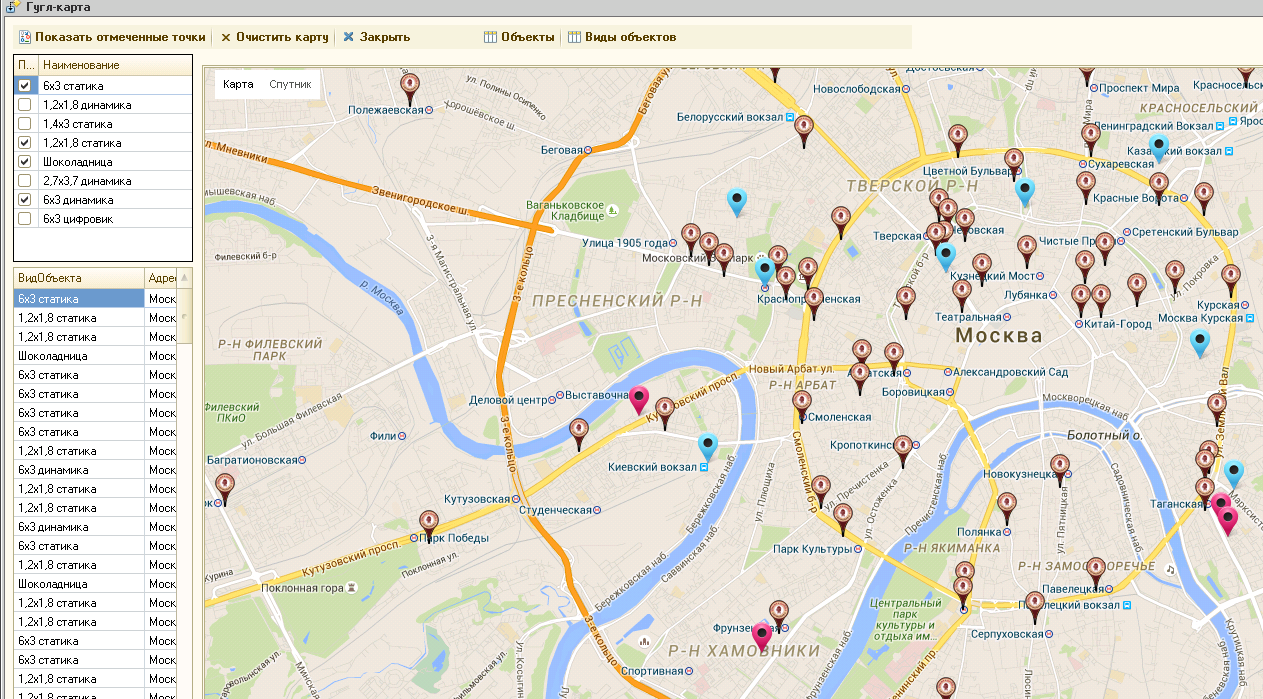
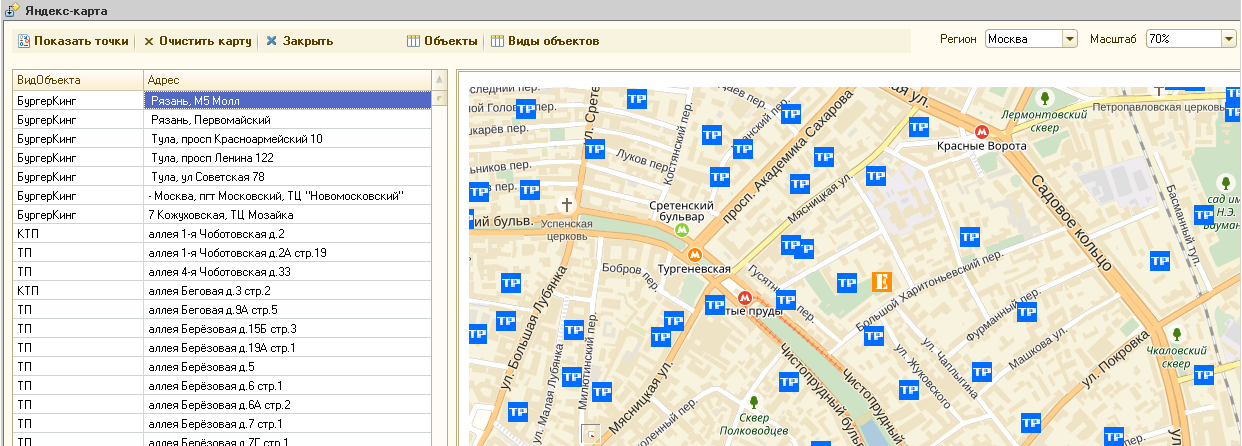
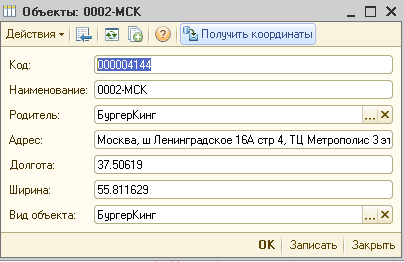
В отличие от яндекс карт в GMaps можно использовать панорамы - за что им большой плюс! Надеюсь в яндексе прочитают этот пост и тоже когда-нибудь это сделают!
