ИЛИ Найти(ТипСодержимого, "+xml") ИЛИ Найти(ТипСодержимого, "/xml") 0 ИЛИ Найти(ТипСодержимого, "/json") 0 Тогда
ПолучитьКакДвоичныеДанные = Ложь;
ИначеЕсли Найти(ТипСодержимого, "image/") = 1 ИЛИ Найти(ТипСодержимого, "video/") = 1
ИЛИ Найти(ТипСодержимого, "application/") = 1 ИЛИ Найти(ТипСодержимого, "audio/") = 1 Тогда
//Если содержимое полученного ответа представляет собой изображение, видео, приложение,
//возвращаем двоичные данные, так как возвращать в виде строки не имеет смысла.
ПолучитьКакДвоичныеДанные = Истина;
КонецЕсли;
//Некоторые сервера возвращают в типе содержимого имя отданного файла, например image/png; name="Имя файла.png"
//или отдают в заголовке Content-Disposition: attachment; filename=Имя файла.png (http://www.http11.ru/post.php?post=2) Если ОтветHTTP.Заголовки["Content-Disposition"] Неопределено Тогда
Часто клиенты просят сделать автоматическую отправку счетов или отчетов на электронную почту, ниже приведены примеры кода для разных версий 1С:
С версиями 8.2 сложнее, так как все почтовые сервисы перешли на SSL, а медоты:
появились только в 8.3.1 , остается использовать stunnel или CDO:
Через stunnel в 1С код, менять не нужно, только установить программу и изменить настройки подключения к почтовому ящику
Скачиваем stunnel c официального сайта (stunnel.org) и запускаем инсталятор, жмем yes при установке спросит страну и ваши данные, это нужно для создания сертификата на вашем компьютере.
После запуска в трее появится его иконка, правой клавишей и редактировать edit configuration
В блокноте откроется файл настроек, там будет пример для gmail дополняем или заменяем его следующим:
Сохраняем файл и делаем Reload configuration
В настройка 1С меняем порты для работы
gmail
pop3 10110
imap 10143
smtp 10025
yandex
pop3 20110
imap 20143
smtp 20025
mail
pop3 30110
imap 30143
smtp 30025
Если в коде прописано, то:
Все, можно отправлять и проверять работу через консоль Show log window в меню
P.S. Почтовый ящик в примерах не рабочий, как пример
В рамках выполнения проекта столкнулся с интересной задачей ускорения загрузки данных из других информационных баз. Задача загрузки данных предполагала выполнение к внешней базе несвязанных между собой запросов, результаты которых помещаются в одну таблицу значений. Когда на оптимизацию запроса рука уже не поднималась, приступил к ускорению загрузки с помощью распараллеливания процессов. Отмечу, что элементы кода в данном посте приведены для клиент-серверного варианта и укрупнено для общего понимания подхода.
Что у нас в 1с Предприятии 8.2 имеется для распараллеливания & это фоновые задачи. Метод, который будет вызываться в фоновой задаче, должен быть прописан в серверном общем модуле и быть экспортным. Естественно нам понадобиться в фоновую задачу передавать и забирать значения.
В моем случае передача значений в фоновую задачу происходила через параметры. Метод ЗагрузитьИзВИБ имеет два параметра это ВходнойПараметр и АдресВХранилище. ВходнойПараметр это структура, в которую сгружаются все данные, необходимые для проведения загрузки. АдресВХранилище это адрес во временном хранилище, по которому будет передан результат загрузки. Сам код метода фонового задания выглядит так:
Зачем нам в фоновую задачу передавать адрес во временном хранилище. Наша фоновая задача должна куда-то положить результат, причем так чтобы мы знали где его потом взять.
Для того чтобы запустить фоновые задачи выполняется следующий код:
Перед запуском фоновой задачи через ФоновыеЗадания.Выполнить() мы формируем массив параметров. Значения из массива параметров переходят в метод фонового задания в качестве параметров. В МассивЗапущенныхЗаданий хранятся все фоновые задачи, которые мы запустили. Теперь надо подождать их ожидания.
После того как все задачи были завершены, можем приступить к получению из них данных. Для этого мы проходим по всем адресам в хранилище, которые хранятся в массиве МассивАдресовВХранилище. После получения результата фонового задания перегоняем его в общую таблицу.
