Как в программе 1С:Зарплата и Управление Персоналом поменять подписанта?
Для изменения подписанта в программе 1С:ЗУП необходимо провести следующие действия: Организации - ответственные лица - добавить нового (дата с какого).
При проверке отчетности выдает сообщение: Не задана фамилия подписанта и имя подписанта:
Расчет по страховым взносам за 1 квартал 2017 г. (Первичный. ИФНС: 7715) Не задана фамилия подписанта.
Решение:
Открыть данные организации:
В регистрации в налоговом органе должно быть указано кто подписывает: Руководитель и Представитель
Далее на Закладке Учетная политика и другие настройки - Ответственные лица организации
И на начало периода заполнить ответственных лиц.
Заполняйте отчет - все появится!
Внимание! встречались случаи когда подписант не заполнялся в отчете, нужно создать новый отчет за этот период!
Итак, устанавливаем минимальный CentOS, настраиваем имена хостов, DNSы и сетевые подключения и приступаем собственно к установке серверных компонентов.
1. Установка Postgre SQL server
Обновление от 03-ноя-2016: в последних версиях CentOS (у меня сегодня был 7.2.1511) отсутствует поддержка libtermcap (и как-то "иначе" реализована libreadline), из-за чего сборки с сайта 1С не устанавливаются - решил поставить сборку от Postgres Professionals https://postgrespro.ru/products/1c_build - вроде работает, но о стабильности и производительности пока судить рано. Так что у кого проблемы с libtermcap.so.2() и/ли libreadline.so.5() при установке PostgreSQL с патчами 1С, можете попробовать этот альтернативный вариант.
Для установки использовался рекомендованный (адаптированный) 1С дистрибутив, для чего потребуется скачать его из раздела поддержки пользователей сайта 1С. В моём случае это был "Дистрибутив СУБД PostgreSQL для Linux x86 (64-bit) одним архивом (RPM)", который я сохранил в /root/temp. Распаковываем архив:
[root@vm-sql01 temp]# tar -vxf postgresql-9.2.1-1.1C_x86_64_rpm.tar.gz
Все недостающие зависимости (пакеты) будут установлены в процессе установки этих rpm, хотя на сайте 1С рекомендуют предварительно установить пакеты readline, libtermcap, krb5-libs и openssl, но в моём случае они либо уже были установлены, либо не были обнаружены в репозиториях.
2. Первый запуск Postgre SQL server
В отличии от сценариев установки большинства знакомых мне sql-серверов, postgres требует предварительной инициализации перед запуском, для чего существует два пути - первый, правильный:
[root@vm-sql01 pgsql]# su postgres -c '/usr/pgsql-9.2/bin/initdb -D /var/lib/pgsql/9.2/data --locale=ru_RU.UTF-8'
Файлы, относящиеся к этой СУБД, будут принадлежать пользователю "postgres".
От его имени также будет запускаться процесс сервера.
Кластер баз данных будет инициализирован с локалью "ru_RU.UTF-8".
Кодировка БД по умолчанию, выбранная в соответствии с настройками: "UTF8".
Выбрана конфигурация текстового поиска по умолчанию "russian".
исправление прав для существующего каталога /var/lib/pgsql/9.2/data... ок
создание подкаталогов... ок
выбирается значение max_connections... 100
выбирается значение shared_buffers... 32MB
создание конфигурационных файлов... ок
создание базы template1 в /var/lib/pgsql/9.2/data/base/1... ок
инициализация pg_authid... ок
инициализация зависимостей... ок
создание системных представлений... ок
загрузка описаний системных объектов... ок
создание правил сортировки... ок
создание преобразований... ок
создание словарей... ок
установка прав для встроенных объектов... ок
создание информационной схемы... ок
загрузка серверного языка PL/pgSQL... ок
очистка базы данных template1... ок
копирование template1 в template0... ок
копирование template1 в postgres... ок
ВНИМАНИЕ: используется проверка подлинности "trust" для локальных подключений.
Другой метод можно выбрать, отредактировав pg_hba.conf или используя ключи -A,
--auth-local или --auth-host при следующем выполнении initdb.
Готово. Теперь вы можете запустить сервер баз данных:
Или второй, более простой, но не всегда дающий необходимый результат (зависит от региональных настроек сервера, но у меня иногда приводивший к установке базы данных без поддержки необходимого collation ru_RU.UTF-8):
[root@vm-sql01 pgsql]# service postgresql-9.2 initdb
Инициализируется база данных: [ OK ]
[root@vm-sql01 pgsql]#
В результате была создана структура базы данных (с настройками) в /var/lib/pgsql/9.2/data. Хочу обратить особое внимание на конструкцию --locale=ru_RU.UTF-8, которую необходимо указать при инициализации, иначе сервер может быть инициализирован с неверным набором языковых параметров, что в конечном итоге приведёт к сообщениям
Ошибка установки или изменения национальных настроек информационной базы
Порядок сортировки не поддерживается базой данных
по причине:
Порядок сортировки не поддерживается базой данных
при установке информационной базы. Теперь можно настраивать автоматический запуск sql-сервера и, собственно, запускать его:
[root@vm-sql01 temp]# chkconfig postgresql-9.2 on
[root@vm-sql01 temp]# service postgresql-9.2 start
Запускается служба postgresql-9.2: [ OK ]
[root@vm-sql01 temp]#
Всё. Для локальных подключений сервер настроен. В моём случае сервер 1С и сервер SQL находятся на разных машинах, поэтому потребуется настроить и удалённые подключения с авторизацией.
В случае каких-то проблем, читаем содержимое файлов:
/var/lib/pgsql/9.2/pgstartup.log
/var/lib/pgsql/9.2/data/postgresql-*.log
Для повышения быстродействия документация PostgreSQL рекомендует как минимум унести журнал /var/lib/pgsql/9.2/data/pg_xlog на отдельный физический том и создать симлинк на него в исходном месте; из личных наблюдений - надо ещё и значительно увеличить размер используемой памяти... но необъятное не охватить, поэтому за статьями по оптимизации работы PostgreSQL для 1С предлагаю обращаться в поисковые системы, а оттуда - на профильные форумы.
3. Настройка пользователей (ролей) Postgre SQL server
Для управления PostgreSQL на начальном этапе потребуется сменить текущего пользователя на postgres и создать нового пользователя из командной строки:
[root@vm-sql01 temp]# su - postgres
-bash-4.1$ cd /usr/pgsql-9.2/bin
-bash-4.1$ createuser --interactive -P
Введите имя новой роли:server1c
Введите пароль для новой роли:
Повторите его:
Должна ли новая роль иметь полномочия суперпользователя? (y - да/n - нет) n
Новая роль должна иметь право создавать базы данных? (y - да/n - нет) y
Новая роль должна иметь право создавать другие роли? (y - да/n - нет) n
-bash-4.1$ exit
logout
[root@vm-sql01 temp]#
В принципе, для обслуживания полезно иметь пользователя с правами суперпользователя - создавать его можно тем же путём.
Теперь осталось разрешить удалённое подключение с авторизацией - для этого в файле /var/lib/pgsql/9.2/data/pg_hba.conf потребуется заменить значение ident на md5 в строке "host all all 0.0.0.0/0 md5" и перезапустить сервис.
Не следует забывать и про настройки iptables - для работы Postgre SQL необходимо открыть как минимум порт tcp 5432, хотя привычнее (да и проще) объявить сетевой интерфейс "внутренним" (разрешить все подключения на интерфейсе).
