Иногда возникает необходимость обработать фотографии в 1С автоматически, уменьшить вес картинок в килобайтах, за счет удаления из файла не нужной технической информации и сглаживания цветов, или изменить размер, уменьшить картинку пропорционально задав максимальный размер по ширине или высоте.В этом случае можно:1) установить специальные библиотеки в операционной системе для работы с графикой, н-р GFLAx и подключать их как com-объекты2) использовать api сервисов, таких как optipic.io.
Рассмотрим оба варианта:1) Использование GFLAxСкачиваем и устанавливаем библиотеку GFLAx, скачать можно здесь https://www.xnview.com/en/#downloads
Далее её надо зарегистрировать в Windows. Для этого запускаем CMD.exe с правами администратора и набираем: regsrv32 "путь_к_DLL\GFLAx.dll"Далее уже в программе, для пропорционального изменения размера файла до максимального размера в 500 пикселей можно вставить такой код:
Данный способ требует специальных настроек операционной системы, навыков системного администрирования и данный способ не проводит полноценную оптимизацию картинки.Кроме того, на компьютере или сервере, где производиться оптимизация эта библиотека должна быть установлена.2) Использование сервиса optipic.ioПодобные сервисы обычно платные, но стоимость использования не высокая, а качество и гибкость существенно выше.
Преимущества использования сервиса optipic.io в проектах 1С:
Легко подключить
Не нужно устанавливать дополнительные библиотеки в операционной системе
Можно использовать как для оптимизации изображений, так и для изменения размера изображения в пикселях (ресайз)
Не зависит от операционной системы и типа используемого клиента
Конфигурация будет работать после переезда на другой компьютер или сервер
Качество и эффективность сжатия производятся в самом оптимальном виде
Использование сервиса можно легко встроить в любой свой проект на 1С. Для этого можно добавить себе функцию, в которую передавать имя файла с исходной картинкой и параметры оптимизации. А в качестве ответа получить имя файла уже оптимизированного сервисом.
Пример такой функции для 1C8:
И далее в коде обращаться к данной функции, н-р так
Циклы применяются для выполнения каких либо повторяющихся действий, возможные варианты перебора в цикле:
Перебираем строки с помощью цикла Для каждого
Перебираем строки с помощью цикла Пока
Перебираем строки с помощью цикла Для
Еще вариант, но советую его использовать только в без выходных ситуациях, Если
Примеры циклов
А какой цикл работает быстрее?
Итак, я нашел пять способов, как можно организовать цикл средствами 1С.
Первый вид цикла, назовем его условно «Для По» выглядит так:
Второй вид «Для Каждого»:
Третий «Пока»:
Далее вспомнил ассемблерную молодость & цикл «Если»:
Ну и напоследок «Рекурсия»
Естественно, что относить рекурсию к циклам не совсем корректно, но тем ни менее с её помощью можно добиться похожих результатов. Сразу оговорюсь, что в дальнейшем тестировании рекурсия не участвовала. Во первых все тесты проводились при 1 000 000 итераций, а рекурсия выпадает уже при 2 000. Во вторых скорость рекурсии в десятки раз меньше, чем скорость остальных циклов.
Последнее отступление. Одним из условий было выполнение в цикле каких-либо действий. Во первых пустой цикл используется очень редко. Во вторых цикл «ДляКаждого» используется для какой-либо коллекции, а значит и остальные циклы должны работать с коллекцией, чтобы тестирование проходило в одинаковых условиях.
Ну что ж, поехали. В качестве тела цикла использовалось чтение из заранее заполненного массива.
или, при использовании цикла «Для Каждого»
Тестирование проводилось на платформе 8.3.5.1231 для трех видов интерфейса (Обычное приложение, Управляемое приложение и Такси).
Результаты для 8.3.5.1231
Интерфейс
ДляПо
ДляКаждого
Пока
Если
Обычное приложение
5734,2
4680,4
7235,4
7263,0
Управляемое приложение
5962,4
4882,6
7497,4
7553,6
Такси
5937,2
4854,6
7500,8
7513,0
Числа это время в миллисекундах полученное с помощью функции ТекущаяУниверсальнаяДатаВМиллисекундах(), которую я вызывал до цикла и после его завершения. Числа дробные, потому что я использовал среднее арифметическое пяти замеров. Почему я не использовал Замер производительности? У меня не было цели замерить скорость каждой строчки кода, только скорость циклов с одинаковым результатом работы.
Казалось бы и все, но & тестировать так тестировать!
Результаты для 8.2.19.106
Интерфейс
ДляПо
ДляКаждого
Пока
Если
Обычное приложение
4411,8
3497,2
5432,0
5454,0
Управляемое приложение
4470,8
3584,8
5522,6
5541,0
В среднем платформа 8.2 на 25% быстрее, чем 8.3. Я немножко не ожидал такой разницы и решил провести тест на другой машине. Скажу только, что там 8.2 была быстрее процентов на 20.