Для клиента нужно было сделать вывод объектов на карту
Вам встретилось сообщение, содержащее строки: Microsoft OLE DB Provider for SQL Server: CREATE UNIQUE INDEX terminated because a duplicate key was found for index ID
или Cannot I_nsert duplicate key row in object
или Попытка вставки неуникального значения в уникальный индекс.
Варианты решения: 1. В SQL Server managment studio физически уничтожаем сбойный индекс (в моем случае это был индекс по таблице итогов регистра бухгалтерии). В 1С распроводим сбойные документы. В режиме тестирования и исправления ставим галки реиндексация таблиц + пересчет итогов. 1С воссоздает индекс уже без ошибки. Проводим ранее сбоившие документы. 2. 1) С помощью Management Studio 2005 сгенерировала create-скрипт на создание индекса, который глючил, и сохранила в файлик.
2) Вручную убила косячный индекс из таблицы _AccumRgTn19455
3) Запустила запрос вида
После того, как индекс был убит, у меня отобразилось 15 дублирующихся записей, хотя до выполнения п.2 запрос ничего не возвращал.
4) Просмотрела все записи и вручную почистила дубликаты. На самом деле, я ещё пользовалась обработкой "Структура отчёта", чтобы понять, с чем вообще имею дело. Оказалось, что в таблице _AccumRgTn19455 хранится регистр накопления "Выпуск продукции (налоговый учёт)". Я ещё поковырялась sql-запросами, выявила 15 неуникальных документов и после окончания всех действ проверила в 1С, что эти документы проводятся нормально, без ошибок. Просто так чистить таблицы наобум, конечно, не стоит: важно понимать, что чистится и чем это может обернуться.
5) Запустила запрос на создание индекса, который был сохранён в файле.
6) Перевела базу в однопользовательский режим и запустила dbcc checkdb - на этот раз ни одной ошибки не выдалось.
7) Перевела базу обратно в однопользовательский режим.
Всё... проблема побеждена. Ну ещё в 1С запустила "Тестирование и исправление", там тоже всё прошло нормально, перестало ругаться на неуникальный индекс. 3. Если неуникальность заключается в датах с нулевыми значениями, то проблема решается созданием базы с параметром смещения равным 2000.
1. Если проблема загрузкой базы данных, то:
1.1. Если Вы делаете загрузку (используйете dt-файл) в базу MS SQL Server, то при создании базы перед загрузкой укажите смещение дат - 2000.
Если уже база создана со смещением 0, то создайте новую с 2000.
1.2. Если есть возможность в файловом варианте работать с базой, то выполните Тестирование и Исправление, а также Конфигурация - Проверка конфигурации - Проверка логической целостности конфигурации + Поиск некорректных ссылок.
1.3. Если нет файлового варианта, попробуйте загрузить из DT в клиент-серверный вариант с DB2 (который менее требователен к уникальности), и затем выполнить Тестирование и Исправление, а также Конфигурация - Проверка конфигурации - Проверка логической целостности конфигурации + Поиск некорректных ссылок.
1.4. Для локализации проблемы можно определить данные объекта, загрузка которого не удалась. Для этого надо включить во время загрузки трассировку в утилите Profiler или включите запись в технологический журнал событий DBMSSQL и EXCP.
2. Если проблема неуникальности проявляется во время работы пользователей:
2.1. Найти с помощью метода пункта 1.4 проблемный запрос.
2.1.2. Иногда ошибка возникает во время исполнения запросов, например:
Данная ошибка возникает из-за того что в модуле регистра накопления "Рабочее время работников организаций" в процедуре "ЗарегистрироватьПерерасчеты" в запросе не стоит служебное слово "РАЗЛИЧНЫЕ".
В последних выпущенных релизах ЗУП и УПП ошибка не возникает, т.к. там стоит "РАЗЛИЧНЫЕ".
2.2. После нахождения проблемного индекса из предыдущего пункта, необходимо найти неуникальную запись.