Вопрос определения оптимального количества потоков выходит за рамки данного поста. А после получения некоторых результатов на рабочих данных пока что выходит и за рамки моего сознания . Но если у вас есть идеи как посчитать нужное количество потоков, пишите в комментариях, с радостью почитаю.
* проверям, что в созданном файлике /var/www/html/baza/default.vrd и нет лишних (двойных) "/" . У меня они каждый раз появлялись и каждый раз мне проще было их удалить чем вникать, где в команде я напортачил. (также стоит проверить /etc/httpd/conf/httpd.conf, база прописывается в самый конец конфига).
4) ставишь на папку права для пользователя apache: chown apache:apache /var/www/html/baza и перезагружаешь апач.
Проблема в том, что 64-битный апач не хочет работать ( нужно заменить его на 32-битный!
Порядок действий такой:
1. Нужно подкорректировать файлы репозитария, чтобы он загружал 32-битные версии: Открываем /etc/yum.repos.d/, копируете эти файлы для архива и исправляете в текущих $basearch на i686.
2. чистим кэш так: yum clean all или в папке /var/cache/yum/
3. yum install httpd.i686
4. reboot
После перезапуска
./webinst -apache22 -wsdir base -dir '/var/www/html/base/' -connStr 'Srvr=5.101.113.142;Ref=tur;' -confPath /etc/httpd/conf/httpd.conf
При обновлении бухгалтерии, на этапе сохранения, получил следующую ошибку:
Каталог не обнаружен 'v8srvr://sql/acc_main/configsave/e0666db2-45d6-49b4-a200-061c6ba7d569.6b9d6525-ee94-4e13-b73d-82d3e8e8441d'
по причине: Каталог не обнаружен 'ConfigSave\e0666db2-45d6-49b4-a200-061c6ba7d569.6b9d6525-ee94-4e13-b73d-82d3e8e8441d'
по причине: Ошибка СУБД: Microsoft SQL Server Native Client 11.0: Журнал транзакций для базы данных "acc_main" переполнен. Причина: "LOG_BACKUP". HRESULT=80040E14, SQLSrvr: SQLSTATE=42000, state=2, Severity=11, native=9002, line=1
Идем на сервер и первым делом проверяем место на дисках,
А оно закончилось нужно потом почистить хард или увеличивать объем, а пока порежем лог
Открываем SQL Server Management Studio
Это ошибка Microsoft SQL Server - переполняется лог транзакций и не очищается. Урезать его возможно различными способами, в том числе и с помощью стандартной оснастки, но не всегда данная операция получается, и размер файла лога остается прежним. Как вариант предлагаю следующее решение из двух строчек( где acc_main - название базы Бух)
Результат выполнения:
Тоже самое можно сделать вручную:
Шаг 1. Установить модель восстановления Простая (Simple). Правой кнопкой на базе - Свойства(Properties) - Параметры(Options) - 4-й сверху пункт Модель восстановления(Recovery model) - Простая(Simple) - OK.
Шаг 2. Выполнить шринк (сжатие) лога транзакций. Правой кнопкой на базе - Задачи(Tasks) - Сжать(Shrink) - Файлы(Files) - установить Тип файла(File type) - Журнал(Log) - в Операция сжатия(Shrink action) - выбрать Реорганизовать страницы, перед тем осводить неиспользуемое место(Reorganize pages before releseasing unused space) - Сжать файл (Shrink file to) - указать приемлемый размер лога.
Шаг 3. Установить модель восстановления Полная(Full). Правой кнопкой на базе - Свойства(Properties) - Параметры(Options) - 4-й сверху пункт Модель восстановления(Recovery model) - Полная(Full) - OK.
В дополнении скажу, что можно сохранить лог в файл и выполнить шринк так(BaseDB - имя базы данных):
И вот случилось долгожданное: Вышел 1C: Enterprise Development Tools - это среда для разработки конфигурации в IDE Eclipse. С сайта 1С:
«1C:Enterprise Development Tools» – это инструмент нового поколения для разработчиков бизнес-приложений системы программ «1С:Предприятие 8».
