Я думаю, все сталкивались с однолистовым excel файлом из 1С, у которого на первый взгляд, нет возможности добавить листы. Все не так страшно - их просто скрыли или, что чаще всего - даже не отображали (обусловлено созданием файла из стороннего приложения, например 1С)
Вот и все. Но бывает так, что вы и не увидите их сразу. Если после отображения ярлычков, ярлычки так и не отобразились, следует проверить длину полосы прокрутки и если она является максимальной, то навести указатель мыши на левую границу полосы прокрутки(рис.1),
нажать левую кнопку мыши и не отпуская её потянуть вправо(рис.2).
В отличие от яндекс карт в GMaps можно использовать панорамы - за что им большой плюс! Надеюсь в яндексе прочитают этот пост и тоже когда-нибудь это сделают!
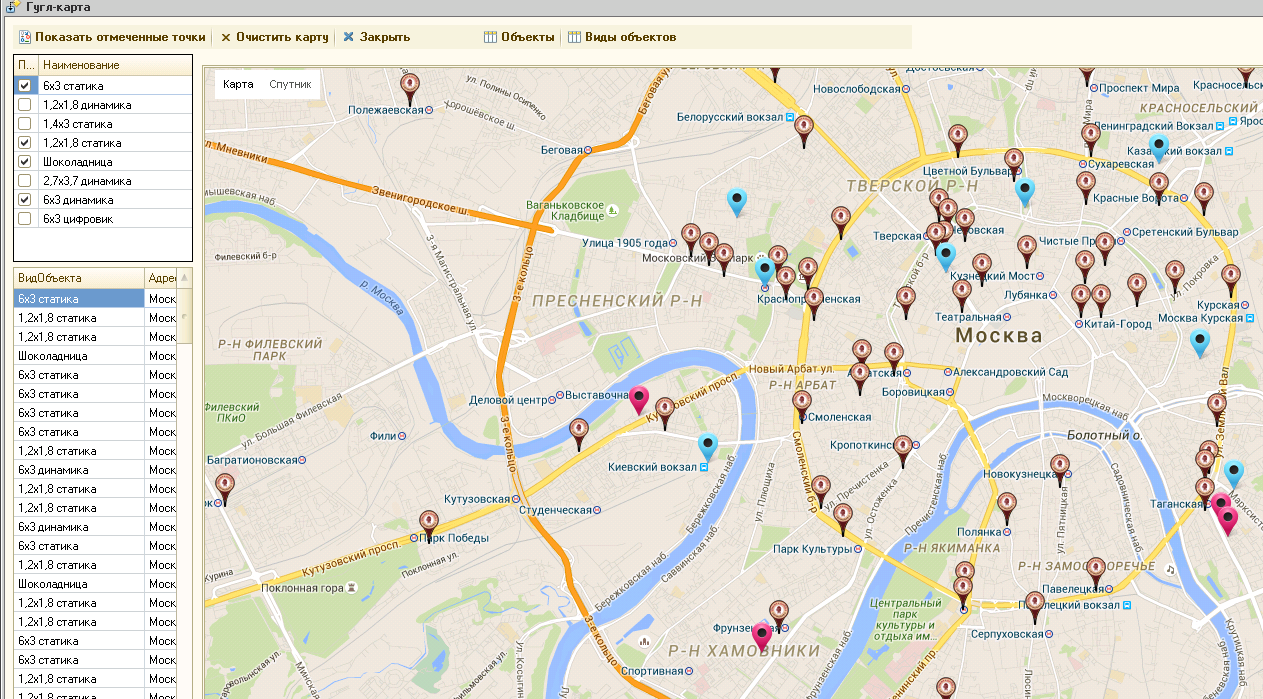
Для клиента нужно было сделать вывод объектов на карту
* проверям, что в созданном файлике /var/www/html/baza/default.vrd и нет лишних (двойных) "/" . У меня они каждый раз появлялись и каждый раз мне проще было их удалить чем вникать, где в команде я напортачил. (также стоит проверить /etc/httpd/conf/httpd.conf, база прописывается в самый конец конфига).
4) ставишь на папку права для пользователя apache: chown apache:apache /var/www/html/baza и перезагружаешь апач.
Проблема в том, что 64-битный апач не хочет работать ( нужно заменить его на 32-битный!
