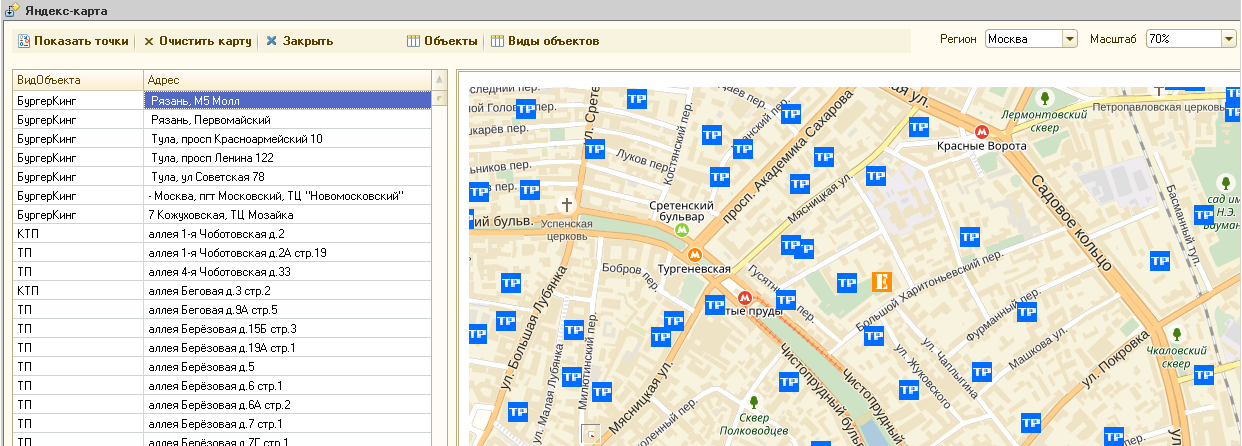
Строка даты-времени сплошная без пробельных разделителей
Латинские символы используются в качестве разделителей/идентификаторов: D - дни, Y - годы, Z - идентификатор UTC и т.д., например можно задать промежуток времени: P4Y3M2D1H - 4 года, 3 месяца, 2 дня и 1 час.
Буква T выбрана в качестве уникального разделителя времени, остальные буквы латинского алфавита (почти все) задействованы под разные цели и они не пересекаются. Соответственно упрощается парсинг ISO-8601 строки: имеется заранее известный набор флагов/символов/маркеров, опираясь на которые, можно достаточно быстро разбить строку на нужные составляющие и при этом сохраняется требование к human readability самой строки.
Для формирования и выполнения запросов к таблицам базы данных в платформе 1С используется специальный объект языка программирования Запрос. Создается этот объект вызовом конструкции Новый Запрос. Запрос удобно использовать, когда требуется получить сложную выборку данных, сгруппированную и отсортированную необходимым образом. Классический пример применения запроса - получение сводки по состоянию регистра накопления на определенный момент времени. Так же, механизм запросов позволяет легко получать информацию в различных временных разрезах.
Текст запроса – это инструкция, в соответствии с которой должен быть выполнен запрос. В тексте запроса описывается:
таблицы информационной базы, используемые в качестве источников данных запроса;
поля таблиц, которые требуется обрабатывать в запросе;
правила группировки;
сортировки результатов;
и т. д.
Инструкция составляется на специальном языке – языке запросов и состоит из отдельных частей – секций, предложений, ключевых слов, функций, арифметических и логических операторов, комментариев, констант и параметров.
Язык запросов платформы 1С очень похож на синтаксис других SQL-языков, но имеются отличия. Основными преимуществами встроенного языка запросов являются: разыменование полей, наличие виртуальных таблиц, удобная работа с итогами, нетипизированные поля в запросах.
Рекомендации по написанию запросов к базе данных на языке запросов платформы 1С:
1) Текст запроса может содержать предопределенные данные конфигурации, такие как:
значения перечислений;
предопределенные данные:
справочников;
планов видов характеристик;
планов счетов;
планов видов расчетов;
пустые ссылки;
значения точек маршрута бизнес-процессов.
Также текст запроса может содержать значения системных перечислений, которые могут быть присвоены полям в таблицах базы данных: ВидДвиженияНакопления, ВидСчета и ВидДвиженияБухгалтерии. Обращение в запросах к предопределенным данным конфигурации и значениям системных перечислений осуществляется с помощью литерала функционального типа ЗНАЧЕНИЕ. Данный литерал позволяет повысить удобочитаемость запроса и уменьшить количество параметров запроса.