Планируется, что он будет использоваться для создания приложений параллельно с текущим инструментом (конфигуратором). При этом формат разрабатываемых приложений будет полностью соответствовать текущим версиям 1С:Предприятия 8. Преимуществами нового инструмента разработки являются: интегрированная среда разработки (соответствие современным тенденциям и требованиям), быстрое развитие инструментов разработки, возможность расширения инструментов разработки. В DT заложена принципиально новая архитектура, которая обеспечивает большой запас развития для реализации различных механизмов автоматизации разработки и повышения удобства разработки. В ознакомительной версии возможности этой архитектуры задействованы только в небольшой части. В данный момент важно реализовать функциональность, аналогичную конфигуратору, но основное предназначение DT в возможности создания новых мощных инструментов для разработчика.
DT разработан с использованием открытой платформы Eclipse (www.eclipse.org). За счет данной интеграции технологий, инструмент объединил в себе преимущества как инструментов разработки «1С:Предприятия», так и стандартных возможностей Eclipse.
Схема работы Конфигуратора
Конфигуратор (входящий в состав системы программ «1С:Предприятие» версии 8.x) работает с конфигурацией, описывающей прикладное решение. Конфигуратор подключается к информационной базе, в которой (во внутреннем формате) хранится конфигурация. В один момент времени конфигуратор может работать только с одной информационной базой, и, как следствие, только с той конфигурацией, которая хранится в этой информационной базе. Более того, для запуска и отладки используется одна версия платформы «1С:Предприятие» – та, с помощью которой выполняется подключение к информационной базе.
Схема работы «1C:Enterprise Development Tools»
DT предлагает принципиально другую схему работы.
Во-первых, конфигурация хранится не в информационной базе, а в файловой системе. Из этого вытекает возможность использования популярной системы контроля версий (git, svn), что, очевидно, является вторым существенным преимуществом. При этом следует понимать, что DT не реализует работу с системой контроля версий самостоятельно, а использует готовые механизмы платформы Eclipse. Поэтому использоваться может только та система контроля версий, поддержка (расширение) которой есть в Eclipse.
Хранение редактируемой конфигурации в файловой системе, а не в информационной базе, означает, что редактирование конфигурации можно выполнять вообще без системы «1С:Предприятие», установленной на компьютере разработчика. Однако, при необходимости запустить прикладное решение или отладить какой-то механизм, наличие установленной версии «1С:Предприятия» является обязательным.
Главные Enterprise Development Tools отличия от обычного Конфигуратора:
1. Платформа Eclipse и возможность написания своих плагинов для удобства работы
2 . Кросплатформенность, т.е наконец-то можно работать на Mac
3. Конфигурация хранится не в информационной базе, а в файловой системе. Из этого вытекает возможность использования популярной системы контроля версий (git, svn)
4. Разрабатываемая конфигурация может использоваться с разными информационными базами и разными версиями «1С:Предприятия»
5. Одновременно можно редактировать несколько конфигураций
6. Работа в DT имеет некоторые отличия в части работы с объектами конфигурации и сохранения результатов работы, т.к. используется платформа Eclipse
7. Более удобная и быстрая командная разработка
Скачиваем и запускаем установку:
1. Сначала платформу 8.3.6
2. потом Enterprise Development Tools
Скачиваем, разархивируем и запускаем DT.exe и получаем ошибку , но это не проблема
Надо установить Java RE, идем на сайт oracle и скачиваем соответствующую вашей операционной системе версию и устанавливаем
иииииии - барабанная дробь вот она, новая среда разработки:
При первом запуске будет запрошен каталог хранения рабочей области. Установка флажка Use this as the default and do not ask again (Использовать это значение по умолчанию в дальнейшем) приведет к тому, что указанный каталог будет автоматически использовать при последующих запусках DT. Для смены рабочей области следует использовать команду File – Switch Workspace (Файл – Сменить рабочую область).
Открылся 1C: Enterprise Development Tools:
Добавление конфигурации
Добавить конфигурации можно по разному, можно загрузить из файла, можно из файлов, можно из git, а можно через импорт существующей базы.
В правом нижнем углу отображены Информационные базы, импортируем одну для теста:
Появляется окно
Если что-то не так, то изменяем и жмем Готово (Кстати, если база открыта в обычном конфигураторе, то вылетит ошибка!)
Идет импорт, спросит пользователя и пароль...