2.2.1. «Рыба» скрипта для определения неуникальных записей с помощью SQL:
2.2.2 Пример. Индекс в ошибке называется "_Document140_VT1385_IntKeyIndNG".
Перечень полей таблицы: _Document140_IDRRef, _KeyField, _LineNo1386, _Fld1387, _Fld1388, _Fld1389, _Fld1390, _Fld1391RRef, _Fld1392RRef, _Fld1393_TYPE, _Fld1393_RTRef, _Fld1393_RRRef, _Fld1394,_Fld1395, _Fld1396RRef, _Fld1397, _Fld1398, _Fld1399RRef, _Fld22260_TYPE, _Fld22260_RTRef, _Fld22260_RRRef, _Fld22261_TYPE, _Fld22261_RTRef, _Fld22261_RRRef
Перед выполнением приведенной ниже процедуры сделайте резервную копию базы данных.
Выполните в MS SQL Server Query Analizer:
С его помощью узнайте значения колонок _Document140_IDRRef, _KeyField, дублирующихся записей (id, key).
При помощи запроса:
посмотрите на значения других колонок дублирующихся записей.
Если обе записи имеют осмысленные значения и эти значения разные, то исправьте значение _KeyField на уникальное. Для этого определите максимальное занятое значение _KeyField (keymax):
Замените значение _KeyField в одной из повторяющихся записей на правильное:
Здесь _LineNo1386 = - дополнительное условие, которое позволяет выбрать одну из двух повторяющихся записей.
Если одна (или обе) из повторяющихся записей имеет очевидно неправильное значение, то ее нужно удалить:
Если повторяющиеся записи имеют одинаковые значения во всех колонках, то из них нужно оставить одну:
Описанную процедуру необходимо выполнить для каждой пары повторяющихся записей.
2.2.3. Второй пример:
2.3.4 Пример определения неуникальных записей с помощью запроса 1С:Предприятие:
Для более быстрого поиска в базах данных было придумано свойство индекс. При использовании таблиц значений мы также можем создавать индексы для произвольных колонок.
Например, у нас есть таблица с колонками «Номенклатура, Цена, ЕдиницаИзмерения». И если мы часто ищем в таблице строки с какой-то номенклатурой, то лучше эту колонку проиндексировать и тогда программа не будет каждый раз перебирать все строки, а будет использовать индекс.
Чтобы создать индекс применяется метод «Индекс», в параметрах которого передается строка в которой перечисляются индексируемые колонки.
Т.к. индексируемых колонок может быть несколько, то возможна и такая запись:
Когда индекс создан, то при использовании методов таблицы значений «Найти» или «НайтиСтроки» будет использоваться созданный нами индекс.
А для поиска в таблице значений существует два специальных метода: первый Найти
Данный метод возвращает первую найденную строку с искомым значением или Неопределено, если не находит. Поэтому его удобно использовать для поиска уникальных значений, т.к. иначе придется при нахождении значения удалять его из таблицы, чтобы найти следующее.
Чтобы так не мучиться существует следующий метод, который позволяет находить массив подходящих строк НайтиСтроки
Этот метод всегда возвращает массив, но он может быть и пустой, если ничего не найдено. И ещё этот метод также как и предыдущий возвращает сами строки таблицы значений, а не сами значения в отдельном массиве. Поэтому изменив значения в строке массива или как в предыдущем методе у найденной строки, Вы поменяете значение в обрабатываемой таблице значений.
Чем ещё хорош этот метод, так это то, что он может искать сразу по нескольким колонкам таблицы значений одновременно:
Единственный минус, как видно, нельзя применять другие виды сравнения кроме как "равно"
Общее:
Механизм последовательности документов предназначен для отслеживания правильной последовательности проведения группы взаимосвязанных документов. Основная идея данного механизма заключается в том, что при своем проведении документ может использовать некоторые данные, уже хранящиеся в информационной базе. При этом процесс проведения документа зависит от значения этих данных на момент времени регистрации документа. Если после проведения документа эти данные были изменены, то документ должен быть перепроведен, для того чтобы он был правильно отражен в разных учетных регистрах. Например, документ, который при проведении определяет цену товара по регистру сведений, должен быть перепроведен при изменении цены задним числом, так как выполненные на основании этой информации движения стали неверными.