Для управления сервером потребуется pgAdmin, который можно установить из репозиториев используемого для административных целей линукса, либо скачать с сайта проекта.
4. Установка компонентов сервера 1С
Внимание!!! Для избежания проблем с зависимостями, желательно, чтобы разрядность сервера 1С совпадала с разрядностью используемого дистрибутива Linux! Иначе (если ставим 32-битный 1С на 64-битный Linux), при входе в базу, можно получить сообщение типа "Ошибка загрузки библиотеки libWand.so по причине:Библиотека не обнаружена. Часть функций будет недоступна." и клиенты не будут запускаться (хотя конфигуратор - будет). В принципе, я с этой проблемой справился на CentOS 7 (которой не выпускают больше в 32-битном исполнении) - просто поставил не только 'ImageMagick', но и 'ImageMagick.i686' (yum install ImageMagick.i686) - всё заработало (хоть и притянуло за собой гору зависимостей).
Первый шаг установки сервера 1С мало отличается от аналогичного этапа с SQL-сервером - распаковать скачанный дистрибутив сервера командой tar -vxf rpm64.tar.gz. В итоге получим файлы:
1C_Enterprise83-common-8.3.3-715.x86_64.rpm - основные файлы 1С (включая русский и английский интерфейсы)
1C_Enterprise83-common-nls-8.3.3-715.x86_64.rpm - дополнительные языковые модули
Настраиваем автоматический запуск демона и стартуем его:
[root@vh-1c83 temp]# chkconfig srv1cv83 on
[root@vh-1c83 temp]# service srv1cv83 start
Starting 1C:Enterprise 8.3 server: Error: service failed to start!
FAILED
[root@vh-1c83 temp]# service srv1cv83 start
Starting 1C:Enterprise 8.3 server: OK
[root@vh-1c83 temp]#
Хочу обратить внимание - если сразу после установки сервис (как в приведённом примере) не стартовал, а при второй попытке старта он запустился, скорее всего не настроен DNS - об этом чуть ниже. Если верить информации с многочисленных форумов, то наш сервер уже готов обслуживать до 12 клиентов. Для работы большего числа пользователей, необходимо установить лицензию сервера - либо в виде USB HASP и драйвера, либо в виде электронной лицензии. Про установку аппаратных ключей я уже писал, а установка программных лицензий достаточно проста: запускаем конфигуратор (с клиентской машины; кластер уже должен быть настроен и должна быть информационная база), вызываем "Сервис" - "Получение лицензии", вводим номер комплекта (с коробки или "Регистрационный номер" с карточки из конверта "Пинкоды программной лицензии") и пин-код (с той самой карточки из конверта), ставим галочку "Установка на сервер", вводим имя сервера в соответствующем поле, нажимаем "Далее", говорим, что это - "Первый запуск", заполняем форму "Владелец лицензии" (к стати, я не понял что писать в полях "Фамилия", "Имя", "Отчество" - то ли ответственного за эксплуатацию, то ли генерального директора - оставил поля пустыми, и оно получило лицензию, не ругнувшись), "Далее", "Автоматически" - профит! в /var/1C/licenses на сервере появился файлик XXXXXXXXXXXXXX.lic и серверу "стало хорошо" (если это была многопользовательская лицензия, то клиентам тоже "станет хорошо", т.к. они будут получать лицензии на сервере).
Для работы с графическими объектами и экспорта в xls, могут потребоваться дополнительные пакеты: ImageMagick, freetype (входит в зависимости ImageMagick), libgsf (входит в зависимости ImageMagick), corefonts (отсутствует в репозитариях CentOS - см. раздел 6); для "ТАКСИ" и "Управляемого приложения" они необходимы, для классического толстого клиента вроде бы не особо нужны, но 1С всё равно ругается на их отсутствие, хоть и работает.
По умолчанию сервер 1С слушает порт tcp 1541(1540) и для соединений использует диапазон портов 1560-1691.
5. Настройка экземпляра (кластера) сервера 1С
Информации о наличии оснастки управления сервером 1С для Linux мне не попадалось, так что для управления сервером будем использовать традиционную оснастку mmc для Windows "Администрирование серверов 1С:Предприятия", которую следует поставить из дистрибутива технологической платформы для Windows.
В этом месте на тестовом сервере возникли трудности - кластер по умолчанию отсутствовал, а при попытке создания нового кластера, ragent аварийно завершал работу с сообщением Sep 3 21:29:04 vh-1c83 kernel: ragent[1879]: segfault at 8 ip 00007f56473c9fd4 sp 00007f563b7b14a0 error 4 in rserver.so[7f56472db000+70e000]... странно, но если верить форумам, на CentOS у многих сервер 1С 8.3 ставится некорректно - не создаётся начальная конфигурация, включающая "Кластер по умолчанию". Краткий анализ ситуации выявил, что настройки кластера по умолчанию не были сгенерированы полностью и не попали в /home/usr1cv8/.1cv8/1C/1cv8/.
При попытке подложить файлы с рабочего сервера на неудачный, сервис 1С не запускается абсолютно без каких-либо диагностических сообщений - подобное поведение я видел при проблемах (неверных контекстах) SELinux, но в данном случае никаких отказов в audit.log не обнаружилось.
В результате детального изучения проблемы с применением strace удалось выяснить, что агент сервера при запуске ищет настройки по пути ~/.1cv8/1C/1cv8/ (в домашнем каталоге запустившего пользователя) и если не находит, пытается создать настройки кластера по умолчанию, для чего ему нужно имя хоста (выяснено экспериментально), и если верить "Руководству администратора", нужен корректно работающий DNS; экспериментально же был установлен факт, что сначала ragent читает файл /etc/hosts, затем обращается к DNS-серверу, а затем вызывает uname и снова лезет в hosts и к DNS и если не находит сопоставления, аварийно завершается. Итак, для нормального запуска потребуется полноценная и правильно настроенная сетевая инфраструктура, ну а в отсутствии работающего DNS достаточно дописать строчку в /etc/hosts и привести его примерно к такому виду:
За дальнейшими инструкциями пока отсылаю к своей статье про 8.2 - принципиальных отличий пока нет. Единственное замечание - при создании новой информационной базы, если указывать пользователя подключения к базе данных не с правами суперпользователя (а с набором прав из пункта 3), информационная база не создавалась, а в /var/lib/pgsql/9.2/data/pg_log/postgresql-Xxx.log наблюдались сообщения:
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: нет доступа к языку c
ОПЕРАТОР: CREATE OR REPLACE FUNCTION plpgsql_call_handler() RETURNS language_handler AS '$libdir/plpgsql' LANGUAGE C
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: ошибка синтаксиса (примерное положение: "application") в символе 24
ОПЕРАТОР: lock table pg_class in application share mode
ПРЕДУПРЕЖДЕНИЕ: нет незавершённой транзакции
ОШИБКА: тип "mvarchar" не существует в символе 31
ОПЕРАТОР: create table Config (FileName mvarchar(128) not null, Creation timestamp not null, Modified timestamp not null, Attributes int not null, DataSize int8 not null, BinaryData bytea not null, PartNo int not null, PRIMARY KEY (FileName, PartNo))
ОШИБКА: нет прав для изменения параметра "lc_messages"
ОПЕРАТОР: SET lc_messages to 'en_US.UTF-8';
ОШИБКА: нет доступа к языку c
ОПЕРАТОР: CREATE OR REPLACE FUNCTION plpgsql_call_handler() RETURNS language_handler AS '$libdir/plpgsql' LANGUAGE C
После подключения с учётными данными суперпользователя БД, сообщения изменились на англоязычные и проблемы исчезли. Судя по всему, если на сервере установлен язык по умолчанию en_US, данного казуса не случится, но это - не проверенная информация, а лишь предположение, сделанное по прочтении чужой статьи про 8.1 и праздных раздумий =)
Ещё одна странность - если создать пустую SQL базу не из шаблона1 (см. официальную документацию по 1С), и попытаться ей указать на этапе создания ИБ, то всё равно получим сообщение "ОШИБКА: тип "mvarchar" не существует (символ 31)"/"ERROR: type "mvarchar" does not exist at character 31", но мне так и не удалось создать из требуемого шаблона БД - валились разные ошибки, но если пользователя sql, от которого создаётся ИБ временно повысить до суперпользователя с правом создания БД, и указать создание базы данных в случае её отсутствия, то всё получается в лучшем виде, так что на этапе первичной настройки, видимо, придётся повышать пользователя до супер...