На моем Core i5 с 6 ГБ оперативки, импорт тестовой базы размером 2.5 мегабайта шел чуть больше минуты. И вот с открытым справочником Номенклатура:
Форма
Модуль (подсветка синтаксиса попроще)
Мгновенное определение ошибок (наведя курсор):
Щелкнув по красному крестику - предлагает решение, Создать Элемен , хотя надо просто дописать букву т
Слева в разделе Схема отражены все функции модуля, можно быстро перемещаться по ним:
Синтаксис-помощник мгновенно показывает информацию по свойству или функции на которой установлен курсор
Еще один интересный раздел, все огрехи в конфигурации:
Схема компоновки данных из отчета:
Так же мгновенно показывает ошибки и недочеты в запросе!
Конструктор запроса выглядит так:
Открыть Перспективу
Отладка - думаю, понятно и не буду останавливаться
Ресурсы - показывает разложенную по файлам конфигурацию. Каждый файл можно открыть для просмотра:
Синхронизация совместной работы - допустим через Git
Git - Подключение к Git
Справочная система
Справка , по сути, как и в обычном конфигураторе, только дополненная, выглядит так:
Использование помощника HelpF.pro
Наш помощник пока работает только под Windows, но вскоре мы скомпилируем под Linux и Mac
Открыв код, жмем Alt+H и в появившемся окне вводим запрос (например проверка это новый?) и жмем Найти
В результатах поиска выбираем нужное нам:
Далее в статье (1) выделяем нужный нам код и (2) жмем появившуюся кнопку Вставить
Результат вставки:
Кроме этого работают и горячие клавиши:
Вот пример нажатия Alt+D (Внимание! Alt - правый, левый работает штатно):
На одном проекте - клиент попросил отображать в программе данные, которые выдаю специализированные сайта в формате RSS - Что делать !?
Писать парсер rss для 1С
Первым делом, взглянув на ссылки, подумал что - обычный XML, сейчас его разложу и быстренько загружу в базу, но:
Выяснилось что сайты имеют разные форматы ввода RSS и главное они не валидные(
таким образом, написав небольшой код, который получает ссылку, далее XMLФайл.Прочитать() на одном сайте проходил на ура (этот пример я описывал в статье: Чтение данных с сайта в формате XML и загрузка в 1С), а вот второй сайт, и третий тоже, при попытке прочитать() выдавали:
{ОбщийМодуль.РегЗадания.Модуль(79)}: Ошибка при вызове метода контекста (Прочитать)
Пока XMLФайл.Прочитать() Цикл
по причине:
Ошибка разбора XML: - [1,1]
Фатальная ошибка:
Extra content at the end of the document
SystemId url rss
решил попробовать на rss других известных сайтов - 80% из проверяемых выдавали ошибку
Пришлось написать прямой построчный парсер RSS:
Структура конфигурации
ИсточникиRSS - URL на RSS, ДанныеRSS - сюда записываются загруженные данные новостей
Код получился таким(в принципе код универсальный, но возможно что-то придется подпилить):
К сожалению, иногда, бывают ситуации когда после внезапного отключения света или при обновлении 1С, система выдает: «Файл базы данных поврежден», при этом ссылаясь на файл 1Cv8.1CD
Что же делать? Ниже рекомендации по пунктам:
1. Необходимо сделать архивную копию не через Конфигуратор, а полностью каталога с базой данных (на всякий случай, а случаи, как известно, бывают разные).
2. Запустить утилиту chdbfl.exe, которая должна находиться в каталоге установленной технологической платформы 1с8. Путь приблизительно такой: C:\Program Files\1cv82\8.2.19.ххх\bin (для 8.3 C:\Program Files\1cv8\8.3.5.ххх\bin ).
3. Если совершить проверку без установления галочки "Исправлять обнаруженные ошибки" файла базы данных 1Cv8.1CD, то возможны множественные вариации следующего типа ошибок:
Повреждена таблица размещения внутреннего файла <Данные таблицы '_InfoRg7289'>
Повреждена таблица размещения внутреннего файла <Индексы таблицы '_InfoRg7289'>
С установленной галкой, программа попробует исправить все ошибки и восстановить базу данных
К сожалению бывают ситуации, когда база сильно повреждена и стандартная программа не может восстановить "База данных полностью разрушена, восстановление невозможно"
В этом случае мы советуем больше ничего не делать с базой(чтобы совсем не потерять данные)
В инфраструктурах, активно использующих возможности web-сервисов 1С, нередко возникает потребность получения не только массивов данных из базы, но и различных файлов. Сам файл через веб-сервис так просто не передашь, но на его основе можно создать объект ДвоичныеДанные, который, в свою очередь, уже сериализуется в base64Binary. После такой операции наш веб-сервис без проблем передает данные и получателю остается только выполнить на своей стороне обратное преобразование и сохранить файл.