Схему работы этого механизма можно представить следующим образом. Документ при записи регистрируется в последовательности документов. Данная регистрация сигнализирует системе, что при проведении документ использует определенные данные информационной базы, и от их состояния на заданный момент времени зависит результат проведения документа. В конце процесса проведения документа система определяет, в каких последовательностях документов был зарегистрирован документ. Для каждой последовательности, в которой был зарегистрирован документ, определяется, были ли все документы, зарегистрированные в последовательности ранее данного документа, проведены в правильной последовательности. Если это условие выполняется, то данный документ тоже считается проведенным в правильной последовательности. Если данное условие не выполняется, то считается, что документ не был проведен в правильной последовательности и его надо перепровести.
При изменении данных, которые используются документами для проведения, система определяет, какие последовательности документов зависят от этих данных. Для всех документов, зарегистрированных в соответствующих последовательностях позже момента времени, к которому относятся изменяемые данные, устанавливается, что их нужно перепровести.
Пользователь может получить информацию о том, какие документы были проведены в правильной последовательности, а какие нет. Эта информация выдается в виде момента времени, до которого все документы считаются проведенными в правильной последовательности. Все документы позже данного момента времени считаются проведенными в неправильной последовательности. На основе данной информации пользователь может принять решение о восстановлении правильной последовательности проведения документов. Процесс восстановления заключается в перепроведении всех документов участвующих в последовательности, и являющихся проведенными.
Реализация:
При разработке прикладного решения разработчик должен описать, какие документы могут участвовать в последовательности, и какие данные используются этими документами при своем проведении. Вся эта информация задается в объекте метаданных Последовательность. Разработчик отдельно указывает список документов, которые будут участвовать в последовательности, и список регистров, данные из которых будут использоваться при проведении документа. Важно заметить, что автоматическое отслеживание изменения данных для поддержки последовательностей документов осуществляется платформой только для регистров накопления, расчета, бухгалтерии и сведений.
Последовательность документов может иметь измерения. Измерения позволяют разбить общую последовательность документов на более мелкие последовательности в разрезе измерений. Например, если при проведении документ использует цены товаров, хранящиеся в регистре сведений, то при изменении цены любого товара будут перепроведены все документы, даже если в этом документе не использовался данный товар. Для того чтобы избежать такой ситуации, у последовательности документов можно определить измерение Товар. При регистрации в последовательности документов будет указываться, по каким товарам данный документ использует данные. Тогда при восстановлении последовательности документов, система может определить, по каким товарам было произведено изменение данных, и соответственно, какие документы должны быть перепроведены.
Регистрация документа в последовательности может осуществляться автоматически. Для этого разработчик должен настроить соответствия между реквизитами документа и измерениями последовательности документа. Если в соответствии был указан один или несколько реквизитов табличной части документа, то документ будет зарегистрирован в последовательности ровно столько раз, сколько в данной табличной части строк с уникальной комбинацией значений соответствующих реквизитов. Если в соответствиях с измерениями последовательности были указаны реквизиты разных табличных частей, то документ будет зарегистрирован столько раз, сколько уникальных комбинаций значений можно составить из соответствующих реквизитов этих табличных частей. Если все табличные части имеют во всех строках уникальные сочетания значений соответствующих реквизитов, то количество регистраций будет равно N1*N2...*Ni раз, где Ni количество строк соответствующей табличной части, реквизиты которой участвуют в соответствиях.
Для автоматического отслеживания изменений данных в разрезе измерений последовательности документов, нужно настроить соответствие измерений и реквизитов регистров и измерений последовательностей документов. Нужно помнить, что при создании новой последовательности документов или добавлении нового вида документа автоматическая регистрация документов в последовательности не происходит. Для регистрации документов в последовательности нужно или перезаписать документы, или написать обработку, которая будет регистрировать документы в последовательности документов.
Механизм последовательности документов использует две сущности: регистрация документа в последовательности, граница последовательности. Для каждой из этих сущностей в системе создаются таблицы данных. Регистрация используется для регистрации документа в последовательности. Обе эти таблицы доступны в языке запросов 1С:Предприятия.
Таблица регистрации имеет следующие поля: период, регистратор, измерения последовательности. В таблице регистрации документов хранятся записи уникальные по измерениям в пределах одного регистратора. То есть для определенной комбинации значений измерений по одному регистратору, хранится только одна запись, но может храниться множество записей с одним и тем же набором значений реквизитов для различных регистраторов. Работа с данными этой таблицы происходит через набор записей регистрации документа в последовательности документа. У объекта документа есть коллекция наборов записей регистрации в последовательностях документов. Наборы записей из этой коллекции используются для регистрации документа в последовательностях при записи документа. Важно помнить, что при отмене проведения, отмена регистрации в последовательностях документов не происходит. Но не проведенный документ не участвует в восстановлении последовательности. В остальном, работа с набором записей регистрации документа в последовательности точно такой же, как и с набором записей любого регистра.