Пример использования литерала ЗНАЧЕНИЕ:
ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.Москва)
ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.ПустаяСсылка)
ГДЕ ТипТовара = ЗНАЧЕНИЕ(Перечисление.ВидыТоваров.Услуга)
ГДЕ ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
ГДЕ ТочкаМаршрута = ЗНАЧЕНИЕ(БизнесПроцесс.БизнесПроцесс1.ТочкаМаршрута.Действие1
2) Использование инструкции АВТОУПОРЯДОЧИВАНИЕ в запросе может сильно время выполнения запроса, поэтому, если сортировка не требуется, то лучше вообще ее не использовать. Во большинстве случаях лучше всего применять сортировку с помощью инструкции УПОРЯДОЧИТЬ ПО.
Автоупорядочивание работает по следующим принципам:
Если в запросе было указано предложение УПОРЯДОЧИТЬ ПО, то каждая ссылка на таблицу, находящаяся в этом предложении, будет заменена полями, по которым по умолчанию сортируется таблица (для справочников это код или наименование, для документов – дата документа). Если поле для упорядочивания ссылается на иерархический справочник, то будет применена иерархическая сортировка по этому справочнику.
Если в запросе отсутствует предложение УПОРЯДОЧИТЬ ПО, но есть предложение ИТОГИ, тогда результат запроса будет упорядочен по полям, присутствующим в предложении ИТОГИ после ключевого слова ПО, в той же последовательности и, в случае если итоги рассчитывались по полям – ссылкам, то по полям сортировки по умолчанию таблиц, на которые были ссылки.
Если в запросе отсутствуют предложения УПОРЯДОЧИТЬ ПО и ИТОГИ, но есть предложение СГРУППИРОВАТЬ ПО, тогда результат запроса будет упорядочен по полям, присутствующим в предложении, в той же последовательности и, в случае если группировка велась по полям – ссылкам, то по полям сортировки по умолчанию таблиц, на которые были ссылки.
В случае же, если в запросе отсутствуют предложения и УПОРЯДОЧИТЬ ПО, ИТОГИ и СГРУППИРОВАТЬ ПО, результат будет упорядочен по полям сортировки по умолчанию для таблиц, из которых выбираются данные, в порядке их появления в запросе.
В случае, если запрос содержит предложение ИТОГИ, каждый уровень итогов упорядочивается отдельно.
3) Что бы избежать повторного запроса к базе данных при выводе результата запроса пользователю (например, построение запроса или отображение результата запроса с помощью табличного документа) полезно использовать инструкцию ПРЕДСТАВЛЕНИЕССЫЛКИ, которая позволяет получать представление ссылочного значения. Пример:
Так же возможно использование инструкции ПРЕДСТАВЛЕНИЕ - предназначена для получения строкового представления значения произвольного типа. Отличие этих инструкций в том, что в первом случае, если инструкции передать ссылку, результатом будет строка, В остальных случаях результатом будет значение переданного параметра. Во втором случае, результатом инструкции всегда будет строка!
4) Если в запросе имеется поле с составным типом, то для таких полей возникает необходимость привести значения поля к какому-либо определенному типу с помощью инструкции ВЫРАЗИТЬ, что позволит убрать лишние таблицы из левого соединения с полем составного типа данных и ускорить выполнение запроса. Пример:
Имеется регистра накопления ОстаткиТоваров, у которого поле Регистратор имеет составной тип. В запросе выбираются Дата и Номер документов ПоступлениеТоваров, при этом при обращении к реквизитам документа через поле Регистратор не происходит множество левых соединений таблицы регистра накопления с таблицами документов-регистраторов.
Если приведение типа считается не осуществимым, то результатом приведения типа будет значение NULL.
5) Не стоит забывать про инструкцию РАЗРЕШЕННЫЕ, которая означает, что запрос выберет только те записи, на которые у текущего пользователя есть права. Если данное слово не указать, то в случае, когда запрос выберет записи, на которые у пользователя нет прав, запрос отработает с ошибкой.
6) В случае, если в запросе используется объединение, и в некоторых частях объединения присутствуют вложенные таблицы (документ с табличной частью), а в некоторых нет, возникает необходимость дополнения списка выборки полями – пустыми вложенными таблицами. Делается это при помощи ключевого слова ПУСТАЯТАБЛИЦА, после которого в скобках указываются псевдонимы полей, из которых будет состоять вложенная таблица. Пример:
7) Что бы в результат запроса не попали повторяющиеся строки, следует использовать инструкцию РАЗЛИЧНЫЕ, потому что так нагляднее и понятнее, а инструкция СГРУППИРОВАТЬ ПО применяется для группировки с помощью агрегатных функций. Ксати, при использовании агрегатных функций предложение СГРУППИРОВАТЬ ПО может быть и не указано совсем, при этом все результаты запроса будут сгруппированы в одну единственную строку. Пример:
8) Инструкция СГРУППИРОВАТЬ ПО позволяет обращаться к полям верхнего уровня, без группировки результатов по этим полям, если агрегатные функции применены к полям вложенной таблицы. Хотя в справке 1С написано, при группировке результатов запроса в списке полей выборки обязательно должны быть указаны агрегатные функции, а помимо агрегатных функций в списке полей выборки допускается указывать только поля, по которым осуществляется группировка. Пример:
9) Инструкция ЕСТЬNULL предназначена для замены значения NULL на другое значение, но не забываем, что второй параметр будет преобразован к типу первого в случае, если тип первого параметра является строкой или числом.
10) При обращении к главной таблице можно в условии обратиться к данным подчиненной таблицы. Такая возможность называется разыменование полей подчиненной таблицы.
Пример (поиск документов, содержащих в табличной части определенный товар):
Преимущество этого запроса перед запросом к подчиненной таблице Приходная.Товары в том, что если есть дубли в документах, результат запроса вернет только уникальные документы без использования ключевого слова РАЗЛИЧНЫЕ.
11) Интересный вариант оператора В - это проверка вхождения упорядоченного набора в множество таких наборов (Поле1, Поле2, ... , ПолеN) В (Поле1, Поле2, ... , ПолеN).
Пример:
12) При любой возможности используйте виртуальные таблицы запросов. При создании запроса система предоставляет в качестве источников данных некоторое количество виртуальных таблиц - это таблицы, которые так же являются результатом запроса, который система формирует в момент выполнения соответствующего участка кода.
Разработчик может самостоятельно получить те же самые данные, которые система предоставляет ему в качестве виртуальных таблиц, однако алгоритм получения этих данных не будет оптимизирован, так как:
Все виртуальные таблицы параметризованы, т. е. разработчику предоставляется возможность задать некоторые параметры, которые система будет использовать при формировании запроса создания виртуальной таблицы. В зависимости от того, какие параметры виртуальной таблицы указаны разработчиком, система может формировать РАЗЛИЧНЫЕ запросы для получения одной и той же виртуальной таблицы, причем они будут оптимизированы с точки зрения переданных параметров.
Не всегда разработчик имеет возможность получить доступ к тем данным, к которым имеет доступ система.
13) В клиент-серверном варианте работы функция ПОДСТРОКА() реализуется при помощи функции SUBSTRING() соответствующего оператора SQL, передаваемого серверу баз данных SQL Server, который вычисляет тип результата функции SUBSTRING() по сложным правилам в зависимости от типа и значений ее параметров, а так же в зависимости от контекста, в котором она используется. В большинстве случаев эти правила не оказывают влияния на выполнение запроса, но бывают случаи, когда для выполнения запроса существенна максимальная длина строки результата, вычисленная SQL Server. Важно иметь в виду, что в некоторых контекстах использования функции ПОДСТРОКА() максимальная длина ее результата может оказаться равной максимальной длине строки ограниченной длины, которая в SQL Server равна 4000 символам. Это может привести к неожиданному аварийному завершению выполнения запроса:
Microsoft OLE DB Provider for SQL Server: Warning: The query processor could not produce a query plan from the optimizer because the total length of all the columns in the GROUP BY or ORDER BY clause exceeds 8000 bytes.
HRESULT=80040E14, SQLSTATE=42000, native=8618
Чтобы избежать такой ошибки, не рекомендуют использовать функцию ПОДСТРОКА() с целью приведения строк неограниченной длины к строкам ограниченной длины. Вместо нее лучше использовать операцию приведения типа ВЫРАЗИТЬ().
14) С осторожностью используйте ИЛИ в конструкции ГДЕ, так как использование условия с ИЛИ может значительно "утяжелить" запрос. Решить проблему можно конструкцией ОБЪЕДИНИТЬ ВСЕ. Пример:
15) Условие НЕ В в конструкции ГДЕ увеличивает время исполнения запроса, так как это своего рода НЕ (ИЛИ1 ИЛИ2 ... ИЛИn), поэтому для больших таблиц старайтесь использовать ЛЕВОЕ СОЕДИНЕНИЕ с условием ЕСТЬ NULL. Пример:
16) При использовании Временных таблиц нужно индексировать поля условий и соединений в этих таблицах, НО, при использовании индексов запрос может выполняться еще медленнее. Поэтому необходимо анализировать каждый запрос с применением индекса и без, замерять скорость выполнения запроса и принимать окончательное решение.
Если вы помещаете во временную таблицу данные, которые изначально индексированы по некоторым полям, то во временной таблице индекса по этим полям уже не будет.
17) Если вы не используете Менеджер временных таблиц, то явно удалять временную таблицу не требуется, она будет удалена после завершения выполнения пакетного запроса, иначе следует удалить временную таблицу одним из способов: командой УНИЧТОЖИТЬ в запросе, вызвать метод МенеджерВременныхТаблиц.Закрыть().
После обновления бухгалтерии 2.0 на 3.0 нумерация документов начинается заново, что делать и как исправить?
В бухгалтерии редакции 3.0 изменен способ нумерации документов по сравнению с редакцией 2.0.
Для правильной нумерации документов необходимо изменить номер первого создаваемого документа каждого вида так, чтобы он продолжал нумерацию из старой версии.
При этом номера документов, перенесенных из редакции 2.0, в печатных формах будут отображаться правильно.
Например, последний номер документа «Реализация товаров и услуг» был 00000000131.
После обновления на редакцию 3.0 первый введенный документ будет иметь номер 0000-000001.
Чтобы сохранить правильную нумерацию, необходимо в этом документе изменить номер на 0000-000132.
В дальнейшем всем введенным документам «Реализация товаров, услуг» будет присваиваться правильный номер.
Если по каким-то причинам первый способ Вам не помогает, то обратитесь к программисту 1С для настройки нумерации документов.
Ниже приведен код осуществляющий свою нумерацию документов
В форме документа счет-фактура выданный аванс заполнить табличную часть Авансы на основании документа поступление безналичных денежных средств. Условия:
1) Перед заполнением табличной части документа получить от пользователя подтверждение на это действие;
2) Обработку создания документа сделать внешней и подключаемой к форме документа счет-фактура на аванс выданный;
3) После заполнения табличной части не записывать документ, а разрешить пользователю продолжить редактирование изменной табличной части или самостоятельно записать документ. Решение:
Пункты 1 и 2 не представляют особой сложности, но пункт 3 заставил меня задуматься и написать, по-моему мнению, топорный, но исправно действующий код.
Понятно, что от нас требуется создать внешнюю обработку вида "ЗаполнениеОбъекта" и подключить её в информационную базу.
Приведу код в модуле обработки:
Так как нам придется работать с формами объектов мы просто вынуждены использовать метод ВызовКлиентскогоМетода для вызова команды внешней обработки.
Напомню, при использовании ВызовСерверногоМетода с формами объектов работать не получится.
Так как мы использовали ВызовКлиентскогоМетода, то обязательную процедуру, для внешней подключаемой обработки заполнения объектов, ВыполнитьКоманду(ИдентификаторКоманды, ОбъектыНазначенияМассив) Экспорт, необходимо выполнять &НаКлиенте в модуле формы обработки, а значит создадим любую форму обработки, пользователь её всеравно не увидит, и поместим внутрь модуля формы следующий код:
Ниже приведу код, который у вас может быть совершенно другим и делать, какие-либо другие манипуляции с объектом формы:
Регулярные выражения (Regular Expressions) являются известным и мощным средством для поиска, тестирования и замены подстрок. Эта технология доступна и в 1С - через объект VBScript.RegExp. Нужный объект уже встроен в современные версии Windows (начиная с Windows 98), и устанавливать дополнительно ничего не нужно.
Приведенные ниже примеры были протестированы в 1С:Предприятие 7.7; для 1С:Предприятие 8.x изменяется способ создания объекта:
Кроме того, там уже есть логические константы Истина и Ложь - объявлять их не нужно.
Более подробное описание самой технологии RegExp (что означают те или иные значки или скобочки, или какие шаблоны поиска или замены можно использовать в типичных ситуациях) можно найти в специальной литературе (например Бен Форта "Освой самостоятельно регулярные выражения (regexp) за 10 минут") или на сайтах в сети Internet.
Более продвинутый пример разбора HTML использует подвыражения (SubMatches) и позволяет находить как сами теги, так и текст между ними.
Часто регулярные выражения используются для тестирования строк, например пользовательского ввода.
Этот пример позволяет узнать, является ли строка целым числом.
Регулярные выражения поддерживают не только поиск, но и замену текста. При этом найденные подвыражения (в круглых скобках) могут быть представлены в строке замены как $1, $2 и т. д.
(знак доллара используется в VBScript.RegExp; в других средах программирования, например в JavaScript, используемый для этой цели символ может отличаться).
Число - Число, которое необходимо преобразовать в строку прописью.
Форматная строка представляет собой строковое значение, включающее параметры форматирования. Параметры форматирования перечисляются через символ ";" (точка с запятой). Если параметр не указывается, используется значение параметра по умолчанию.
Каждый параметр задается именем параметра, символом "=" (равно) и значением параметра. Значение параметра может указываться в одинарных или двойных кавычках. Это необходимо, если значение параметра содержит символы, используемые в синтаксисе форматной строки.
Л (L) - Код локализации. По умолчанию используется код локализации, установленный в операционной системе. Примеры кодов локализации: ru_RU - Русский (Россия); en_US - Английский (США).
НП (SN) - Включать/не включать название предмета исчисления (Булево), по умолчанию - Истина.
НД (FN) - Включать/не включать название десятичных частей предмета исчисления (Булево), по умолчанию - Истина.
ДП (FS) - Дробную часть выводить прописью/числом (Булево), по умолчанию - Ложь.
Параметры предмета исчисления - Представляет собой строковое значение, определяющее параметры предмета исчисления. Параметры предмета исчисления перечисляются через "," (запятая). Формат строки зависит от кода локализации.
Для русского и белорусского языков (ru_RU, be_BY)
"рубль, рубля, рублей, м, копейка, копейки, копеек, ж, 2", где:
"рубль, рубля, рублей, м" – предмет исчисления:
рубль – единственное число именительный падеж,
рубля – единственное число родительный падеж,
рублей – множественное число родительный падеж,
м – мужской род (ж – женский род, с - средний род);
"копейка, копейки, копеек, ж" – дробная часть, аналогично предмету исчисления (может отсутствовать);
"2" – количество разрядов дробной части (может отсутствовать, по умолчанию равно 2).
Для украинского языка (uk_UA)
"гривна, гривны, гривен, м, копейка, копейки, копеек, ж, 2", где:
"гривна, гривны, гривен, м" – предмет исчисления:
"гривна – единственное число именительный падеж,
гривны – единственное число родительный падеж,
гривен – множественное число родительный падеж,
м – мужской род (ж – женский род, с - средний род);
"копейка, копейки, копеек, ж" – дробная часть, аналогично предмету исчисления (может отсутствовать);
"2" – количество разрядов дробной части (может отсутствовать, по умолчанию равно 2).
Для польского языка (pl_PL)
z?oty, z?ote, z?otych, m, grosz, grosze, groszy, m, 2
где:
"z?oty, z?ote, z?otych, m " - предмет исчисления (m - мужской род, ? - женский род, ? - средний род, mo – личностный мужской род)
z?oty - единственное число именительный падеж
z?ote - единственное число винительный падеж
z?otych - множественное число винительный падеж
m - мужской род (? - женский род, ? - средний род, mo – личностный мужской род)
"grosz, grosze, groszy, m " - дробная часть (может отсутствовать) (аналогично целой части)
2 - количество разрядов дробной части (может отсутствовать, по-умолчанию равно 2)
Для английского, финского и казахского языков (en_US, fi_FI, kk_KZ)
"dollar, dollars, cent, cents, 2", где:
"dollar, dollars" – предмет исчисления в единственном и множественном числе;
"cent, cents" – дробная часть в единственном и множественном числе (может отсутствовать);
"2" – количество разрядов дробной части (может отсутствовать, по умолчанию равно 2).
Для немецкого языка (de_DE)
"EURO, EURO, М, Cent, Cent, M, 2", где:
"EURO, EURO, М" – предмет исчисления:
EURO, EURO – предмет исчисления в единственном и множественном числе;
М – мужской род (F – женский род, N - средний род);
"Cent, Cent, M" – дробная часть, аналогично предмету исчисления (может отсутствовать);
"2" – количество разрядов дробной части (может отсутствовать, по умолчанию равно 2).
 Как строку вида 2023-07-24T15:35:34+03:00 (формат ISO 8601) преобразовать в дату?
Как строку вида 2023-07-24T15:35:34+03:00 (формат ISO 8601) преобразовать в дату?