В качестве примера такого механизма я буду создавать в 1С счет на оплату на основании переданных через сервис ИНН контрагента и суммы, и возвращать PDF печатной формы. На этот раз, кроме примеров кода, дополнительно был записан скринкаст разработки.
Для начала создадим в пустой конфигурации справочник "Контрагенты" с реквизитом "ИНН" и документ "Счет" с реквизитами "Контрагент" и "СуммаДокумента".
Теперь добавим пакет XDTO "test_ws"с пространством имен "http://www.test-ws.org", в котором опишем тип объекта "File". Он будет содержать свойства:
Одной из часто встречающихся причин не оптимальной работы системы является неправильное или несвоевременное выполнение регламентных операций на уровне СУБД. Особенно важно выполнять эти регламентные процедуры в крупных информационных системах, которые работают под значительной нагрузкой и обслуживают одновременно большое количество пользователей. Специфика таких систем в том, что обычных действий, выполняемых СУБД автоматически (на основании настроек) оказывает недостаточно для эффективной работы.
Если в работающей системе наблюдаются какие-либо симптомы проблем с производительностью, следует проверить, что в системе правильно настроены и регулярно выполняются все рекомендуемые регламентные операции на уровне СУБД.
Выполнение регламентных процедур должно быть автоматизировано. Для автоматизации этих операций рекомендуется использовать встроенное средства MS SQL Server: Maintenance Plan. Существуют так же другие способы автоматизации выполнения этих процедур. В настоящей статье для каждой регламентной процедуры дан пример ее настройки при помощи Maintenance Plan для MS SQL Server 2005.
Для MS SQL Server рекомендуется выполнять следующие регламентные операции:
Обновление статистикОчистка процедурного КЭШаДефрагментация индексовРеиндексация таблиц базы данных
Рекомендуется регулярно контролировать своевременность и правильность выполнения данных регламентных процедур.
Обновление статистик
MS SQL Server строит план запроса на основании статистической информации о распределении значений в индексах и таблицах. Статистическая информация собирается на основании части (образца) данных и автоматически обновляется при изменении этих данных. Иногда этого оказывается недостаточно для того, что MS SQL Server стабильно строил наиболее оптимальный план выполнения всех запросов.
В этом случае возможно проявление проблем с производительностью запросов. При этом в планах запросов наблюдаются характерные признаки неоптимальной работы (неоптимальные операции).
Для того, чтобы гарантировать максимально правильную работу оптимизатора MS SQL Server рекомендуется регулярно обновлять статистики базы данных MS SQL.
Для обновления статистик по всем таблицам базы данных необходимо выполнить следующий SQL запрос:
Обновление статистик не приводит к блокировке таблиц, и не будет мешать работе других пользователей. Статистика может обновляться настолько часто, насколько это необходимо. Следует учитывать, что нагрузка на сервер СУБД во время обновления статистик возрастет, что может негативно сказаться на общей производительности системы.
Оптимальная частота обновления статистик зависит от величины и характера нагрузки на систему и определяется экспериментальным путем. Рекомендуется обновлять статистики не реже одного раза в день.
Приведенный выше запрос обновляет статистики для всех таблиц базы данных. В реально работающей системе разные таблицы требуют различной частоты обновления статистик. Путем анализа планов запроса можно установить, какие таблицы больше других нуждаются в частом обновлении статистик, и настроить две (или более) различных регламентных процедуры: для часто обновляемых таблиц и для всех остальных таблиц. Такой подход позволит существенно снизить время обновления статистик и влияние процесса обновления статистики на работу системы в целом.
Запустите MS SQL Server Management Studio и подключитесь к серверу СУБД. Откройте папку Management и создайте новый план обслуживания:
Создайте субплан (Add Sublan) и назовите его «Обновление статистик». Добавьте в него задачу Update Statistics Task из панели задач:
Настройте расписание обновления статистик. Рекомендуется обновлять статистики не реже одного раза в день. При необходимости частота обновления статистик может быть увеличена.