Порядок действий такой:
1. Нужно подкорректировать файлы репозитария, чтобы он загружал 32-битные версии: Открываем /etc/yum.repos.d/, копируете эти файлы для архива и исправляете в текущих $basearch на i686.
2. чистим кэш так: yum clean all или в папке /var/cache/yum/
3. yum install httpd.i686
4. reboot
После перезапуска
./webinst -apache22 -wsdir base -dir '/var/www/html/base/' -connStr 'Srvr=5.101.113.142;Ref=tur;' -confPath /etc/httpd/conf/httpd.conf
При обновлении бухгалтерии, на этапе сохранения, получил следующую ошибку:
Каталог не обнаружен 'v8srvr://sql/acc_main/configsave/e0666db2-45d6-49b4-a200-061c6ba7d569.6b9d6525-ee94-4e13-b73d-82d3e8e8441d'
по причине: Каталог не обнаружен 'ConfigSave\e0666db2-45d6-49b4-a200-061c6ba7d569.6b9d6525-ee94-4e13-b73d-82d3e8e8441d'
по причине: Ошибка СУБД: Microsoft SQL Server Native Client 11.0: Журнал транзакций для базы данных "acc_main" переполнен. Причина: "LOG_BACKUP". HRESULT=80040E14, SQLSrvr: SQLSTATE=42000, state=2, Severity=11, native=9002, line=1
Идем на сервер и первым делом проверяем место на дисках,
А оно закончилось нужно потом почистить хард или увеличивать объем, а пока порежем лог
Открываем SQL Server Management Studio
Это ошибка Microsoft SQL Server - переполняется лог транзакций и не очищается. Урезать его возможно различными способами, в том числе и с помощью стандартной оснастки, но не всегда данная операция получается, и размер файла лога остается прежним. Как вариант предлагаю следующее решение из двух строчек( где acc_main - название базы Бух)
Результат выполнения:
Тоже самое можно сделать вручную:
Шаг 1. Установить модель восстановления Простая (Simple). Правой кнопкой на базе - Свойства(Properties) - Параметры(Options) - 4-й сверху пункт Модель восстановления(Recovery model) - Простая(Simple) - OK.
Шаг 2. Выполнить шринк (сжатие) лога транзакций. Правой кнопкой на базе - Задачи(Tasks) - Сжать(Shrink) - Файлы(Files) - установить Тип файла(File type) - Журнал(Log) - в Операция сжатия(Shrink action) - выбрать Реорганизовать страницы, перед тем осводить неиспользуемое место(Reorganize pages before releseasing unused space) - Сжать файл (Shrink file to) - указать приемлемый размер лога.
Шаг 3. Установить модель восстановления Полная(Full). Правой кнопкой на базе - Свойства(Properties) - Параметры(Options) - 4-й сверху пункт Модель восстановления(Recovery model) - Полная(Full) - OK.
В дополнении скажу, что можно сохранить лог в файл и выполнить шринк так(BaseDB - имя базы данных):
Недавно, мой постоянный клиент решил проводить маркетинговые исследования по изменению цен на товары у конкурентов... и эти данные захотел использовать в 1С в связке с его прайс-листом + куча отчетов с графиками и процентным отклонением от цен основного конкурента
В результате этого, была написана обработка собирающая данные со страниц разных сайтов. Из целей конфиденциальности - сайты раскрывать не буду...
Вид обработки загрузки данных с сайта в 1С
Ниже код загрузки данных со страницы сайта, смысл такой :
в функция передается адрес страницы сайта
полученный текст страницы обрабатывается, удаляются теги
из полученного текста формируется ТЗ с данными
По названию ищется поставщик из вспомогательного справочника Справочники.Pr_Поставщики.НайтиПоНаименованию(, если нет - создается
на выходе ТЗ с данными
В коде используется вспомогательная функция ПолучитьМассивИзСтрокиСРазделителем
Конечно, перед тем как мы начали это делать - прошерстили интернет и нашли несколько решений , вот они:
Считать данные из двоичного файла можно при помощи функции ДвоичныеДанные(ИмяФайла). Например:
или через ADODB.Stream
Двоичные данные и кодировка Base64 в 1С 8.Х
Считать данные из двоичного файла можно при помощи функции
ДвоичныеДанные(ИмяФайла). Например:
Здесть ДД - специальный объект, который называется "двоичные данные".