Почему? Не знаю, дезасемблировать ядро в мои планы не входило, но в замер производительности я все же заглянул. Оказалось, что сами циклические операции в 8.3 проходят несколько быстрее, чем в 8.2. Но на строке
то есть при считывании элемента коллекции в переменную происходит значительное снижение производительность.
Для себя я сделал несколько выводов:
1. Если есть возможность использовать специализированный цикл & «Для Каждого», то лучше использовать его. Кстати, сам по себе он отрабатывает дольше чем другие циклы, но скорость доступа к элементу коллекции у него на много выше.
2. Если заранее знаешь количество итераций & используй «Для По». «Пока» отработает медленнее.
3. Если использовать цикл «Если» & другие программисты тебя явно не поймут.
В 1С предполагается, что СообщениеПользователю выводятся для того, чтобы сообщить пользователю об ошибках.
А для информирования о выполняемом действии рекомендуется использовать метод встроенного языка ПоказатьОповещениеПользователя().
СообщениеПользователю выводит сообщение пользователю (после окончания обработки) или сохраняет его в очередь, если сообщение невозможно вывести прямо сейчас.
Пример вывода сообщения на клиенте:
При обработке на сервере:
Необходимо зарегистрировать в системе соответствие объекта и имени реквизита формы. Для этого в глобальном контексте реализована функция УстановитьСоответствиеОбъектаИРеквизитаФормы(). Сделать это можно следующим образом:
В данном фрагменте выполняется преобразование объекта из данных формы в реальный объект и устанавливается его соответствие с реквизитом формы по имени "Объект".
Если в дальнейшем требуется создать сообщение, можно сделать это следующим образом:
В этом фрагменте создается новый объект СообщениеПользователю, в котором запоминается Текст сообщения и указывается Поле объекта, ошибка в данных которого вызвала необходимость вывода сообщения. Информация о том, как объект расположен в форме берется из предварительно запомненной пары "Объект/ИмяРеквизитаФормы". В дальнейшем сообщение будет выведено в окно сообщений формы и привязано к соответствующему элементу управления.
Примеры заполнения свойства Поле объекта СообщениеПользователю
ТипШаблонПример
Реквизит
ИмяРеквизита
Контрагент
Табличная часть
ИмяТабличнойЧасти
Скидки
Реквизит табличной части
ИмяТабличнойЧасти[ИндексСтроки].ИмяРеквизита
Номенклатура[10].Количество
Реквизит набора записей
[ИндексСтроки].ИмяРеквизита
[10].Курс
Еще примеры:
ПоказатьОповещениеПользователя - оповещение возникает в правом нижнем углу приложения и сообщает о совершенном действии. В течение нескольких секунд оно постепенно гаснет и пропадает. При этом, если навести на оповещение курсор мышки, оно не гаснет, и есть возможность внимательно его прочитать:
Чтобы провести деноминацию в 1С на 1 июля 2016 года, нужно учесть, что желательно учёт вести в двух суммовых измерениях в белорусских рублях старого и нового образца. Однако, даже если Вы решите упростить задачу и проведёте деноминацию в программе вручную или с помощью обработки на 1 июля, то есть деноминируете итоги в соотношении 1:10000, то получите "кашу" в базе данных. Такие отчёты как ОСВ, акт сверки, карточка счёта, журнал-ордер и все остальные в программе 1С будут воспринимать данную операцию как "логичную". Обороты за период "поплывут", а итоги будут суммировать старые и новые деньги как равнозначные. Поэтому этот вариант исключим сразу.
Пять вариантов решения:
1)Корректный вариант!Разделить базу данных на две. Во второй провести деноминацию 1 июля.
Выполнить доработку форм и метаданных до копеек. Первое полугодие в первой базе оставить как есть. А учёт во втором полугодии, во второй базе, уже начать вести в денежном выражении нового образца. Перед разбиением базы на две, нужно доработать модуль и все метаданные, создать её копию и сделать свёртку обработкой WRAP.ert. Потом, этой же обработкой, в новой базе провести деноминацию - убрать из уже сделанных, во втором квартале, проводок и метаданных "0000". Но есть один недостаток. Разбивая базу на две Вы лишитесь оперативность при получении данных. Теперь, например, для того чтобы построить акт сверки за год по контрагенту - придётся делать это в двух базах! Выбирая этот вариант нужно понимать все нюансы разделения базы на полугодия.
2)Корректный вариант!Проведение деноминации в рабочей базе (без разделения):
Выполнить доработку форм и метаданных до копеек. Создать сторнированные проводоки с учётом коэффициента деноминации 10000 (то есть если на Сч.по Дт.=3.000.000 -> будет сделана проводка Дт. -2.999.700 -> в итоге Сч.Дт=300). Внимание! Нужно иметь ввиду, что отчёты желательно строить в двух экземплярах (до 1 июля и после).
Выполнить доработку форм и метаданных до копеек.
3) Корректный вариант, но очень затратный! Доработать все метаданные 1С для деноминации и провести её на 1 июля 2016 года.
Самый дорогой вариант для предприятия.
В версии 8.2 и 8.3 можно создать дополнительное измерение "сумма в рублях старого образца".
В версии 7.7 на невалютных счетах можно использовать вал.сумму или доп.забалансовый счёт (рубли образца 2009 года).
Плюс ко всему придётся переделать практически все объекты метаданных. Отчеты, справочники, документы, обработки, глобальный(7.7) и общие(8) модули, план счетов, регистры и т.п. Реализовать данный метод смогут лишь крупные предприятия с массивным штатом программистов 1С.
4) Признан некорректным!Продолжить вести учёт в старых денежных единицах.
Совершенно не затратный и для большинства компаний самый оптимальный, так как делать то ничего и не надо. Коротко говоря - оставить всё как есть. В шапке некоторых отчётов, например, акта сверки, для корректности, можно добавить фразу типа этой: "в расчётах используется белорусский рубль образца 2000 года".
5) Признан некорректным!Разделить базу данных на две. Во второй провести деноминацию 1 января.
"Закрыть" период (первое полугодие) в первой базе, чтобы больше не вносить туда изменения. Во второй базе сделать свёртку обработкой WRAP.ert на 1 января. Незабудьте предварительно создать копию. Соответственно с 1 января 2016г. учёт будет деноминированный. Помните, что вносить изменения (если таковые будут) до 01 июля 2016 придётся вносить в обе информационные базы. В начале 2017 можно будет свернуть и обрезать Вашу рабочую базу на 1 июля. Так у Вас будет две базы: 1-я до 1.07.2016 (без деноминации) и 2-я после 1.07.2016 (с деноминацией).
6) Признан некорректным! Доработать только отчёты в 1С для деноминации 1 июля 2016 года.
В отчётах, которыми чаще всего пользуются бухгалтера для отправки данных "внешним" контрагентам (акт сверки, деб.задолженность, отчёт по движению ДС и т.п.), выводить дополнительную строку с коэффициентом 1:10000 под суммой с названием "сумма в белорусских рублях образца 2009 года".
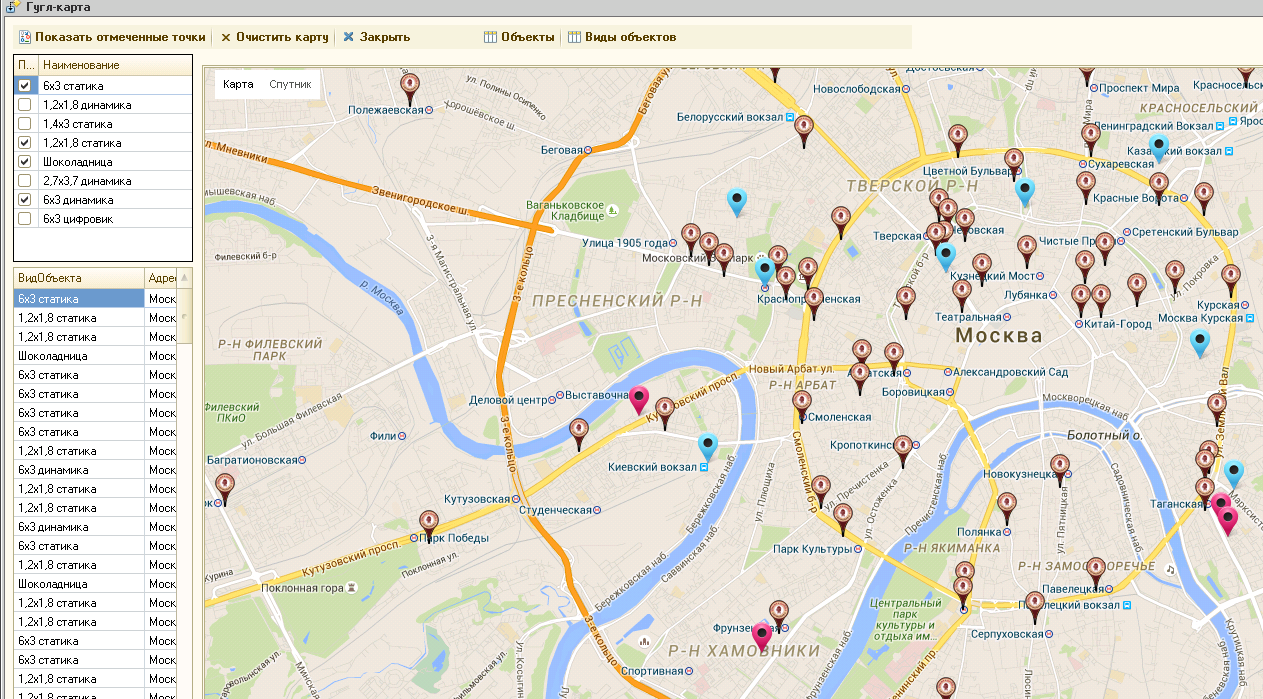
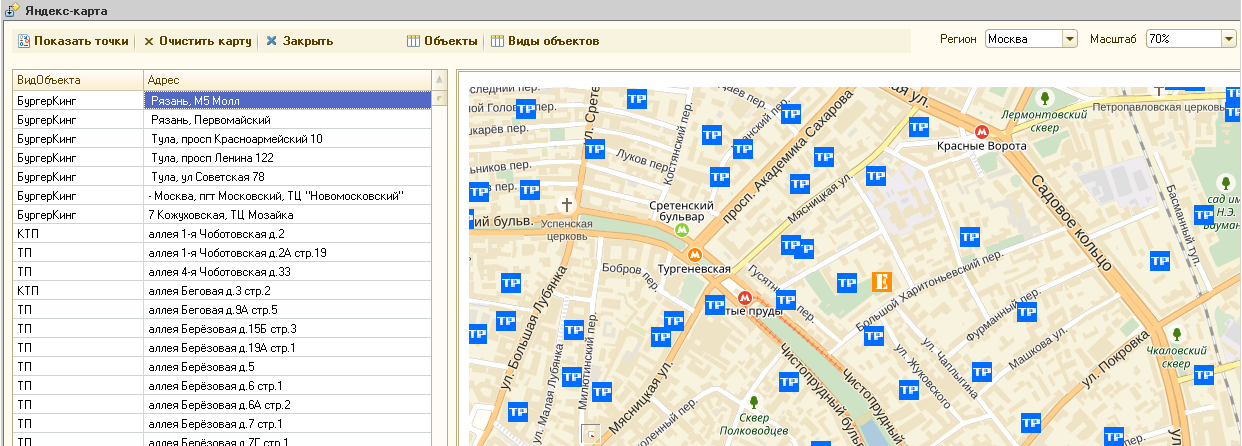
В отличие от яндекс карт в GMaps можно использовать панорамы - за что им большой плюс! Надеюсь в яндексе прочитают этот пост и тоже когда-нибудь это сделают!
Для клиента нужно было сделать вывод объектов на карту
Частенько нужно сообщить пользователю какую-то информацию, раньше использовали Сообщить() или
Для вывода информации пользователю начиная с версии 1С:Предприятия 8.2 существует специальный механизм сообщений. В этом механизме используется объект встроенного языка СообщениеПользователю. Предполагается, что сообщения выводятся для того, чтобы сообщить пользователю об ошибках. А для информирования о выполняемом действии рекомендуется использовать метод встроенного языка ПоказатьОповещениеПользователя().
Пока управление не передано обратно на клиента, можно получить массив сообщений методом глобального контекста ПолучитьСообщенияПользователю().
Нужно сделать РМК (рабочее место кассира) с работающим сканером и другим нужным функционалом.
Порядок действий:
1. Ставим 1с, конфигурацию.
Для начала сделаем пару пользователей, первый он всегда «Админ«, второго назовем «Кассир» и дадим ему полные права (для теста, по хорошему надо настраивать персональные права) .
В конфигураторе (от админа) подправим пользователя «Кассир». Ставим «тип запуска» & «обычное приложение»
Идем дальше, что бы в «Администрировании» появился пункт «Подключаемое оборудование» (иначе как мы его будем настраивать? ) нужно поставить галку на
«Использовать подключаемое оборудование» и «Использовать группы пользователей»
Администрирование & Настройка параметров учета.
Возможности пользователя в РМК настраиваем в Администрировании & Дополнительные права пользователя
2. Настраиваем сканер на эмуляцию com порта, это позволит нам работать в РМК со сканером без лишних заморочек.
Для этого мне потребовалось скачать драйвер Symbol COM Port Emulation Driver v 1.8.5
т.к. проверять уже не охота, а перед установкой драйвера была применена вот эта инструкция:
Настройка_сканеров_Symbol_в_1С прикладываю и ее, в ней показаны штрих кода для программирования сканера на эмуляцию и настройка в 1с сканера.
Ну и в принципе на этом настройка сканера завершена. Теперь в РМК будет перехватывать все сканированные штрихкода.
Все тоже самое только на Windows 7
Сканер установился автоматом. Заставить эмулировать его COM порт я не стал. Сканер работает как клавиатура. Для 1с пришлось настроить сканер что бы он сначала слал F7 (ввод по штриху) + сам штрих + enter.
Прежде чем купить сканер штрих кода обратите особое внимание на то, каким образом будет подключаться сканер к компьютеру.
Несмотря на обилие видов сканеров штрих кода на рынке все они, в конечном счете, подключаются через один из четырех типов коннекторов или интерфейсных портов:
- PS/2 Разрыв клавиатуры – из названия следует что сканер штрих кода подключается в разрыв между компьютером и клавиатурой.
- USB Эмуляция ( фактически подключение через порт usb а настройки как в PS/2)
- RS-232 Последовательный (Com) порт – подключается в Com порт компьютера, однако требует дополнительно блок питания.
- USB Эмуляция ( фактически подключение через порт usb а настройки как в RS-232)
Настройка сканера штрих-кода в программах 1С в разрыв клавиатуры
Настроить сканер штрих-кода 1С, подключаемый в разрыв клавиатуры, совсем не сложная задача. Первое что надо сделать - настроить префикс сканера штрих-кода. По умолчанию сканер штрих-кода, подключаемый в разрыв клавиатуры при сканировании штрих-кода товара он возвращает цифры штрих-кода и символ возврата – это аналогично тому, как если бы вы нажимали после сканирования клавишу ENTER на клавиатуре компьютера. Однако для сканирования штрих – кода товара в программе 1С нажать клавишу F7 - Возврат каретки необходимо. Чтобы постоянно не нажимать F7, нам и поможет добавление специального символа – префикса. Префиксом называется в данном случае некий набор символов, которые сканер отсылает перед отправкой штрих-кода. В качестве префикса в основном используют значение “150” - это ASCII-код клавиши F7. Этот способ подойдет и для USB-сканера в том случае, когда нет возможности установить драйвер эмуляции COM-порта.
Настройка сканера штрих-кода в программах 1С через порт USB.
Программа 1C не видит сканеры штрих-кода подключенные через USB-разъем, зато их прекрасно “видит” операционная система Windows. При первом включении сканера операционная система предложит установить его драйвер, но мы ей этого не позволим и откажемся от автоматической установки, а поставим драйвер вручную. Как правило, драйвер эмуляции COM-порта находится на диске из комплекта поставки сканера штрих-кода, там же есть и специализированные утилиты для настройки свойств самого сканера штрих-кода, такие как: громкость бипера, префикс, суфикс и т.п. Или же имеется специальное руководство пользователя с конфигурационными штрих-кодами, сканируя которые можно определенным образом настроить сканер. В процессе установки этого драйвера, операционная система создает виртуальный COM-порт. Далее нужно произвести конфигурирование порта. После того как настроен сам сканер – переходим к настройке в 1С. Для этого в меню Сервис?Настройки торгового оборудования?Находим закладку Сканеры и переходим в нее и устанавливаем новый сканер штрих-кодов. В качестве обработки обычно используют входящую в поставку стандартную обработку обслуживания «1CScanOPOSScan_v2.epf». Далее заходим в “Параметры” настраиваем COM-порт и параметр Скорость сканера. Сканер штрих-кода настроен!
Настройка сканера штрих кода в программах 1С через COM-порт.
Настройка сканера штрих-кода 1С производим как в предыдущем примере. После того как настроен сам сканер – переходим к настройке в 1С. Для этого в меню Сервис?Настройки торгового оборудования?Находим закладку Сканеры и переходим в нее и устанавливаем новый сканер штрих-кодов. В качестве обработки обычно используют входящую в поставку стандартную обработку обслуживания «1CScanOPOSScan_v2.epf». Далее заходим в “Параметры” настраиваем COM-порт и параметр Скорость сканера. Сканер штрих-кода настроен!
У клиента огромная база клиентов и соответственно огромный штат менеджеров. Дошло до того, что менеджеры в поисках новых клиентов( знакомство, интернет, реклама и т.д.) очень часто звонят одним и тем же клиентам по несколько раз. Стали вести базу звонков... Но в базе одного и того же клиента могли назвать по разному - как-только вздумается...
Понадобился поиск по нечеткому названию и для этого решено было использовать полнотекстовый поиск 1С:
Механизм полнотекстового поиска в 1С позволяет быстро находить необходимую для пользователя информацию. Данный вид поиска особенно эффективен, если информационная база располагает большим объемом информации, а также точно не известно, где находятся интересующие пользователя данные или как часто бывает, их точное название не известно.
Смысл обработки в том, что менеджер копирует названия клиентов в список слева, нажимает Выполнить поиск и справа видит найденных в базе контрагентов (подходящих по нечеткости). Порог нечеткости менеджеры могут устанавливать сами.
Приведу краткий пример реализации данного поиска, код:
Полнотекстовый поиск - позволит найти текстовую информацию, размещенную практически в любом месте используемой конфигурации. При этом искать нужные данные можно либо по всей конфигурации в целом, либо сузив область поиска до нескольких объектов (например, определенных видов документов или справочников). Сами критерии поиска могут варьироваться в довольно широком диапазоне. То есть найти нужные данные можно, даже не помня точно, где они хранятся в конфигурации и как именно записаны.
Полнотекстовый поиск предоставляет следующие возможности:
Есть поддержка транслитерации (написание русских слов символами латиницы в соответствии с ГОСТ 7.79-2000). Пример: "русская фраза" = "russkaya fraza".
Есть поддержка замещения (написание части символов в русских словах одноклавишными латинскими символами). Пример: "руссrfz фраpf" (окончания каждого слова набраны латиницей, допустим, в результате ошибки оператора).
Есть возможность нечеткого поиска (буквы в найденных словах могут отличаться) с указанием порога нечеткости. Пример: указав в строке поиска слово "привет" и нечеткость 17 %, найдем все аналогичные слова с ошибками и без: "привет", "превет", "привед".
Есть возможность указать область выполнения поиска по выбранным объектам метаданных.
Полнотекстовое индексирование названий стандартных полей ("Код", "Наименование" и т. д.) производится на всех языках конфигурации.
Поиск выполняется с учетом синонимов русского, английского и украинского языков.
Морфологический словарь русского языка содержит ряд специфических слов, относящихся к областям деятельности, автоматизируемым с помощью системы программ "1С:Предприятие".
Стандартно в состав поставляемых словарей включены словарные базы и словари тезауруса и синонимов русского, украинского и английского языков, которые предоставлены компанией "Информатик".
Поиск можно осуществлять с использованием подстановочных символов ("*"), а также с указанием поисковых операторов ("И", "ИЛИ", "НЕ", "РЯДОМ") и спецсимволов.
Полнотекстовый поиск можно осуществлять в любой конфигурации на платформе 1С:Предприятие 8
Для того чтобы открыть окно управления полнотекстовым поиском необходимо выполнить следующее:
Обычное приложение - пункт меню Операции - Управление полнотекстовым поиском.
Управляемое приложение - пункт меню Главное меню - Все функции - Стандартные - Управление полнотекстовым поиском.
Обновить индекс – Создание индекса/Обновление индекса;
Очистить индекс – обнуление индекса(рекомендуется после обновления всех данных);
пункт Разрешить слияние индексов – отвечает за слияние основного и дополнительного индекса.
Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.
Как вы можете заметить свойство Использовать установлено для всего справочника Контрагенты, но сделать это можно и для каждого его реквизита соответствующего типа.
Рассмотрим более подробно полнотекстовый индекс, который состоит из двух частей (индексов): основного индекса и дополнительного. Высокая скорость поиска данных обеспечивается за счет основного индекса, но обновление его происходит относительно медленно, в зависимости от объема данных. Дополнительный индекс ему противоположен. Данные добавляются в него намного быстрее, но поиск осуществляется медленнее. Система осуществляет поиск одновременно в обоих индексах. Большая часть данных находится в основном индексе, а данные добавляемые в систему попадают в дополнительный индекс. Пока объем данных в дополнительном индексе небольшой, поиск по нему происходит относительно быстро. В тот момент, когда нагрузка на систему невелика, происходит операция слияния индексов, в результате чего дополнительный индекс очищается, а все данные помещаются в основной индекс. Слияние индексов предпочтительнее выполнять в тот момент времени, когда нагрузка на систему минимальна. С этой целью можно создавать регламентированные задания и задания по расписанию.
Специальные операторы, допустимые при задании поискового выражения
Механизм полнотекстового поиска допускает написание части символов русского слова одноклавишными латинскими символами. Результат поиска при этом не измениться.
Два оператора РЯДОМ
упрощенный. На расстоянии 8 слов друг от друга
РЯДОМ/[+/-]n – поиск данных в одном реквизите на расстоянии n-1 слов между ними.
Знак указывает в каком направлении от первого слова будет поиск второго. (+ - после, - до)
Групповой символ «*» может использоваться только в качестве замены конца слова
Оператор нечеткости «#». Если неизвестно точное написание названия, имени.
Программными средствами и средствами 1с: программирование.
Оператор синонимов «!». Позволяет найти слово и его синонимы
Как программно обновить индекс полнотекстового поиска?
Пример полнотекстового поиска данных
Определение переменной СписокПоиска
Кроме этого в процедуре обработки события ПриОткрыии формы определим, что эта переменная будет содержать список полнотекстового поиска, с помощью которого мы и будем осуществлять поиск в данных
Теперь для события нажатия на кнопку Найти напишем код, который позволит нам выполнять поиск в соответствии с тем выражением, которое задано в поле ПоисковоеВыражение
Сначала в этой процедуре мы устанавливаем поисковое выражение, введенное пользователем, в качестве строки поиска для полнотекстового поиска. Затем выполняем метод ПерваяЧасть(), который собственно запускает полнотекстовый поиск и возвращает первую порцию результатов. По умолчанию порция содержит 20 элементов. После этого мы анализируем количество элементов в списке поиска. Если он не содержит ни одного элемента, то мы выводим в форму соответствующее сообщение. В противном случае вызывается процедура ВывестиРезультатПоиска(), которая отображает полученные результаты пользователю.
Создадим в модуле формы процедуру с таким именем и напишем в ней код,
Действия, выполняемые в этой процедуре, просты. Сначала мы формируем сообщение о том, какие элементы отображены и сколько всего элементов найдено. Затем получаем результат полнотекстового поиска в виде HTML-текста и выводим этот текст в поле HTML-документа, расположенное в форме.
В заключение передаем управление в процедуру ДоступностьКнопок() для того, чтобы сделать доступными или, наоборот, запретить доступ к кнопкам Предыдущая порция и Следующая порция (в зависимости от того, какая порция полученных результатов отображена). Текст этой процедуры представлен в Коде
Теперь необходимо создать обработчики событий нажатия на кнопки ПредыдущаяПорция() и СледующаяПорция().
Заключительным «штрихом» будет создание обработчика события onclick поля HTML-документа, расположенного в форме. Дело в том, что результат полнотекстового поиска, представленный в виде HTML-текста, содержит гиперссылки на номера элементов списка поиска. И нам хотелось бы, чтобы при переходе пользователя на эту ссылку система открывала бы форму того объекта, который содержится в этом элементе списка. Для этого мы будем перехватывать событие onclick HTML-документа, содержащегося в поле HTML-документа, получать номер элемента списка из гиперссылки и открывать форму соответствующего объекта. Текст обработчика события onclick поля HTML-документа представлен в коде
При работе в 1С встречается много рутинных операций которые должны запускаться или формироваться по расписанию выполняя то или иное действие, например: проведение документов или загрузка данных в 1С с сайта.
Механизм заданий предназначен для выполнения какой-либо прикладной или функциональности по расписанию или асинхронно.
Механизм заданий решает следующие задачи:
Возможность определения регламентных процедур на этапе конфигурирования системы;
Выполнение заданных действий по расписанию;
Выполнение вызова заданной процедуры или функции асинхронно, т.е. без ожидания ее завершения;
Отслеживание хода выполнения определенного задания и получение его статуса завершения (значения, указывающего успешность или не успешность его выполнения);
Получение списка текущих заданий;
Возможность ожидания завершения одного или нескольких заданий;
Управление заданиями (возможность отмены, блокировка выполнения и др.).
Механизм заданий состоит из следующих компонентов:
Метаданных регламентных заданий;
Регламентных заданий;
Фоновых заданий;
Планировщика заданий.
Фоновые задания & предназначены для выполнения прикладных задач асинхронно. Фоновые задания реализуются средствами встроенного языка.
Регламентные задания & предназначены для выполнения прикладных задач по расписанию. Регламентные задания хранятся в информационной базе и создаются на основе метаданных, определяемых в конфигурации. Метаданные регламентного задания содержат такую информацию как наименование, метод, использование и т.д.
Регламентное задание имеет расписание, которое определяет, в какие моменты времени нужно выполнять связанный с регламентным заданием метод. Расписание, как правило, задается в информационной базе, но может быть задано и на этапе конфигурирования (например, для предопределенных регламентных заданий).
Планировщик заданий используется для планирования выполнения регламентных заданий. Для каждого регламентного задания планировщик периодически проверяет, соответствует ли текущая дата и время расписанию регламентного задания. Если соответствует, планировщик назначает такое задание на выполнение. Для этого по данному регламентному заданию планировщик создает фоновое задание, которое и выполняет реальную обработку.
С описанием, думаю, хватит - приступим к реализации:
Создание регламентного задания
Имя метода – путь к процедуре, которая будет выполняться в фоновом задании по заданному расписанию. Процедура должна находиться в общем модуле. Рекомендуется не использовать типовые общие модули, а создать свой. Не забудьте, что фоновые задания исполняются на сервере!
Использование – признак использования регламентного задания.
Предопределенное – указывает, является ли регламентное задание предопределенным.
Если хотите что бы регламентное задание заработало сразу после помещения в БД, укажите признак Предопределенное. В противном случае вам необходимо будет использовать обработку “Консоль заданий” или вызывать запуск задания программно.
Количество повторов при аварийном завершении задания – сколько раз выполнен перезапуск фонового задания, если оно было выполнено с ошибкой.
Интервал повтора при аварийном завершении задания – с какой периодичностью будет выполнен перезапуск фонового задания, если оно было выполнено с ошибкой.
Особенности выполнения фоновых заданий файловом и клиент-серверном вариантах
Механизмы выполнения фоновых заданий в файловом и клиент-серверном вариантах различаются.
В файловом варианте необходимо создать выделенный клиентский процесс, который будет заниматься выполнением фоновых заданий. Для этого в клиентском процессе должна периодически вызываться функция глобального контекста ВыполнитьОбработкуЗаданий. Только один клиентский процесс на информационную базу должен выполнять обработку фоновых заданий (и, соответственно, вызывать данную функцию). Если клиентского процесса для обработки фоновых заданий не создано, то при программном доступе к механизму заданий будет выдана ошибка «Менеджер заданий не активен». Не рекомендуется клиентский процесс, выполняющий обработку фоновых заданий, использовать для других функций.
После того, как клиентский процесс, выполняющий обработку фоновых заданий, запущен, остальные клиентские процессы получают возможность программного доступа к механизму фоновых заданий, т.е. могут запускать и управлять фоновыми заданиями.
В клиент-серверном варианте для выполнения фоновых заданий используется планировщик заданий, который физически находится в менеджере кластера. Планировщик для всех поставленных в очередь на выполнение фоновых заданий получает наименее загруженный рабочий процесс и использует его для выполнения соответствующего фонового задания. Рабочий процесс выполняет задание и уведомляет планировщик о результатах выполнения.
В клиент-серверном варианте имеется возможность блокирования выполнения регламентных заданий. Блокирование выполнения регламентных заданий происходит в следующих случаях:
На информационную базу установлена явная блокировка регламентных заданий. Блокировка может быть установлена через консоль кластера;
На информационную базу установлена блокировка соединения. Блокировка может быть установлена через консоль кластера;
Из встроенного языка вызван метод УстановитьМонопольныйРежим() с параметром Истина;
В некоторых других случаях (например, при обновлении конфигурации базы данных).
Обработки запуска и просмотра регламентных заданий вы можете скачать здесь:
Недавно, мой постоянный клиент решил проводить маркетинговые исследования по изменению цен на товары у конкурентов... и эти данные захотел использовать в 1С в связке с его прайс-листом + куча отчетов с графиками и процентным отклонением от цен основного конкурента
В результате этого, была написана обработка собирающая данные со страниц разных сайтов. Из целей конфиденциальности - сайты раскрывать не буду...
Вид обработки загрузки данных с сайта в 1С
Ниже код загрузки данных со страницы сайта, смысл такой :
в функция передается адрес страницы сайта
полученный текст страницы обрабатывается, удаляются теги
из полученного текста формируется ТЗ с данными
По названию ищется поставщик из вспомогательного справочника Справочники.Pr_Поставщики.НайтиПоНаименованию(, если нет - создается
на выходе ТЗ с данными
В коде используется вспомогательная функция ПолучитьМассивИзСтрокиСРазделителем
Конечно, перед тем как мы начали это делать - прошерстили интернет и нашли несколько решений , вот они:
Чтобы не изменять типовую конфигурацию приходится использовать типовой механизм внешних печатных форм и обработок. Данный код проверяет - добавлена ли открываемая обработка в конфигурацию, если нет - задает вопрос и при положительном ответе - автоматически добавляет в конфигурацию:
Как известно, с помощью языка запросов 1С получить уникальный идентификатор объекта ссылочного типа на данный момент нельзя. Но используя возможность СКД обращаться к внешним функциям можно получить строковое представление уникального идентификатора ссылки. Для этого необходимо использовать глобальную функцию XMLСтрока в вычисляемых полях в макете схемы компоновки.
Далее проведем эксперимент по быстродействию получения результата через запрос с последующей обработкой выборки и вариантов с использованием СКД.
Рассмотрим два случая - вывод в табличный документ и формирование текстового документа.
Так же в случае с СКД мы можем создать схему компоновки программно или использовать готовую. Результат работы СКД так же можно обойти в цикле, либо вывести в таблицу значений с последующей обработкой. Для экспериментов будет использоваться платформа 8.3, конфигурация УТ11 (файловая), справочник "КлассификаторБанковРФ", более 4000 элементов.
Схему компоновки и макет можно посмотреть, скачав обработку (ссылка в конце).
По результатам замера производительности видно, что вывод результата в табличный документ происходит быстрее при использовании СКД, причем вариант с программным созданием схемы отрабатывает несколько быстрее.
В тоже время вывод результатов в текстовый документ отрабатывает быстрее для запроса.
Программное создание схемы компоновки отработало быстрее, чем получение макета схемы.
 Как уменьшить вес картинок в базе данных или изменить размер, ширину или высоту картинок?
Как уменьшить вес картинок в базе данных или изменить размер, ширину или высоту картинок? 


.gif) ) нужно поставить галку на
) нужно поставить галку на


 Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.
Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения. Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать, которое задано по умолчанию.