Настройте параметры задачи. Для этого следует два раза кликнуть на задачу в правом нижнем углу окна. В появившейся форме укажите имя базу данных (или несколько баз данных) для которых будет выполняться обновление статистик. Кроме этого вы можете указать для каких таблиц обновлять статистики (если точно неизвестно, какие таблицы требуется указать, то устанавливайте значение All).
Обновление статистик необходимо проводить с включенной опцией Full Scan.
Сохраните созданный план. При наступлении указанного в расписании срока обновление статистик будет запущено автоматически.
Очистка процедурного КЭШа
Оптимизатор MS SQL Server кэширует планы запросов для их повторного выполнения. Это делается для того, чтобы экономить время, затрачиваемое на компиляцию запроса в том случае, если такой же запрос уже выполнялся и его план известен.
Возможна ситуация, при которой MS SQL Server, ориентируясь на устаревшую статистическую информацию, построит неоптимальный план запроса. Этот план будет сохранен в процедурном КЭШе и использован при повторном вызове такого же запроса. Если Вы обновили статистику, но не очистили процедурный кэш, то SQL Server может выбрать старый (неоптимальный) план запроса из КЭШа вместо того, чтобы построить новый (более оптимальный) план.
Таким образом, рекомендуется всегда после обновления статистик очищать содержимое процедурного КЭШа.
Для очистки процедурного КЭШа MS SQL Server необходимо выполнить следующий SQL запрос:
Этот запрос следует выполнять непосредственно после обновления статистики. Соответственно, частота его выполнения должна совпадать с частотой обновления статистики.
Настройка очистки процедурного КЭШа
для (MS SQL 2005)
Поскольку процедурный КЭШ необходимо очищать при каждом обновлении статистики, данную операцию рекомендуется добавить в уже созданный субплан «Обновление статистик». Для этого следует открыть субплан и добавить в его схему задачу Execute T-SQL Statement Task. Затем следует соединить задачу Update Statistics Task стрелочкой с новой задачей.
В тексте созданной задачи Execute T-SQL Statement Task следует указать запрос «DBCC FREEPROCCACHE»:
Дефрагментация индексов
При интенсивной работе с таблицами базы данных возникает эффект фрагментации индексов, который может привести к снижению эффективности работы запросов.
Рекомендуется регулярное выполнение дефрагментации индексов. Для дефрагментации всех индексов всех таблиц базы данных необходимо использовать следующий SQL запрос (предварительно подставив имя базы):
Дефрагментация индексов не блокирует таблицы, и не будет мешать работе других пользователей, однако создает дополнительную нагрузку на SQL Server. Оптимальная частота выполнения данной регламентной процедуры должна подбираться в соответствии с нагрузкой на систему и эффектом, получаемым от дефрагментации. Рекомендуется выполнять дефрагментацию индексов не реже одного раза в день.
Возможно выполнение дефрагментации для одной или нескольких таблиц, а не для всех таблиц базы данных.
Настройка дефрагментации индексов (MS SQL 2005)
В ранее созданном плане обслуживания создайте новый субплан с именем «Дефрагментация индексов». Добавьте в него задачу Reorganize Index Task:
Задайте расписание выполнения для задачи дефрагментации индексов. Рекомендуется выполнять задачу не реже одного раза в неделю, а при высокой изменчивости данных в базе еще чаще – до одного раза в день.
Настройте задачу, указав базу данных (или несколько баз данных) и выбрав необходимые таблицы. Если точно неизвестно, какие таблицы следует указать, то устанавливайте значение All.
Реиндексация таблиц включает полное перестроение индексов таблиц базы данных, что приводит к существенной оптимизации их работы. Рекомендуется выполнять регулярную переиндексацию таблиц базы данных. Для реиндексации всех таблиц базы данных необходимо выполнить следующий SQL запрос:
Реиндексация таблиц блокирует их на все время своей работы, что может существенно сказаться на работе пользователей. В связи с этим реиндексацию рекомендуется выполнять во время минимальной загрузки системы.
После выполнения реиндексации нет необходимости делать дефрагментацию индексов.
В ранее созданном плане обслуживания создайте новый субплан с именем «Дефрагментация индексов». Добавьте в него задачу Rebuild Index Task:
Задайте расписание выполнения для задачи реиндексирования таблиц. Рекомендуется выполнять задачу во время минимальной нагрузки на систему, не реже одного раза в неделю.
Настройте задачу, указав базу данных (или несколько баз данных) и выбрав необходимые таблицы. Если точно неизвестно, какие таблицы следует указать, то устанавливайте значение All.