Граница последовательности показывает момент времени (границу), по которую документы проводились в правильной последовательности. Структура таблицы границ аналогична структуре таблицы регистрации, но содержание и смысл ее отличается. В отличие от таблицы регистрации, в таблице границ может содержаться только уникальные по набору значений измерений записи. То есть для определенной комбинации значений измерений, хранится только одна запись. Период и регистратор задают момент времени границы по данным измерениям. Изменять содержимое таблицы границ последовательности можно только через объект менеджер последовательности документов.
Процесс записи документа:
Начало транзакции
Автоматическое заполнение наборов записей регистрации документа в последовательности
Вызов предопределенной процедуры ПередЗаписью()
Запись документа
Вызов предопределенной процедуры ПриЗаписи()
Запись измененных и не записанных наборов записей движений документа
Проверка и перенос границ последовательностей на момент времени движений (данное действие производится в наборе записей, не в документе!)
Запись измененных и не записанных наборов записей регистрации документа в последовательностях
Конец транзакции
Процесс записи документа с проведением:
Начало транзакции
Автоматическое заполнение наборов записей регистрации документа в последовательности
Вызов предопределенной процедуры ПередЗаписью()
Запись документа
Вызов предопределенной процедуры ПриЗаписи()
Вызов предопределенной процедуры ОбработкаПроведения()
Запись измененных и не записанных наборов записей движений документа
Проверка и перенос границ последовательностей на момент времени движений (данное действие производится в наборе записей, не в документе!)
Запись измененных и не записанных наборов записей регистрации документа в последовательностях
Проверка и перенос границы последовательности на момент времени регистрации документа
Конец транзакции
Процесс записи документа с отменой проведения
Начало транзакции
Автоматическое заполнение наборов записей регистрации документа в последовательности
Вызов предопределенной процедуры ПередЗаписью()
Вызов предопределенной процедуры ОбработкаУдаленияПроведения()
Удаление движений документа
Проверка и перенос границ последовательностей на момент времени движений (данное действие производится в наборе записей, не в документе!)
Запись документа
Вызов предопределенной процедуры ПриЗаписи()
Запись измененных и не записанных наборов записей регистрации документа в последовательностях
Конец транзакции
Важной особенностью данного процесса является то, что перенос границы последовательности назад (сбивание границы) происходит только при записи наборов записей регистров и при этом соответствующие границы были больше (позже) момента времени движений. Перенос границы последовательности вперед (восстановление границы) происходит, только если был процесс проведения документа, границы последовательностей были меньше (раньше) момента времени документа, и между границей последовательности и документом нет проведенных и участвующих в последовательности документов, то есть нет неправильно проведенных документов, требующих перепроведения. Таким образом, автоматическое сбивание границы последовательности происходит только при изменении регистра, не важно каким набором записей он изменяется - принадлежащим документу или созданным отдельно. Автоматическое восстановление последовательности происходит только при проведении документа. Запись документа, регистрация документа в последовательности, сам факт проведения документа границу последовательности сбить не может. Сбивает границу только изменение самого регистра.
Разработчику доступны методы по установке границы на произвольный момент времени. Кроме установки границы последовательности на произвольный момент, разработчик может получить текущую границу последовательности, проверить, что по заданный момент времени последовательность не нарушена, принадлежит ли данный документ последовательности или нет, восстановить последовательность. Что такое Последовательность Документов(в кратце)
GUID (Globally Unique Identifier) — статистически уникальный 128-битный идентификатор. Его главная особенность — уникальность, которая позволяет создавать расширяемые сервисы и приложения без опасения конфликтов, вызванных совпадением идентификаторов. Хотя уникальность каждого отдельного GUID не гарантируется, общее количество уникальных ключей настолько велико (2128 или 3,402 * 10в38), что вероятность того, что в мире будут независимо сгенерированы два совпадающих ключа, крайне мала.
Для получения уникального идентификатора объекта, используйте код вида:
Как с помощью запроса получить уникальный идентификатор:
В 1С 7.7 можно получить так
Через v7plus.dll
Через WScript
при OLE доступе:
Еще посмотрите метод: ЗначениеВСтрокуВнутр(<?>);
Синтаксис:
ЗначениеВСтрокуВнутр(<Объект>)
Назначение:
Преобразование значения объекта агрегатного типа в строковое системное представление.
Возвращает: представление значения объекта в строковом системном виде.
Параметры:
<Объект> - значение объекта агрегатного типа данных которое нужно преобразовать.
 Google maps : вывод точек на карту и режим панорамы
Google maps : вывод точек на карту и режим панорамы