Что порадовало - теперь в 1С можно работать непосредственно из Linux, что актуально для компаний, использующих его как основную ОС в корпоративной сети (я сейчас работаю как раз в такой компании); из неожиданностей - что при установке клиента 1С, он заявляет о зависимости от сервера и требует его установки, но потом ставится, прописывает значки запуска в "Офис" - "Финансы" и работает довольно сносно (по ощущениям - чуть менее комфортно, чем 8.2 под Windows, но заметно приятнее, чем тот же 8.2 через WINE от Ethersoft).
6. Установка недостающих зависимостей
При запуске клиента к настроенному по данной инструкции серверу, появится сообщение "На сервере отсутствуют шрифты из состава Microsoft Core Fonts. Внешний вид приложения может отличаться от ожидаемого. Процедура установки описана в справочной системе..." - данное сообщение появляется достаточно редко (периодичность не выявил, но появляется точно не единожды, но и не при каждом запуске), и на работе особо не сказывается, но "для красоты" я решил пройтись по всей цепочке и поставить рекомендуемые пакеты. Всё, кроме "corefonts" поставилось из репозиториев (хотя в той самой "справочной системе" безбожно перепутаны регистры в названиях пакетов, из-за чего их идентификация оказалась весьма развлекательна), ну а шрифты я решил пересобрать (в соответствии с рекомендациями из "справочной системы") и результат прикрепляю к статье - msttcorefonts-2.5-1.noarch.rpm, заодно и сами шрифты (уже переименованные в нижний регистр, как происходит при сборке rpm рекомендованным скриптом) - msttcorefonts.tar.gz - содержимое этого архива рекомендуют распаковать в /home/usr1cv8/.fonts (не забыв сменить владельца как на папку, так и на файлы!), если нет возможности установить предложенный .rpm
Кроме "ImageMagick" и шрифтов, для возможности сохранения в табличные файлы (кроме xls - его я пока не заставил формироваться, хотя xlsx формируется), на клиенте должны быть установлены пакеты "libMagickWand5", "libgomp1", "liblcms2-2" и "libbz2-1" - на ряде машин они отсутствовали. При чём той же разрядности, что и сервер 1С (см. п. 4).
7. Настройка аппаратного hasp для виртуализированного сервера 1С (работающего на виртуальной машине KVM)
Не планировал описывать эту процедуру, но раз уж столкнулся с такой ситуацией, опишу... Итак, на этот раз я использовал драйвер от "Alladin Knowledge Systems USB HASP", предоставляемый компанией Sentinel - мне попались две версии:
2878061 сен 11 2012 aksusbd-2.0-1.i386.rpm - с сайта aladdin-rd.ru
3009880 авг 6 16:35 aksusbd-2.2-1.i386.rpm - с сайта safenet-inc.com
Можно воспользоваться драйвером эзерсофт - окончательный выбор следует делать из опыта практической эксплуатации.
Наиболее правильная (на мой взгляд) последовательность действий:
а) убедиться, что на хост-машине драйвер HASP не установлен;
б) установить выбранный драйвер USB HASP4 на виртуальном сервере;
в) выяснить список подключенных USB-устройств к хост-машине
[root@vh01 files]# ls -R /dev/bus/usb
/dev/bus/usb:
001
002
003
004
/dev/bus/usb/001:
001
002
/dev/bus/usb/002:
001
/dev/bus/usb/003:
001
/dev/bus/usb/004:
001
[root@vh01 files]#
г) подключить USB-HASP к хост-машине и выяснить адрес ключа:
[root@vh01 files]# ls -R /dev/bus/usb
/dev/bus/usb:
001
002
003
004
/dev/bus/usb/001:
001
002
/dev/bus/usb/002:
001
/dev/bus/usb/003:
001
/dev/bus/usb/004:
001
002 <==== это наш ключ - раньше его не было
[root@vh01 files]#
д) используя любой из способов (я использовал Virtual Manager на удалённой машине) добавить "USB Host Device" с найденным адресом (в моём примере - 004:002) к виртуальной машине 1С - может потребоваться выключение и включение машины (я добавлял устройство на выключенную машину).
Собственно, всё - на CentOS 6.4 x64/i686 всё работает (были багрепорты про CentOS 6.0/6.1, но вроде всё починили). Если при запуске виртуалки выдаётся сообщение о занятости устройства, скорее всего подцепился драйвер на хост-машине (так писали на паре форумов, хотя мне эту ситуацию воспроизвести не получилось - даже с установленным драйвером на сервере устройство мапилось корректно). Естественно, если переставить ключ в другой порт USB, придётся перенацеливать и виртуальную машину!
/home/usr1cv8/.1cv8/1C/1cv8/1cv8wsrv.lst - файл, в котором хранятся основные свойства сервера - например, учётные данные администратора сервера, зарегистрированые кластеры и т.п.
/home/usr1cv8/.1cv8/1C/1cv8/reg_1541/1CV8Clst.lst - файл, в котором хранятся свойства кластера по умолчанию
/opt/1C/v8.3/x86_64/ - (вместо "x86_64" может быть "i386" - в зависимости от архитектуры системы) исполняемые файлы и сопутствующие ресурсы сервера (и клиента) 1С
/var/1C/licenses - здесь лежат файлы электронных ключей лицензий
8. Настройка локального репозитория 1С для удобства обновления платформы
В процессе эксплуатации 1С нередко приходится обновлять платформу. Если всё установлено по приведённой выше инструкции, это вызывает определённые неудобства - надо останавливать сервис, удалять старые пакеты, ставить новые... не знаю - мне это ещё в винде надоело смертельно. Linux предлагает очень удобный механизм пакетного обновления из локального репозитория - всё, что нужно - это выбрать место, где будут лежать обновки: для одиночного сервера, к которому все ходят только через web-интерфейс, это может быть /root/repo (всё равно обновление под рутом идёт), ну а в общем случае - хоть /var/www/1c-repo - главное, чтобы все, кому он нужен, его видели. Далее надо установить пакет 'createrepo' (yum install createrepo) - за собой он притащит немало зависимостей, но не смертельно. Теперь командой 'createrepo /root/repo' (где "/root/repo" - выбранный путь хранения репозитория) создаём его "описание" и можно пользоваться.
Затем создаём файл описания нашего репозитория и помещаем его в каталог описаний репозиториев (для CentOS это /etc/yum.repos.d). Пример конфига локального файлового репозитария:
[root@1c yum.repos.d]# cat local-1c.repo
[local-1c]
name=1C Enterprise
#baseurl=http://inhost.firm.lan/repo
baseurl=file:///root/repo
gpgcheck=0
enabled=1
По-моему, разъяснять что за что отвечает, особого смысла нет. Единственное, что важно - сразу yum его может не увидеть - в этой ситуации поможет очистка его кэшей (yum clean all).