Реиндексация таблиц базы данных
Необходимо осуществлять регулярный контроль выполнения регламентных процедур на уровне СУБД. Ниже приведен пример контроля выполнения плана обслуживания для MS SQL Server 2005.
Откройте созданный вами план обслуживания и выберите из контекстного меню пункт «View History»:
Откроется окно с протоколом выполнения всех заданных регламентных процедур.
Успешно выполненные задачи и задачи, выполненные с ошибками, будут помечены соответствующими иконками. Для задач, выполненных с ошибками, доступна подробная информация об ошибке.
Передача команд 1С на выполнение через ссылки в письме. web-сервисы помогают интегрировать 1С с различными программами, делая её более гибкой. Статей в интеренете достаточно можно, но в основном там описывается выгрузка из 1С, обмен между двумя 1С или 1С и каким-то мощным программным продуктом написанным на C или других языках.
Для меня же была поставлена задача возможности управление 1С через браузер. Как пример: обрабатывать завершение задачи БП в 1С по ссылке в письме (примерно такого типа http://site.ru/?user=000000001&bp=000000555, т.е. отсюда видно, что пользователь 000000001 хочет закрыть задачу 000000555), т.е. пользователь со своего смартфона не имеющего доступа к 1С как таковому, должен получить возможность управлять ею извне. Собственно, более сложной задачей можно поставить написание собственных web-форм, более легких и компактных, с произвольным дизайном для управления 1С.
Задача с точки зрения написания кода 1С очень легкая. Основная сложность заключалась в освоении HTML и JavaScript для управления извне. Начальные знаний по этому вопросу я подчерпнул из статьи Примеры пользования web сервисов 1С из браузера.
Настройка 1С
Для возможности использовать 1С в вебе необходимо:
1. Установить модуль расширения веб-сервера;
Программирование 1С
Теперь можно приступить к конфигурированию.
1. Создадим Web-сервис Input:
1.1. Input имеет операцию InputData которая принимает два параметра: User и Command, и возвращает параметр типа "boolean (http://www.w3.org/2001/XMLSchema)". Текст функции InputData:
1.2. Устанавливаем для Input URI пространства имен = "http://infostart.ru". Здесь может быть любое уникальное имя, обычно это ссылка на сайт.
1.3. Устанавливаем для Input имя файла публикации = "input.1cws". Это имя web-сервиса к которому будем устанавливать соединение.
2. Для наглядности примера создадим справочник Данные, все параметры оставим по умолчанию.
3. Публикуем нашу конфигурацию и web-сервис: Администрирование -> Публикация на веб сервере...
На этом конфигурирование заканчивается, всё остальное сделает за нас 1С.
Разработка HTML страницы
Эта часть далась для меня тяжело, т.к. я ещё только делаю первые шаги в этой теме. Буду рад замачаниям и советам. А так, я постараюсь объяснить всё на пальцах тем, кто как и я знаком по большей части с 1С.
После установки ISS (я уже давал ссылку в начале статьи) на диске C появится каталог C:\inetpub\wwwroot, в этом каталоге располагается сайт. Для локальной машины (на которой установили ISS) он виден так http://localhost/, ну а для пользователей извне, как-то так http://infostart.ru (по правде там немного сложнее, но не суть, мы сейчас не про это). Заглавная страница сайта будет грузиться из файла index.htm каталога C:\inetpub\wwwroot
 Функция получение содержимого адреса url (веб-страницы) методом GET
Функция получение содержимого адреса url (веб-страницы) методом GET  , остается использовать stunnel или CDO:
, остается использовать stunnel или CDO:
.gif)

 Что у нас в 1с Предприятии 8.2 имеется для распараллеливания & это фоновые задачи. Метод, который будет вызываться в фоновой задаче, должен быть прописан в серверном общем модуле и быть экспортным. Естественно нам понадобиться в фоновую задачу передавать и забирать значения.