В языке 1С есть функция, которая преобразует двоичные данные в строку
Base64Строка(ДвоичныеДанные). Например:
Здесть Строка64 - обычная строка, с которой можно делать все, что угодно.
В конце статьи приведена функция Преобразовать64(Строка64 = неопределено, Массив64 = неопределено), которая преобразовывает строку в массив байтов, и обратно.
Для того, чтобы получить массив байтов из строки, вызываем ее так:
Для обратного преобразования вызываем так:
Преобразовать строку в двоичные данные можно при помощи функции Base64Значение(Строка64)
Все указанные функции, кроме Преобразовать64, являются встроенными функциям платформы.
В данном посте хочу коснуться основных аспектов построения оптимального маршрута с использованием API Google maps. Исходные данные для построения маршрута:
* Географические координаты объектов, которые хранятся в базе;
* Координаты начальной и конечной точек маршрута.
В процессе решения задачи был использован пример API Google maps, так же само описание использование массива точек для построения оптимального маршрута.
Для построения оптимального маршрута, необходимо сформировать HTML-код, который будет показан в элементе управления вида «Поле HTML документа».
Во время формирования HTML-кода в него пишутся координаты объектов, которые надо посетить. В нашем случае это строковая переменная МассивОбъектовПосещения, в которой храниться массив объектов посещения. Каждый объект посещения это элемент, который заполняется по примеру: ['Объект посещения', '49.438022, 32.069693'] (первый элемент – описание объекта, второй – географические координаты объекта). Переменная МассивОбъектовПосещения в коде инициализируется следующим образом:
Для построения оптимального маршрута используется вызов функции directionsService.route(), в которую необходимо передать параметры поиска. Параметры передаются следующие:
* origin – точка, с которой будет начинаться маршрут
* destination – точка, в которой будет заканчиваться маршрут
* waypoints – массив точек, которые надо обойти
* optimizeWaypoints – признак возможности оптимизации точек в массиве. В нашем случае необходимо определить его в true, тогда для алгоритма будет не важен порядок обхода точек.
* travelMode – признак того, какой вид транспорта используется. Мы ищем маршрут для автомобиля, поэтому необходимо установить значение google.maps.TravelMode.DRIVING.
После вызова функции directionsService.route() необходимо проверить результат построения (status == google.maps.DirectionsStatus.OK). Затем в цикле обходим составляющие маршрута и выводим информацию про маршрут в правую панель. В коде, приведенном ниже, цикл обхода: for (var i = 0; i < route.legs.length; i++) {}. Инициализация строковой переменной СтраницаХТМЛ, которая отображается в элементе управления с видом «Поле HTML документа», происходит следующим образом:
Microsoft Internet Explorer
Для работы с веб-клиентом в операционной системе Windows XP SP 2 требуется наличие системной библиотеки jscript.dll версии 5.6.0.8834 или выше. Библиотека находится в каталоге system32 операционной системы. Если на вашем компьютере установлена более раняя версия библиотки, то возможно значительное замедление работы веб-клиента. Для обновления версии необходимо скачать пакет обновлений. Находящийся по адресу http://support.Microsoft.com/kb/942840/en-us.
Для начала работы необходимо выполнить следующие настройки подключения:
· открыть браузер, в меню Сервис (Tools) выбрать пункт Свойства обозревателя (Internet Options).
· в открывшемся окне перейти на закладку Безопасность (Security).
· нажать кнопку Другой (Custom level…).
· в открывшемся окне в разделе Сценарии (Scripting) для параметра Активные сценарии (Active scripting) установить Разрешить или Включить (Enable) и нажать ОК.
· перейти на закладку Конфиденциальность (Privacy) и с помощью регулятора выбрать уровень использования cookies умеренный или Средний (Medium) (рекомендуется не выше Умеренно высокий (Medium High).
· на этой же закладке в разделе Блокирование всплывающих окон (Pop-up Bloker) снять флажок Блокировать всплывающие окна или Включить блокирование всплывающих окон (Blok Pop-ups или Turn on Pop-up Blocker).
Mozilla Firefox - Настройки подключения
Для начала работы необходимо выполнить следующие настройки:
· Открыть браузер. В меню Инструменты (Tools) выбрать пункт Настройки (Options).
· В открывшемся окне перейти в раздел Содержимое (Content).
· Снять флажок Блокировать всплывающие окна (Block pop-up Windows).
· Установить флажок Использовать JavaScript (Enable JavaScript).
· Перейти в раздел Приватность (Privacy) и установить флажок Принимать cookies с сайтов (Assept cookies from sites).
Автоматическая аутентификация
Для браузера Mozilla Firefox имеется возможность сконфигурировать веб-браузер для использования автоматической аутентификации ОС. Для этого необходимо выполнить следующие настройки:
· в адресной строке браузера набрать Aboutconfig
· затем на странице настроек в строке фильтра ввести название параметра.
Данная настройка осуществляется для трех параметров:
a) network.automatic-ntlm-auth.trusted-uris,
b) network.negotiate-auth.delegation-uris,
c) network.negotiate-auth.trusted-uris.
· Далее задать список веб-серверов, через которые будет осуществляться работа с базой «1С-Предприятия».
Данные, которые определяют логику функционирования системы на базе 1С:Предприятия, относятся к информационной базе. Хранение информационной базы осуществляется в базе данных с виде набора таблиц, для чего 1С:Предприятие 8.1 может использовать одну из четырех систем управления базами данных (СУБД): * Встроенную в 1С:Предприятие 8.1 (файловый вариант информационной базы). В этом случае все данные информационной базы хранятся в файле с именем 1Cv8.1CD. Этот файл имеет двоичный формат и по сути является базой данных для встроенной в 1С:Предприятие 8.1 СУБД. * Microsoft SQL Server (клиент-серверный вариант информационной базы). Все данные информационной базы хранятся в базе данных Microsoft SQL Server. * PostgreSQL (клиент-серверный вариант информационной базы). Все данные информационной базы хранятся в базе данных PostgreSQL. * IBM DB2 (клиент-серверный вариант информационной базы). Все данные информационной базы хранятся в базе данных IBM DB2.
На уровне объектов базы данных (таблиц, полей, индексов и т. п.) как файловый так и клиент-серверный вариант информационной базы имеют сходный формат (отличающийся несущественными деталями). Некоторая информация об этом формате содержится ниже.
Вся информационная база представляется в базе данных в виде набора таблиц. Среди них есть несколько таблиц, которые обязательно присутствуют в представлении любой информационной базы:
* Config - основная конфигурация информационной базы. Эта конфигурация соответствует реальной структуре данных и используется 1С:Предприятием 8.0 в режиме Предприятия. * ConfigSave - конфигурация, редактируемая Конфигуратором. Конфигурация из ConfigSave переписывается в Config при выполнении "Обновления конфигурации базы данных" в Конфигураторе, а наоборот - при выполнении в Конфигураторе операции "Конфигурация - Конфигурация базы данных - Вернуться к конфигурации БД". * Files содержит служебную информацию, например, о работе с хранилищем конфигурации. * Params содержит параметры информационной базы. Среди них: => Список пользователей информационной базы. => Национальные настройки информационной базы. => Таблица соответствия объектов метаданных и объектов базы данных (таблиц, полей, индексов). => Некоторая другая информация. * _YearOffset - смещение дат в базе данных. Эта таблица создается только при использовании Microsoft SQL Server. * DBSchema содержит информацию о структуре базы данных 1С:Предприятия и определяет другие объекты базы данных, используемые данной информационной базой.
При старте 1С:Предприятие проверяет наличие в информационной базе перечисленных таблиц и в случае отсутствия какой-нибудь из них выдается сообщение "информационная база разрушена". Отсутствие всех перечисленных таблиц означает, что информационная база пустая. В последнем случае эти таблицы будут созданы.
Перечень и структура других таблиц базы данных определяется конкретной конфигурацией, а именно, определенными в ней объектами метаданных. Имя каждой таблицы состоит из буквенного префикса и следующего за ним номера. Префикс определяет назначение таблицы, а номер позволяет различать таблицы одинакового назначения, относящиеся к разным объектам метаданных. Если в качестве СУБД используется IBM DB2, то описанную структуру имеют не имена таблиц, а их псевдонимы.
Если в конфигурации определен хотя бы один план обмена с установленным флагом "Распределенная информационная база", то будут созданы следующие таблицы:
* _ConfigChangeRec - таблица регистрации изменений объектов конфигурации. * _ConfigChangeRec_ExtProps - таблица имен файлов измененных внешних свойств объектов конфигурации.