Всё. Теперь если надо обновиться, то помещаем новые файлы дистрибутива 1С рядом со старыми, повторяем 'createrepo /root/repo' вызываем 'yum update' - и всё - платформа пошла обновляться! Естественно, за сохранностью и защищённостью своего репозитория надо следить, так как GPG у нас выключен, и это всё же дыра в безопасности, хоть и не особо толстая...
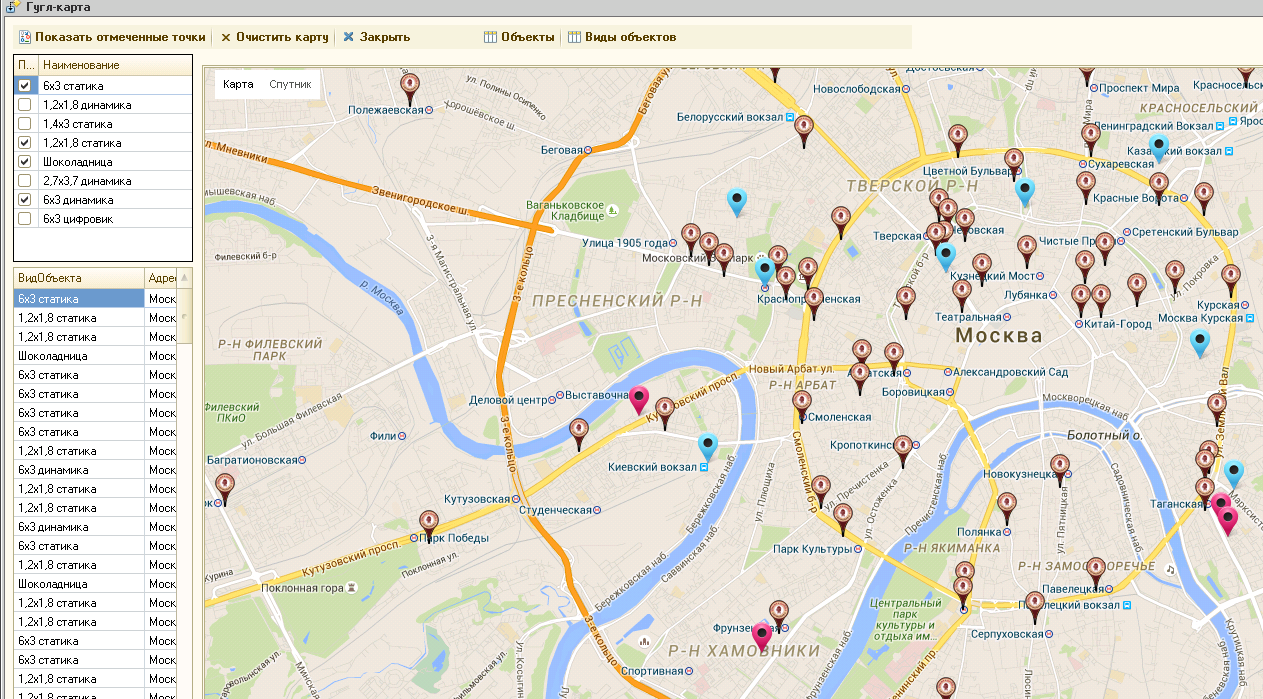
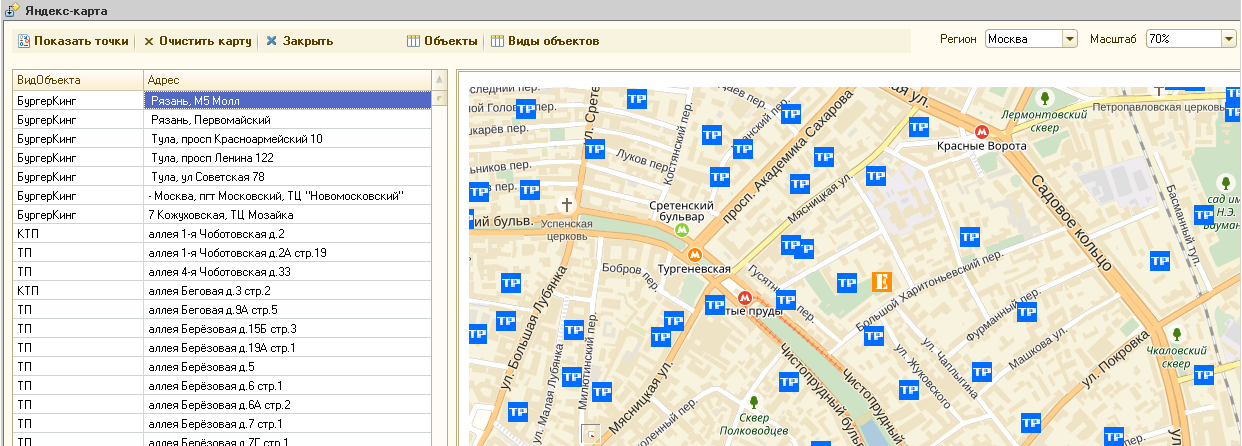
В отличие от яндекс карт в GMaps можно использовать панорамы - за что им большой плюс! Надеюсь в яндексе прочитают этот пост и тоже когда-нибудь это сделают!
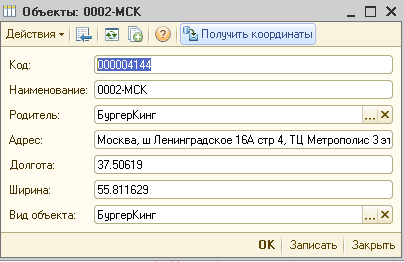
Для клиента нужно было сделать вывод объектов на карту
Недавно, мой постоянный клиент решил проводить маркетинговые исследования по изменению цен на товары у конкурентов... и эти данные захотел использовать в 1С в связке с его прайс-листом + куча отчетов с графиками и процентным отклонением от цен основного конкурента
В результате этого, была написана обработка собирающая данные со страниц разных сайтов. Из целей конфиденциальности - сайты раскрывать не буду...
Вид обработки загрузки данных с сайта в 1С
Ниже код загрузки данных со страницы сайта, смысл такой :
в функция передается адрес страницы сайта
полученный текст страницы обрабатывается, удаляются теги
из полученного текста формируется ТЗ с данными
По названию ищется поставщик из вспомогательного справочника Справочники.Pr_Поставщики.НайтиПоНаименованию(, если нет - создается
на выходе ТЗ с данными
В коде используется вспомогательная функция ПолучитьМассивИзСтрокиСРазделителем
Конечно, перед тем как мы начали это делать - прошерстили интернет и нашли несколько решений , вот они:
В этой статье я постараюсь описать процесс парсинга сайтов средствами 1С с примером.
Это статья не является инструкцией к применению, а лишь демонстрирует возможности 1С.
Что мы имеем? 1. Сайт в интернете, на котором располагается список товаров. В моем случае – это интернет магазин салона «Связной»
2. Понимание основ сайтостроения… хотя бы знание HTML тегов
3. Умение кодить в 1С 8
Для начала парсинга стоит определиться с тем что мы хотим спарсить и какая у нас будет иерархия. В моем случае это категория сотовых телефонов. Верхний уровень иерархии будет производители. Почему именно так? Потомы что я так захотел. Вы же вправе использовать любую иерархию.
Далее нам будут интересны такие поля как: Наименование, Цена, Картинка и Описание... ну и пожалую захватим операционную систему, чтобы пример получился более наглядным.
1. Создаем внешнюю обработку. Те, кто не знают как это сделать - дальше могут не читать
2. Создаем форму обработки с командной панелью снизу и сверху (они могут быть полезными)
3. Размещаем на ней Панель и обзываем первую страницу "СамСайт"
4. Кладем на страницу "СамСайт" ПолеHTMLДокумента и обзываем его к примеру "Сайт"
5. Переименовываем кнопку "Выполнить", которая находится на нижней панели в "Загрузить сайт"
6. Описываем процедуру нажатия на эту кнопку так:
7. Проверяем работу нашей обработки. У меня появился сайт связного. А у Вас?
Дальше сложнее. Все еще хочешь парсить сайты? Тогда читай:
Сам парсинг сайта заключается в обходе всех элементов загруженной страницы, выдергивания необходимой информации и запихивания их в табличную часть. Для этого:
1. Создадим табличную часть "Производители" с реквизитами "Отметка" (Булево), "Наименование" (Строка 100) и "Ссылка" (Строка 300).
2. Добавляем еще одну страницу на панели и обзываем ее "Производители"
3. Размещаем на этой странице одноименную табличную часть
4. Добавляем на нижней панели кнопку "Заполнить производителей" с кодом:
Здесь напрашиваются небольшие пояснения:
tagName - имя HTML тега в HTML документе
nextSubling - следующий элемент HTML документа от текущего
children - список дочерних элементов
firstChild - первый дочерний элемент от текущего
5. Проверям. При проверке важно, находиться на странице "СамСайт", чтобы заполнять производителей
Производители заполнены. Теперь к самим телефонам
1. Создаем табличную часть "Товары" с реквизитами "Производитель" (Строка 100), "Наименование" (Строка 100), "Цена" (Число 10,2), "Картинка" (Строка 300), "Описание" (Строка Неограниченная), "ОС" (строка 100), "Ссылка" (Строка,300)
2. Добавляем еще одну страницу на панели и обзываем ее "Товары"
3. Размещаем на этой странице одноименную табличную часть
4. Добавляем на нижней панели кнопку "Заполнить товары" с кодом:
5. Создаем форму обработки "ФормаТоваров"
6. Кладем на "ФормаТоваров" ПолеHTMLДокумента и называем его "Сайт"
7. На событие ДкументСформирован у ПоляHTMLДокумента пишем код:
8. Создаем переменную в модуле формы
перем ТекущийПроизводитель Экспорт;
9. Создаем процедуру ГрузимТовары():
10. Проверям. Все работает.
Дело осталось за "операционной системой" и еще надо загрузить картинки. Давайте по порядку. Чтобы получить "ОС" нам надо открыть этот товар и считать "ОС" оттуда. Для этого делаем следующее:
1. Добавляем на нижней панели кнопку "Доп Инфо" с кодом:
2. Создаем форму обработки "ФормаДопИнфо"
3. Кладем на "ФормаДопИнфо" ПолеHTMLДокумента и называем его "Сайт"
4. На событие ДкументСформирован у ПоляHTMLДокумента пишем код:
5. Создаем переменную в модуле формы
перем ТекущийТовар Экспорт;
6. Создаем процедуру ГрузимДопИнфо():
7. Проверяем и переходим к последнему пункту
Заметили как похожи две последние инструкции? То-то же. Стремился к универсальности. Ну и наконец последний этап - Сохраним все изображения к примеру на диск "С" в папку "связной". Поехали
1. Добавляем на нижней панели кнопку "Сохранить Картинки" с кодом:
2. Добавляем функцию СохранитьКартинкуСайта:
На этом наша эпопея с парсингом закончена. Это всего лишь пример того, как это можно сделать. Приложив сюда немного своего кода - можно сделать парсер для любого сайта. Скачивать файлы может только зарегистрированный пользователь! Имея парсер 1С - я могу спарсить все, кроме этого парсера. Имя два парсера 1С - я могу спарсить все
Автор: opx
Часто при ведении учета в различных конфигурациях 1с возникает необходимость выполнения обмена данных. Для решения этой задачи принято использовать Универсальный обмен данными XML или другие внешние обработки, общим у которых является использование текстовых файлов посредников.
Я предлагаю использовать Web-сервисы 1с. В чем необходимость обмена: Обмен данными между базами требуется для исключения дублирующих вводов одних и тех же данных в различных учетных системах. В чем необходимость обмена в режиме online: Обмен в онлайн режиме требуется когда функции учета комплекса учетных систем выполняются в разных учетных системах.
1. Например компания использует: CRM систему учета, для ведения учета взаимоотношений с клиентами; БП 2.0 для ведения взаиморасчетов с клиентами в разрезе счетов; Счета выставляемые клиентам создаются в торговой базе, а оформление заказов поставщикам исходя из потребности клиентов в базе ориентированной на работу с пайсами поставщиков. При таком разделенном построении учета, для выставления счета в одной из баз к примеру требуется завести карточку клиента в другой базе с тем чтобы данные о контрагенте так же были доступны в базе со счетами.
2. Помимо синхронизации первичных данных, может возникнуть необходимость построения сводного отчета по данным из нескольких баз, что тоже потребует обращения к внешним данным в online режиме.
Вариант автоматизации данного процесса с использованием файлов обмена, потребует подключения обработчика ожиданий, что сможет обеспечить обмен данными только с установленной задержкой времени обмена, кроме того любая обработка ожидания будет не эффективно использовать машинное время.
Обращение к Web сервисам, возможно при возникновении любых событий (ПриЗаписи, ПриПроведении, при нажатии кнопки и т.д.). при этом не возникнет ни какой задержки реакции информационной базы к которой происходит обращение, (в отличие от запуска еще одного приложения 1с в качестве com объекта).
Итак рассмотрим вариант реализации синхронизации элементов справочников, начнем с наиболее простого со справочника "Товары" в базах "Продажи" и "Закупки". Синхронизация для начала будет односторонней, предположим что перечень товаров заводится в базе "Продажи", а в "Закупки" он передается.
Что нам потребуется для того чтобы задача возникла и могла быть решена.
1. Сервер 1с, с установленной web компонентой;
2. веб-сервер (например IIS 6.0);
3. Две или более конфигурации учетных систем.
Что нам потребуется для решения задачи.
1. Создадим в базе "Закупки" Web-сервис "Синхронизация", и добавим ему Операцию "СинхронизироватьТовар", со строковыми параметрами.
1. "GuidТовара" - сюда будем передавать уникальный идентификатор товара присвоенный в базе Продаж.
2. "GuidРодителя" - уникальный идентификатор родителя данного товара.
3. "стрСтруктураРеквизитов" - Структура реквизитов товара в виде примитивных типов (число,строка,дата,булево) преобразованная в строку.
4. "этоГруппа" - реквизит котрый позволит нам не раскрывая всей структуры реквизитов товара узнатья явлется ли товар группой и соответственно его обработать.
5. "стрТаблицаЕденицИзмерения" - Таблица содержащая описание доступных единиц измерения для товара
Далее потребуется опубликовать данный сервис на веб сервере. для этого нужно будет создать текстовый файл "wssinhron.1cws", в каталоге сайта опубликованном на веб сервере. Библиотека wsisapi.dll, должна быть подключена. Проще всего корректную настройку работы веб сервера с 1с можно провести опубликовав веб приложение через конфигуратор Администрирование->"Публикация на веб сервере". Единственным минусом является, то что в версии 8.2 файлы веб сервисов *.1cws, сами не создаются. Возможно просто мне не хватает знаний по этому вопросу но для публикации веб сервисов я пользуюсь блокнотом.
Также следует учесть что на серверах 64x следует использовать wsisapi.dll из поставки 1с 64x, даже если сам сервер 1с у вас 86x.
Итак создаем файл "wssinhron.1cws" с текстом.
{Название вашего сервера 1с}";Ref="{Назваение базы. у нас это "Market"}";"/>
Далее перейдем в модуль обработки нашего Сервиса, для наглядности я приведу пример кода своей разработки
Теперь, как вызвать веб сервис не зациклив при этом систему.
в нашем справонике "Товары" в базах "Продажи" и "Закупки" нам потребуются служебные реквизиты. 1. "GUIDтовара" - строковый реквизит (50)
2. "ВремяСинхронизации" - Реквизит с типом Дата и Время
3. "Синхронизирован" - тип булево.
В модуль объекта Справочника добавим предопределенные обработчики событий "ПередЗаписью()", "ПриЗаписи()" функцию "Синхронизация()" и общую переменную "передавать", и под текстом модуля присвоим этой переменной значение Истина. Перем передавать Экспорт;
Процедура ПередЗаписью(Отказ)
Процедура ПриЗаписи(Отказ)
Функция Синхронизация()
передавать = истина;
Таким образом получится что при любой инициализации модуля наша переменная всегда имеет значение истина.
Рассмотрим наши процедуры:
Таким образом остается добавить в событие формы элемента "ПриЗаписи()"
И мы сможем записывать наш элемент сколько угодно раз не вызывая зацикливания.
Для варианта двусторонней синхронизации, (когда элемент справочника может редактироваться в обоих базах) нам потребуется скопировать наш веб сервис из базы закупок в базу продаж переименовав имя файла публикации и URI пространство имен и внести соответствующие изменения в вызов веб сервиса из базы продаж в базу закупок и опубликовать его. Важно: При успешном срабатывание вызванного сервиса из базы "Продажи", в качестве результата работы должен быть возвращен уникальный идентификатор элемента справочника из базы "Продажи". Данный результат необходимо будет присвоить соответсвующиму реквизиту справочника из базы закупок.
Аналогично приведенному примеру можно синхронизировать данные любого справочника или документа.
Построение сводных отчетов
Для получения сводного отчета нам также потребуется вызов веб сервиса из какой - либо базы. Данный веб сервис должен будет возвращать преобразованною в строку, таблицу с данными которые мы хотим использовать в нашем отчете (Например таблицу содержащую "Код товара" и "Актуальную цену поставщика на данный товар"). Далее можно преобразовать эту строку в таблицу и использовать в качестве вложенной временной таблицы любом запросе к базе "Продажи" с соединением по Коду. Исключением является использование данной таблицы в Построителе отчетов, для случая построителя нам понадобится создание, дополнительного справочника с предопределенным элементом и табличной частью, с реквизитами соответствующими полям таблицы.
Автор: allert73
Есть задача:
в элемент управления "Поле HTML документа" загружается некая web форма, на которой есть некий InputElement. Необходимо реализовать обработчик события onchange этого элемента.
Пытаюсь сделать так:
При проверке модуля возникает ошибка:
Переменная не определена (outMsgChange)
Толстый клиент (обычное приложение)
Есть какие-то варианты назначить для web контрола в качестве обработчика процедуру модуля?
Что-то аналогичное коду на C#:
this.FormClosed += new FormClosedEventHandler(Form1_FormClosed);
Пример использования СКД отчета для заполнения табличного документа.
Вызываем отчет “Маркетинговый план” сделаного на основе СКД.
Установка параметр “Вероятность”. И отбора по ключу “Основание.МВЗ.СПО”
Обработка Универсальный обмен данными в формате XML (обработка универсальныйобменданнымиxml)
Обработка "Универсальный обмен данными в формате XML" предназначена для загрузки и выгрузки данных в файл из любой конфигурации, реализованной на платформе 1С:Предприятие 8.
Режим работы
При использовании управляемой формы обработка имеет два режим работы:
1. На клиенте. При использовании этого режима файлы правил и загружаемых данных передаются с клиента на сервер, а файл выгружаемых данных передается с сервера на клиент. Пути к этим файлам, находящимся на клиенте, необходимо указывать в диалоговом окне непосредственно перед выполнением действия.
2. На сервере. В этом режиме файлы не передаются на клиентн и пути к ним необходимо указывать на сервере.
Примечание: Файл внешней обработки и файлы протоколов обмена всегда должны находиться на сервере вне зависимости от режима работы.
Выгрузка данных
Для осуществления выгрузки данных необходимо указать имя файла, в который будет осуществляться выгрузка данных и выбрать файл правил обмена. Правила обмена для любых конфигураций могут быть настроены в специализированной конфигурации "Конвертация данных, редакция 2".
Для выгрузки документов и записей независимых периодических регистров сведений необходимо указать период - "Дату начала" и "Дату окончания". Результирующий файл с выгруженными данными может быть сжат.
На закладке "Правила выгрузки данных" можно выбрать те типы объектов, которые должны выгружаться, настроить отборы для выборки объектов, либо указать узел обмена данными, для которого нужно выгружать данные.
На закладке "Параметры выгрузки" можно указать дополнительные параметры выгрузки данных.
На закладке "Комментарий" можно написать произвольный текст-комментарий, включаемый в файл обмена.
Загрузка данных
Для осуществления загрузки данных необходимо указать имя файла, из которого будет осуществляться загрузка данных.
Есть возможность настроить загрузку данных в транзакции. Для этого необходимо взвести флажок "Использовать транзакции" и указать количество элементов в одной транзакции при загрузке.
"Загружать данные в режиме обмена (ОбменДанными.Загрузка = Истина)" – если флаг установлен, то загрузка объектов будет выполнятся с установленным признаком загрузки. Это означает, что при записи объектов в базу данных будут отключены все платформенные и прикладные проверки. Исключение составляют документы, которые записываются в режиме проведения или отмены проведения. Проведение и отмена проведения документа выполняется всегда без установки режима загрузки, т.е. проверки будут выполняться.
Дополнительные настройки
Закладка служит для детальной настройки выгрузки и загрузки данных.
"Режим отладки" – флаг для задания режима отладки обмена. Если этот флаг установлен, то процесс обмена данными не будет остановлен при возникновении какой-либо ошибки. Обмен завершится до конца с выводом отладочных сообщений в файл протокола обмена. Этот режим рекомендуется использовать при отладке правил обмена.
"Вывод информационных сообщений в окно сообщений" – если флаг установлен, то в окно сообщений будет выводиться протокол процесса обмена данными.
"Количество обработанных объектов для обновления статуса" – параметр служит для определения количества обработанных элементов перед изменением строки состояние загрузки/выгрузки
"Настройки выгрузки данных" – позволяют определить количество элементов обрабатываемых в одной транзакции при выгрузке данных, выгружать и обрабатывать только те объекты, на которые есть права доступа, настроить тип изменения регистрации для выгруженных объектов через планы обмена.
"Использовать оптимизированный формат для обмена данными (V8 - V8, версия обработки не ниже 2.0.18)" – оптимизированный формат сообщения обмена предполагает наличие узла "ИнформацияОТипахДанных" в заголовке сообщения, в который выгружается информация о типах данных. Это позволяет ускорить процесс загрузки данных.
"Использовать транзакции при выгрузке для планов обмена" – флаг определяет режим использования транзакций при выгрузке данных при выборке изменений на узлах планов обмена. Если флаг установлен, то выгрузка данных будет выполняться в транзакции.
"Количество элементов в транзакции" – определяет максимальное число элементов данных, которые помещаются в сообщение в рамках одной транзакции базы данных. Если значение параметра равно 0 (значение по умолчанию), то все данные помещаются в рамках одной транзакции. Такой режим является рекомендуемым, так как гарантирует согласованность данных, помещаемых в сообщение. Но при создании сообщения в многопользовательском режиме могут быть конфликты блокировок между транзакцией, в которой данные помещаются в сообщение, и транзакциями, выполняемыми другими пользователями. Для снижения вероятности возникновения таких конфликтов можно задать значение этого параметра, отличное от значения по умолчанию. Чем меньше значение параметра, тем меньше вероятность конфликта блокировок, но выше вероятность помещения в сообщение несогласованных данных.
"Выгружать объекты на которые есть права доступа" – если флаг установлен, то выборка объектов информационной базы будет выполняться с учетом прав доступа текущего пользователя программы. Это предполагает использование литерала "РАЗРЕШЕННЫЕ" в тексте запроса для выборки данных.
"Автоматически удалять недопустимые символы из строк для записи в XML" – если флаг установлен, то при записи данных в сообщение обмена недопустимые символы будут удалены. Символы проверяются на соответствие рекомендации XML 1.0.
"Изменения регистрации для узлов обмена после выгрузки" – поле определяет режим работы с регистрацией изменений данных после завершения выгрузки данных. Возможные значения:
Не удалять регистрацию – после выгрузки данных регистрация изменений на узле удалена не будет.
Полностью удалить регистрацию для узла обмена – после выгрузки данных регистрация изменений на узле будет полностью удалена.
Удалить регистрацию только для выгруженных метаданных – после выгрузки данных регистрация изменений на узле будет удалена только для объектов метаданных, которые были указаны к выгрузке.
"Протокол обмена" – позволяет настроить вывод информационных сообщений в окно сообщений, ведение и запись в отдельный файл протокола обмена.
"Имя файла, протокола обмена" – имя файла для вывода протокола процесса обмена данными.
"Протокол загрузки (для COM - соединения)" – имя файла для вывода протокола процесса обмена данными в базе-приемнике при обмене через COM-соединение. Важно: путь к файлу должен быть доступен с компьютера, на котором установлена база-приемник.
"Дописывать данные в протокол обмена" – если флаг установлен, то содержимое файла протокола обмена сохраняется, если файл протокола уже существует.
"Вывод в протокол информационных сообщений" – если флаг установлен, то в протокол обмена будут выводиться сообщения информативного характера, помимо сообщений об ошибках обмена.
"Открывать файлы протоколов обмена после выполнения операций" – если флаг установлен, то после выполнения обмена данными файлы протоколов обмена будут автоматически открыты для просмотра.
Удаление данных
Закладка нужна только для разработчиков правил обмена. Позволяет удалять из информационной базы произвольные объекты.
Отладка выгрузки и загрузки данных
Обработка позволяет совершать отладку обработчиков событий и генерировать модуль отладки из файла-правил или файла-данных.
Включение режима отладки обработчиков выгрузки производится на закладке "Выгрузка данных" установкой флажка "Режим отладки обработчиков выгрузки". Соответственно, на закладке "Загрузка данных" включение режима отладки загрузки производится установкой флажка "Режим отладки обработчиков загрузки".
После установки режима отладки обработчиков станет доступной кнопка настройки отладки. По нажатию на эту кнопку откроется окно настройки.
Настройка отладки обработчиков выполняется в четыре шага:
Шаг 1: Выбор режима отладки алгоритмов
На первом шаге необходимо определиться с режимом отладки алгоритмов:
Без отладки алгоритмов
Вызывать алгоритмы как процедуры
Подставлять код алгоритмов по месту вызова
Первый режим удобно использовать, когда мы точно знаем, что ошибка в обработчике не связана с кодом какого-либо алгоритма. В этом режиме код алгоритмов не выгружается в модуль отладки. Алгоритмы выполняются в контексте оператора "Выполнить()" и их код недоступен для отладки.
Второй режим необходимо использовать в тех случаях, когда ошибка находится в коде алгоритма. При установке этого режима алгоритмы будут выгружены как отдельные процедуры. В момент вызова алгоритма из какого-либо обработчика происходит обращение к соответствующей процедуре обработки. Этот режим удобно использовать, когда для передачи параметров в алгоритмы используется глобальная переменная "Параметры". Ограничения использования этого режима в том, что при отладке в алгоритме недоступны локальные переменные обработчика, из которого он вызывается.
Третий режим отладки используется, как и во втором случае, при отладке кода алгоритмов и в тех случаях, при которых второй режим отладки не подходит. При установке этого режима алгоритмы будут выгружены как интегрированный код в обработчиках. Т.е. взамен оператора вызова алгоритма вставляется полный код алгоритма с учетом вложенных алгоритмов. В этом режиме нет ограничений на использование локальных переменных обработчика, однако есть ограничение при отладке алгоритмов с рекурсивным вызовом.
Шаг 2: Формирование модуля отладки
На втором шаге необходимо произвести выгрузку обработчиков нажатием на кнопку "Сформировать модуль отладки выгрузки (загрузки)". Сформированные обработчики и алгоритмы будут выведены в отдельное окно для просмотра. Содержимое модуля отладки необходимо скопировать в буфер обмена нажатием на кнопку "Копировать в буфер обмена".
Шаг 3: Создание внешней обработки
На этом шаге необходимо запустить конфигуратор и создать новую внешнюю обработку. В модуль обработки необходимо вставить содержимое буфера обмена (модуль отладки) и сохранить обработку под любым именем.
Шаг 4: Подключение внешней обработки
На четвертом, завершающем шаге, надо указать имя файла внешней обработки в поле ввода. При этом программа выполняет проверку по времени создания (обновления) файла обработки. Если обработка имеет более раннюю версию, чем версия файла модуля отладки, то будет выведено предупреждение и форма настройки закрыта не будет.
Примечание: Возможность отладки глобального обработчика конвертации "После загрузки правил обмена" не поддерживается.
Как задать отбор по Типу документа?
Как указать условие для отбора не определенного значения?
Как в языке запросов 1С отобрать не заполненное значение?
Какое условие указать в запросе после ключевого слова «ГДЕ», когда нужно сделать отбор по не заполненным полям?
Почему запрос может работать неоптимально:
1. в виртуальных таблицах не используются параметры
2. соединения с подзапросами, условия с подзапросами, вложенные подзапросы
3. соединения с виртуальными таблицами
4. наложение условий на неиндексированные поля
5. получение данных из составного типа через точку
6. использование вложенных подзапросов (с большой вложенностью)
Подробнее: 1. В виртуальных таблицах не используются параметры Рекомендация
Надо использовать по-максимуму параметры виртуальных таблиц (Остатки, Обороты, ОстаткиИОбороты) Объяснение
Сперва выбираются данные для виртуальных таблиц, а потом уже на них накладываются условия, соединения и т.д. Т.е. если сделать запрос:
То сперва выберется вся имеющаяся номенклатура со всеми остатками, а потом на неё наложится условие склада. Надо так:
2. Соединения с подзапросами, условия с подзапросами, вложенные подзапросы Рекомендация
Надо вообще стараться не использовать подзапросы, а переписать их во временные таблицы. Соединять следует только объекты метаданных или временные таблицы. Объяснение
Оптимизатор СУБД часто не может составить оптимальный план выполнения таких запросов. Проблема в определении алгоритма соединения, который зависит от количества записей в выборке. При использовании временных таблиц размер выбираемых таблиц известен заранее, поэтому СУБД легче составить оптимальный план выполнения. Но при этом появляются накладные расходы на создание временных таблиц.