Что у нас в 1с Предприятии 8.2 имеется для распараллеливания & это фоновые задачи. Метод, который будет вызываться в фоновой задаче, должен быть прописан в серверном общем модуле и быть экспортным. Естественно нам понадобиться в фоновую задачу передавать и забирать значения. 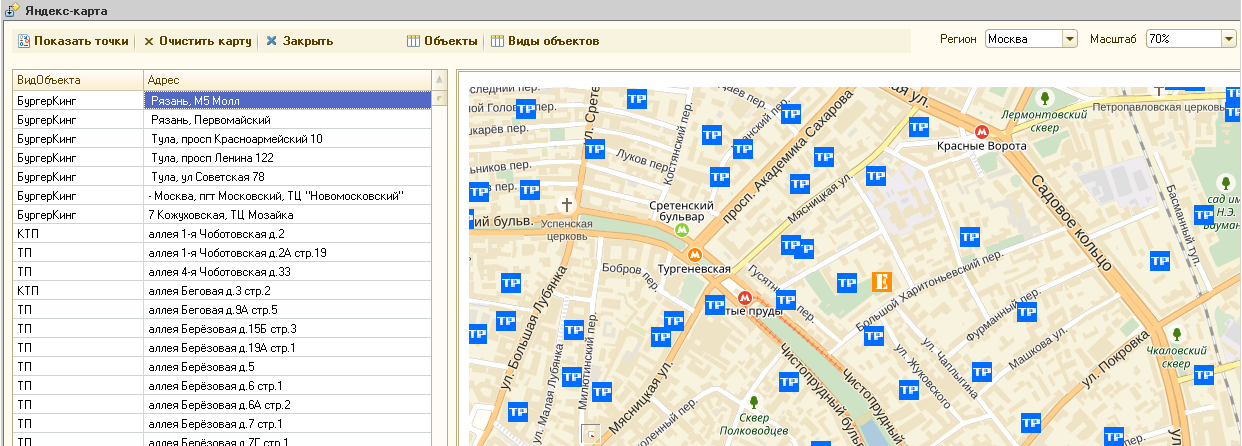







 Планируется, что он будет использоваться для создания приложений параллельно с текущим инструментом (конфигуратором). При этом формат разрабатываемых приложений будет полностью соответствовать текущим версиям 1С:Предприятия 8. Преимуществами нового инструмента разработки являются: интегрированная среда разработки (соответствие современным тенденциям и требованиям), быстрое развитие инструментов разработки, возможность расширения инструментов разработки. В DT заложена принципиально новая архитектура, которая обеспечивает большой запас развития для реализации различных механизмов автоматизации разработки и повышения удобства разработки. В ознакомительной версии возможности этой архитектуры задействованы только в небольшой части. В данный момент важно реализовать функциональность, аналогичную конфигуратору, но основное предназначение DT в возможности создания новых мощных инструментов для разработчика.
Планируется, что он будет использоваться для создания приложений параллельно с текущим инструментом (конфигуратором). При этом формат разрабатываемых приложений будет полностью соответствовать текущим версиям 1С:Предприятия 8. Преимуществами нового инструмента разработки являются: интегрированная среда разработки (соответствие современным тенденциям и требованиям), быстрое развитие инструментов разработки, возможность расширения инструментов разработки. В DT заложена принципиально новая архитектура, которая обеспечивает большой запас развития для реализации различных механизмов автоматизации разработки и повышения удобства разработки. В ознакомительной версии возможности этой архитектуры задействованы только в небольшой части. В данный момент важно реализовать функциональность, аналогичную конфигуратору, но основное предназначение DT в возможности создания новых мощных инструментов для разработчика.






























 Писать парсер rss для 1С
Писать парсер rss для 1С ИсточникиRSS - URL на RSS, ДанныеRSS - сюда записываются загруженные данные новостей
ИсточникиRSS - URL на RSS, ДанныеRSS - сюда записываются загруженные данные новостей







 Если в работающей системе наблюдаются какие-либо симптомы проблем с производительностью, следует проверить, что в системе правильно настроены и регулярно выполняются все рекомендуемые регламентные операции на уровне СУБД.
Если в работающей системе наблюдаются какие-либо симптомы проблем с производительностью, следует проверить, что в системе правильно настроены и регулярно выполняются все рекомендуемые регламентные операции на уровне СУБД. Создайте субплан (Add Sublan) и назовите его «Обновление статистик». Добавьте в него задачу Update Statistics Task из панели задач:
Создайте субплан (Add Sublan) и назовите его «Обновление статистик». Добавьте в него задачу Update Statistics Task из панели задач:















