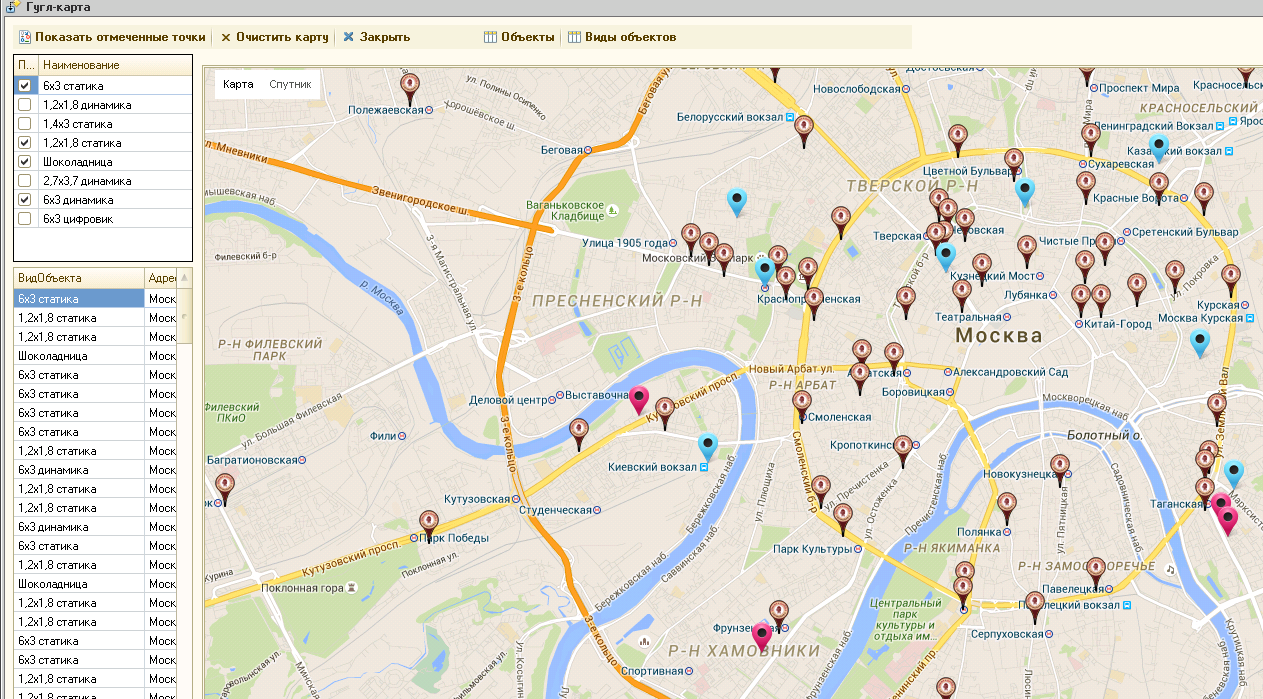
С возможностью просмотра панорамы:

Основной HTML код карты хранится в макете:
Код вывода карты:
Вырванная из конфигурации обработка GMaps.rar
Можно ее использовать как макет для создания обработки под свои требования.
SMTP greeting failure: 421 SMTP connection broken (reply) Описание ошибки:С сентября 2014 Яндекс.Почта, Mail.ru перешли на протокол SSL, что сделало их ещё более безопасными. Чтобы и дальше работать с письмами через 1С, Вам нужно изменить их настройки и внести доработки в код конфигураций.
Найденные решения:
Ошибка наблюдается, в частности, в случае, когда меняются настройки почты. Например мне довелось столкнуться в случае, когда ввели для почты SSL-шифрование. Если это Ваш случай, то из быстрых и простых остается только обновление до версии платформы 8.3, где поддержка этого шифрования для "ИнтернетПочтовыйПрофиль" реализована. И доработка кода типовых конфигураций для учета настроек SSL-шифрования и включения у почтового профиля.
Сопровождающие проблему ошибки:
адрес_почты@yandex.ru. {ОбщийМодуль.УправлениеЭлектроннойПочтой.Модуль(1065)}: Ошибка при вызове метода контекста (Подключиться): Почтовый ящик пользователя "адрес_почты@yandex.ru" на сервере "pop.yandex.ru" не найден. Ответ сервера: "[AUTH] Working without SSL/TLS encryption is not allowed. Please visit https://help.yandex.ru/mail/mail-clients/ssl.xml. sc=NXhLmqHbM4YK"
Если установлены не правильные порты, то получим ошибку:Ошибка при вызове метода контекста (Подключиться): TLS/SSL failure for smtp.mail.ru: Invalid token, probably not an SSL serverУстановите порты 465 для smtp, 995 для pop3.
При соединении с Яндексом: в логинах оставить только содержимое логина до @yandex.ru, т.е. из примера "адрес_почты" (без кавычек). Устанавливаем для pop3 и smtp SSL-шифрование. Если почта корпоративная на Яндексе, и в наименовании не используется @yandex.ru, то оставляем логин, равный наименованию почты, как есть.
Не включено SSL-шифрование для учетной записи электронной почты. Ошибка при вызове метода контекста (Подключиться): Can not authenticate to POP3 server: POP3 is available only with SSL or TLS connection enabled
Если установлены не правильные порты, то получим ошибку:Ошибка при вызове метода контекста (Подключиться): TLS/SSL failure for smtp.mail.ru: Invalid token, probably not an SSL serverУстанавливаем порты 465 для smtp, 995 для pop3.
Если возникает ошибка:Ошибка при вызове метода контекста (Подключиться): Can't connect to smtp.mail.ru,495: Timed out - значит неправильно указан порт.
Если возникает ошибка:Ошибка при вызове метода контекста (Подключиться): SMTP greeting failure: 421 SMTP connection broken (reply)Порты настроены правильно, не установлено SSL-шифрование для smtp.
В паролях для почты не использовать спецсимволы, пример из опыта: в пароле к почте был символ "+", пока из пароля не убрали, соединение не происходило! Система выдавала ошибку: Ошибка при вызове метода контекста (Подключиться): Can not authenticate to SMTP server: 535 5.7.8 Error: authentication failed: Invalid user or password!
Разработчики 1С вносят фунционал в рабочие конфигурации, например: УТ 10.3.30.1 от 26.09.2014, описание обновления: В справочник "Учетные записи электронной почты" добавлены реквизиты "Использовать защищенную версию протокола SMTP" и "Использовать защищенную версию протокола POP3". При установке этих реквизитов предоставляется возможность подключаться к почтовым серверам через безопасное соединение (SSL). Реквизиты доступны при использовании версии платформы не ниже 8.3.1.
P.S.: Возможно еще использование дополнительной программы stunnel. Но мне этот вариант меньше понравился. Т.к. клиенту не хотелось зависеть от программиста каждый раз, когда появляется новая почта или рабочее место, а чтобы с
Журавлев А.С. (Сайт www.azhur-c.ru)