Ниже перечислены различные объекты метаданных, которым могут соответствовать те или иные таблицы.
* Константы => _Consts содержит текущие значения всех констант, определенных в конфигурации. => _ConstsChangeRec - таблица регистрации изменений констант. Создается, если хотя бы одна константа участвует хотя бы в одном плане обмена. * Планы обмена => _Node<n> - таблица плана обмена. => _Node<n>_VT<k> - табличная часть плана обмена, создается для каждой табличной части. * Справочники => _Reference<n> - таблица справочника. => _Reference<n>_VT<k> - табличная часть справочника - для каждой табличной части. => _ReferenceChangeRec<n> - таблица регистрации изменений справочника. Создается, если справочник участвует хотя бы в одном плане обмена. * Документы => _Document<n> - таблица документов для каждого объекта метаданных "документ". => _Document<n>_VT<k> - табличная часть документа - для каждой табличной части каждого документа. => _DocumentChangeRec<n> - таблица регистрации изменений объекта метаданных типа "документ". Создается для каждого объекта метаданных типа "документ", если он участвует хотя бы в одном плане обмена. * Последовательности документов => _Sequence<n> - таблица регистрации документов - для каждой последовательности. => _SequenceBoundary<n> - таблица границ последовательности - для каждой последовательности. => _SequenceChangeRec<n> - таблица регистрации изменений последовательности. Создается для каждой последовательности, которая участвует хотя бы в одном плане обмена. * Журналы документов. => _DocumentJournal<n> - таблица журнала документов, создается для каждого журнала документов. * Перечисления => _Enum<n> - таблица перечисления - по одной для каждого перечисления. * Планы видов характеристик => _Chrc<n> - основная таблица плана видов характеристик. => _Chrc<n>_VT<k> - табличная часть плана видов характеристик - для каждой табличной части. => _ChrcChangeRec<n> - таблица регистрации изменений плана видов характеристик. Создается, если план видов характеристик участвует хотя бы в одном плане обмена. * Планы счетов => _Acc<n> - основная таблица плана счетов. => _Acc<n>_ExtDim<k> - таблица видов субконто плана счетов, создается для плана счетов в том случае, если максимальное количество субконто больше нуля. => _Acc<n>_VT<k> - табличная часть плана счетов, создается для каждой табличной части плана счетов. => _AccChangeRec<n> - таблица регистрации изменений плана счетов. Создается, если план счетов участвует хотя бы в одном плане обмена. * Планы видов расчета => _CalcKind<n> - основная таблица плана видов расчета. => _CalcKind<n>_BaseCK - таблица базовых видов расчета, создается для плана видов расчета в случае, если его свойство "Зависимость от базы" имеет значение, отличное от "Не зависит". => _CalcKind<n>_DisplacedCK - таблица вытесняемых видов расчета, создается для плана видов расчета в случае, если у него установлен флаг "Использует период действия". => _CalcKind<n>_LeadingCK - таблица ведущих видов расчета - для каждого плана видов расчета. => _CalcKindDN<n> - вспомогательная таблица для порядка вытеснения, создается, если у плана видов расчета установлен флаг "Использует период действия". => _CalcKind<n>_VT<k> - табличная часть плана видов расчета, создается для каждой табличной части. => _CalcKindChangeRec<n> - таблица регистрации изменений плана видов расчета. Создается, если план видов расчета участвует хотя бы в одном плане обмена. * Регистры сведений => _InfoReg<n> - таблица движений регистра сведений. => _InfoRegChangeRec<n> - таблица регистрации изменений регистра сведений. Создается, если регистр сведений участвует хотя бы в одном плане обмена. * Регистры накопления => _AccumReg<n> - таблица движений регистра накопления. => _AccumRegTotals<n> - таблица итогов регистра накопления, если регистр поддерживает остатки. => _AccumRegTurnovers<n> - таблица оборотов регистра накопления, если регистр поддерживает обороты. => _AccumRegChangeRec<n> - таблица регистрации изменений регистра накопления. Создается, если регистр накопления участвует хотя бы в одном плане обмена. => _AccumRegOptions - таблица настроек хранения итогов регистров накопления одна на все регистры накопления. * Регистры бухгалтерии => _AccntReg<n> - таблица движений регистра бухгалтерии. => _AccntRegED<n> - таблица значений субконто регистра бухгалтерии, создается в том случае, если он ссылается на план счетов, у которого максимальное количество субконто больше нуля. => _AccTtl0<n> - таблица итогов по счету. => _AccTtl<i><n> - где i от 1 до максимального количества субконто. Таблица итогов по счету с количеством видов субконто равным i. => _AccTtlC<n> - таблица итогов оборотов между счетами, только для регистра бухгалтерии поддерживающего корреспонденцию. => _AccntRegChangeRec<n> - таблица регистрации изменений регистра бухгалтерии. Создается, если регистр бухгалтерии участвует хотя бы в одном плане обмена. => _AccntRegOptions - таблица настроек хранения итогов одна на все регистры бухгалтерии. * Регистры расчета => _CalcReg<n> - таблица движений регистра расчета. => _CalcRegActPer<n> - таблица фактических периодов действия для регистра расчета, создается, если у регистра расчета установлен флаг "Период действия". => _CalcRegChangeRec<n> - таблица регистрации изменений регистра расчета. Создается для каждого регистра расчета, участвующего хотя бы в одном плане обмена. => _CalcRegRecalc<n> - таблица перерасчета регистра расчета, создается для каждого перерасчета. => _CalcRegRecalcChangeRec<n> - таблица регистрации изменений перерасчета. Создается, если перерасчет участвует хотя бы в одном плане обмена. * Бизнес-процессы => _BPRoutePoint<n> - таблица точек маршрута бизнес-процесса для каждого бизнес-процесса. => _BusinessProcess<n> - основная таблица бизнес-процесса. => _BusinessProcess<n>_VT<k> - табличная часть бизнес-процесса для каждой табличной части. => _BusinessProcessChangeRec<n> - таблица регистрации изменений бизнес-процесса. Создается для каждого бизнес-процесса, участвующего хотя бы в одном плане обмена. * Задачи => _Task<n> - основная таблица задачи. => _Task<n>_VT<k> - табличная часть задачи для каждой табличной части. => _TaskChangeRec<n> - таблица регистрации изменений в задачах. Создается для каждого объекта метаданных типа "задача", который участвует хотя бы в одном плане обмена.
При использовании IBM DB2 префиксы псевдонимов таблиц начинаются не с символа подчеркивания, а сразу с буквенной части.
Количество этих таблиц зависит от функциональности конфигурации и может быть достаточно большим. В штатном режиме 1С:Предприятие не выполняет проверку их наличия, а также целостности и непротиворечивости содержащихся в них данных. Поэтому важно, чтобы база данных, в которой размещена информационная база 1С:Предприятия 8.1, была защищена от несанкционированного доступа и ее модификация выполнялась только средствами 1С:Предприятия. Для проверки необходимо использовать функцию "Администрирование - Тестирование и исправление", встроенную в конфигуратор.
Важно также, чтобы резервное копирование и восстановление базы данных, хранящей информационную базу, выполнялось только целиком. С этой целью рекомендуется использование средств резервного копирования баз данных, встроенных в в используемую СУБД. Резервное сохранение файлового варианта информационной базы может быть выполнено копированием файла 1Cv8.1CD.
В конфигураторе есть специальная функция: Администрирование - Выгрузить информационную базу. С ее помощью можно выгрузить в указанный файл (файл выгрузки) все данные, относящиеся к информационной базе, и больше никакие. Обратная ей функция "Загрузить информационную базу" позволяет в текущую информационную базу вместо существующих загрузить все данные из файла выгрузки. Эти функции также можно использовать для резервного копирования данных информационной базы как в файловом так и в клиент-серверном варианте. Как просмотреть структуру таблиц информационной базы?
Если такое происходит, обратите внимание на следующее:
Посмотрите, какой режим восстановления (Recovery) стоит на закладке Options в свойствах базы данных. Он бывает Simple (простой, который требует наименьшего администрирования) или Full (полный, который обеспечивает наилучшую возможность восстановления данных после сбоя). В режиме Full возможен рост журнала транзакций (LDF), поскольку изменения базы данных накапливаются в этом журнале.
Уменьшение журнала транзакций зависит от операции резервного копирования (backup): если не делать резервное копирование, то лог транзакций в режиме Full будет расти.
Обратите внимание на пункт контекстного меню "Shrink Database" (shrink - англ. усадка, усушка, уменьшение). Эта операция уменьшает размер базы данных путем "удаления неиспользуемых страниц" ("remove unused pages").
В свойствах базы данных есть опция "Auto Shrink", которая активизирует автоматическое уменьшение базы, во время периодических проверок неиспользуемого места ("during periodic checks for unused space").
Для базы данных предприятия в свойствах базы я установил опцию Full Recovery. На этой же закладке я установил флажок Auto Shrink. Базу надо периодически архивировать, для чего я настроил автоматическое архивирование базы данных (каждое утро) и журнала транзакций (каждые 10 минут).
Режим восстановления базы данных:
Режимы восстановления базы данных (recovery models) баз данных SQL Server 2005, полное протоколирование (full), неполное протоколирование (bulk-logged), простая модель восстановления (simple)
Одно из важных решений, которые нужно принять при создании базы данных — в каком режиме восстановления будет работать база. Этот параметр выбирается на вкладке Options свойств базы данных в строке Recovery Model (Режим восстановления) (над списком остальных параметров). Изменить режим восстановления базы данных можно также при помощи команды A_lter DATABASE.
Всего предусмотрено три режима восстановления базы данных: Full (режим полного протоколирования) — в этом режиме максимальное количество операций записывается в журнал транзакций. Журнал транзакций автоматически не обрезается. Этот режим обеспечивает максимальные возможности восстановления (за счет снижения производительности). Только в этом режиме вы можете использовать зеркальное отображение баз данных и автоматическую доставку журналов (log shipping). Именно этот режим выбирается по умолчанию для пользовательских баз данных, поскольку он настроен для базы данных model. Если изменить режим восстановления для базы данных model, то для создаваемых баз данных по умолчанию будет выбираться новый режим.
Bulk-logged (режим неполного протоколирования) — это компромисс между требованиями производительности и возможностями восстановления. При использовании этого режима запись в журнал практически отключается (в терминологии Microsoft — проводится минимальное протоколирование) для операций следующих типов:
- массовой вставки (команды BULK I_nsert, S_elect INTO, загрузка средствами bcp и т. п.);
- вставка/изменение больших двоичных данных (text, ntext, image);
- операции по созданию, перестроению и удалению индексов.
Автоматическая перезапись журналов транзакций при этом не производится, работа с транзакциями, не включающими в себя перечисленные операции, производится как обычно.
При работе в этом режиме вы лишаетесь возможности использовать журнал транзакций для восстановления (при утрате файлов данных, на момент времени или на метку транзакции), если в нем была хотя бы одна запись о перечисленных ранее операциях. Microsoft рекомендует не использовать этот режим восстановления на постоянной основе, а переключаться в него из режима Full на время выполнения больших операций массовой вставки, а потом возвращаться обратно.
Simple (простая модель восстановления) — максимальный выигрыш в производительности и удобстве работы за счет возможностей восстановления. Минимально протоколируются те же операции, что и в режиме восстановления Bulk-logged, а кроме этого, журнал транзакций автоматически очищается (блоками, размер которых изначально равен 256 Кбайт, но при необходимости он может быть автоматически увеличен). В результате вы получаете максимальную производительность и возможность не думать о потенциальной нехватке места в журнале транзакций. Но в этом режиме использовать журнал транзакций для восстановления уже не удасться. Вы не сможем даже выполнить резервное копирование журнала транзакций: команда BACKUP LOG в этом режиме сразу вернет ошибку.
Какой же режим восстановления выбрать?
Microsoft (в своих учебных курсах) рекомендует для рабочих баз данных выбирать только режим Full. Однако из опыта проведения автором этих самых учебных курсов и общения со слушателями можно сказать, что очень многие опытные администраторы сознательно настраивают для своих баз данных режим восстановления Simple. Значительное повышение производительности при операциях массовой вставки и при работе с большими двоичными данными вполне оправдывает некоторое снижение возможностей резервного копирования и восстановления. Что важнее для вашей задачи — дополнительные возможности восстановления или максимальная производительность, решать вам. Рост журнала транзакций в 1С MS SQL Server
 Как в excel сохраненный из 1С вставить новый лист?
Как в excel сохраненный из 1С вставить новый лист? 






.gif)

 нужно потом почистить хард или увеличивать объем, а пока порежем лог
нужно потом почистить хард или увеличивать объем, а пока порежем лог