3. Соединения с виртуальными таблицами Рекомендация
Перед соединениями с виртуальными таблицами их следует предварительно выбрать во временные и соединять уже с ними. Объяснение
Виртуальные таблицы часто содержатся в нескольких физических таблицах СУБД, в итоге для их выборки составляется подзапрос, а проблемы с ним расшифрованы в п.2.
4. Наложение условий на неидексированные поля Рекомендация
Для условий запросов должны существовать подходящие индексы.
При соединении с виртуальными таблицами, их необходимо проиндексировать по полям, участвующим в соединении. Объяснение
При отсутствии подходящего индекса СУБД будет сканировать всю таблицу для соединения по каждому полю.
5. Получение данных из составного типа через точку Рекомендация
В запросах использовать ВЫРАЗИТЬ(... КАК ...), в описании типов полей указывать только необходимые типы. Объяснение
При выполнении запроса для составного типа без ВЫРАЗИТЬ будет происходить соединение с таблицами всех объектов, входящих в составной тип.
Надумал когда-то задачу себе: выгрузить содержимое табличного документа в Google Document. Одним из вариантов использования данного функционала может быть выгрузка состояния заказов пользователей из базы в 1с в google spreadsheet. Если клиент знает адрес данного документа, то они могут ознакомиться с состоянием дел не звоня менеджеру. Может кто еще придумает варианты использования – пишите в комментарии, буду рад.
Последовательность выгрузки документа такова: сначала получаем список таблиц, которые есть у пользователя в системе Google Document. Затем после определения таблицы выгрузки пользователю предлагаем выбрать лист, в который будет выгружаться содержимое. Во время выбора всех этих параметров так же предоставляется возможность создания новых элементов (таблиц, листов). Уже после определения листа выгрузки обходим все ячейки документа и их содержимое переносим в таблицу на соответствующее место. Вопрос сохранения форматирования табличного документа в данной задаче не рассматривался.
Для написания функционала использовалась информация про google document API. Для того чтобы получить доступ к данным необходимо чтобы 1с сначала прошла аутентификацию. Про аутентификацию приложений можно почитать в соответствующем документе. Для того чтобы пройти аутентификацию мы должны сначала получить маркер, затем этот маркер прописывать каждый раз при обращении к серверу.
Функция получения маркера следующая:
Функция получения маркера в качестве входного параметра получает вид службы, для которой будет проходить аутентификация. Это очень важный момент. Например, полученный маркер для Календаря не даст возможности работать с документами.
Для получения списка таблиц отправляется GET запрос по адресу «https://spreadsheets.google.com/feeds/spreadsheets/private/full». В запросе параметр «Authorization» определяется значением полученного маркера аутентификации. В результате выполнения запроса в ResponseText мы получаем xml, который для удобство дальнейшего разбора перегоняется в ДеревоЗначений.Функция получения списка таблиц имеет следующий вид:
Теперь остановимся на самой выгрузке значения в ячейку google таблицы. Для определения значения в ячейке выполняется POST запрос по адресу листа таблицы, который пользователь определил до этого. Успешность выполнения обновления контролируется по значению Status, в случае удачного обновления он должен быть равен 201. Функция обновления значения ячейки на листе Google таблицы имеет следующий вид:
Алгоритм обработки выполняет запрос к регистру сведений "курсы валют" за определенный пользователем период. Полученные данные выборки в цикле выводятся в элемент экранной формы "диаграмма" в режиме построения графика. Для элемента управления "Диаграмма" на этапе конфигурирования был задан тип - График, и имя - "График Курсов". Это наиболее наглядный и простой пример работы с графиками в 1С 8.1.
Внешний вид и органы управления показаны на рисунке:
Алгоритм процедуры рисования графика:
- Очистить старые данные графика;
- Сформировать текст запроса;
- Установить значения периода выборки;
- Выполнить запрос;
- Подготовить структуру соответствия серий и валют, которые будут изображены на графике;
- В цикле заполнить значения точек графика для всех используемых валют;
- В цикле, используя ранее установленные значения графика для валют, добавить серию графика бивалютной корзины;
- Обновить данные графика курсы валют экранной формы;
Использование элемента Диаграмма в 1С
Алгоритм обработки использует в качестве параметра элемент НастройкаПериода, значения которого используются в запросе к регистру сведений "Курсы валют".
Исходный код:
Далее в процедуре "Нарисовать", осуществляющей вывод данных запроса в диаграмму экранной форме, обозначена структура для работы с валютами и ряд подготовительных действий. Переменная курсы будет использоваться для связи с элементом управления Диаграмма, расположенным на экранной форме. Перед работой будут очищены текущие данные диаграммы и отлючена перерисовка значений в момент нового формирования и насыщения данными. Структура "серии" потребуется для связи названия валюты (ключ) и серии (значение) диаграммы, как на моменте инициализации, так и при выводе данных. Так же при создании серий диаграммы производится отключение маркеров.
Далее необходимо выполнить запрос и перейти к формированию диаграммы. Следующая часть процедуры заполняет значение точек для серий диаграммы, добавленных в цикле инициализации серий графика. Если точек диаграммы не было создано ранее, они создается. Алгоритм рассчитан для работы с курсами валют в течении года, если нужен больший период механизм создания точек следует переделать либо в запросе, либо в данном цикле. Номер серии, используемый при выводе значения точки диаграммы, находится при помощи структуры ключ и значение по названию валюты, полученному для текущей строки выборки запроса.
Получение значения точки уже построенного графика в элементе диаграмма можно при помощи функции "ПолучитьЗначение". Для использования этой функции нужно знать серию и точку диаграммы. После вычисления значения графика бивалютной корзины диаграмму нужно обновить:
Данные курсов можно загрузить штатным загрузчиком 1С с сайта РБК, для этого можно воспользоваться справочником "Валюты" нажав пункт меню "Загрузить курсы":
При построении графика предполагается наличие в справочнике данных следующих валют: EUR, GBP, USD, Руб. После открытия формы для загрузки данных курсов валют нужно указать интервал требуемых данных - например с 2000 по 2010 год и нажать на кнопку "Заполнить", затем на кнопку "Загрузить". В данном примере курсы валют будут загружены с сайта РБК:
После добавления необходимого состава валют и загрузки их курсов по отношению к рублю за нужный период можно пользоваться построителем, текст которого приведен выше. Для ускорения вывода данных дополнительные проверки не вводились, по этому, если нет требуемых данных, внешняя обработка вызовет ошибку выполнения.
Сохранение диаграммы, графиков и гистограмм в виде картинки
Построенные в диаграмме графики можно сохранить средствами 1С в один из поддерживаемых форматов: BMP
EMF
GIF
Icon
JPEG
PNG
TIFF
WMF
Пример процедуры для экспорта диаграммы в графический формат:
 Не задана фамилия подписанта 1с 8.3 ЗУП, Как поменять подписанта?
Не задана фамилия подписанта 1с 8.3 ЗУП, Как поменять подписанта? 





.gif) , вот они:
, вот они:







